Large dataset과 sparse, imbalanced data에서도 효율적으로 활용할 수 있는 PMF 모델을 소개하는 논문입니다.
[Abstract]
Collaborative filtering을 활용하는 다양한 접근법들은 큰 사이즈의 dataset과 평가 정보가 거의 존재하지 않는 사용자들은 다룰 수 없다는 단점이 있습니다. 해당 논문에서는 PMF(Probabilistic Matrix Factorization) model을 소개합니다. PMF는 관측값의 수에 따라서 linearly scale up을 할 수 있고, 더 중요하게는 large, sparse imbalanced한 Netflix dataset에서 매우 좋은 성능을 보입니다.
더 나아가 해당 논문에서는 유사한 영화에 평가를 한 사용자들은 유사한 선호로들 갖는 다는 가정을 전제로 한 constrained version PMF을 소개합니다. 최종 모델은 평가를 거의 하지 않는 사용자들을 대상으로도 일반화를 제대로 할 수 있었습니다.
1. Introduction
Collaborative filtering의 가장 유명한 방법 중 하나는 low-dimensional factor model을 기반으로 하고 있습니다. 해당 모델의 아이디어는 사용자의 행동과 선호도는 관측되지 않는 몇 개의 factor들로 결정된다는 것입니다. Linear factor model에서 사용자의 선호도는 item factor vector들의 선형 결합으로 모델링됩니다.
과거 연구들에서 probabilistic factor-based model의 변형들이 소개되었습니다. 이런 모델들은 숨거진 factor variable들이 사용자 평가를 나타내는 variable과 직접적인 연관이 있는 graphical model로 볼 수 있습니다. 이런 모델들의 주된 단점은 정확한 추론이 어렵다는 점입니다. 즉, 이러한 모델의 hidden factor의 posterior distribution을 계산하기 위해 slow or inaccurate 근사치가 필요하다는 것입니다.
Sum-squared distance를 최소화를 바탕에 둔 low-rank approximation은 SVD를 생각해볼 수 있습니다.
Approximation 행렬의 rank를 제한하는 것 대신에 과거 연구 중 하나는 user 행렬 U와 factor 행렬 V의 norm을 penalizing하는 것을 제안했습니다.
Collaborative filtering을 활용한 많은 모델들을 통해 Netflix dataset에 적용해보고자 했지만 2가지 이유로 인해 좋은 결과를 얻지 못했습니다. 첫째, matrix-factorization-based model을 제외하고서는 그 어떠한 모델도 larget dataset에 scale up을 제대로 할 수 없었습니다. 둘째, 기존에 존재하던 대부분의 알고리즘들은 평가를 거의하지 않는 사용자들은 제대로 예측할 수 없었습니다. Collaborative filtering을 다루는 community의 일반적인 문제는 특정 개수 이하의 평가를 남긴 사용자들은 제거하기 때문입니다. 그렇기에 data 크기가 크고, 평가를 남기지 않은 사용자가 많은 neflix dataset에서는 좋은 결과를 얻을 수 없던 것 입니다.
해당 논문의 목표는 관측치의 개수에 따라 linearly scale up을 할 수 있고, sparse and imbalanced dataset에도 적용할 수 있는 probabilistic 알고리즘을 소개하는 것입니다.
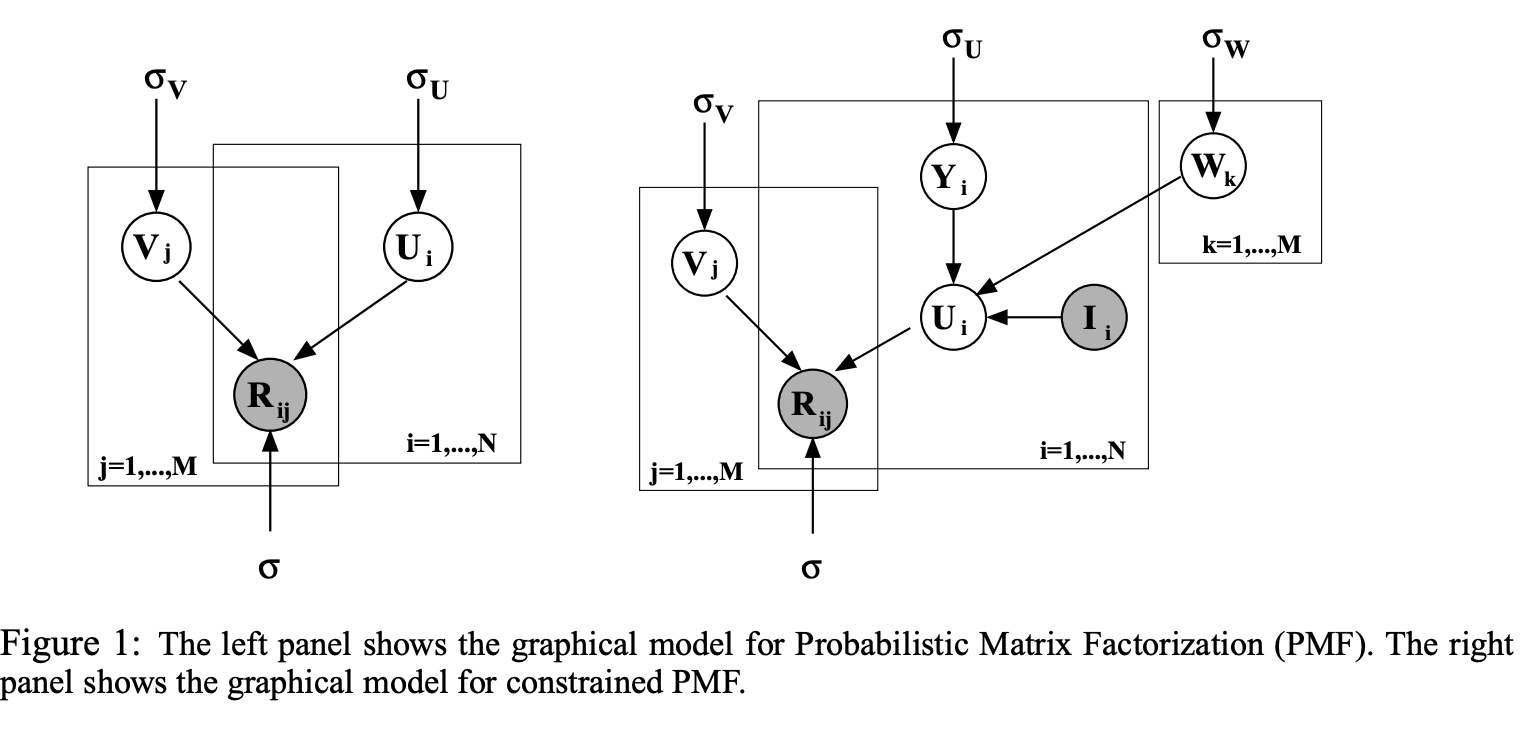
2. Probabilistic Matrix Factorization(PMF)
- M : 영화 개수
- N : 사용자 수
- 평가 점수 : 1 ~ K
- R_ij : 사용자 i가 영화 j에 평가한 점수
- U (DxN) : 사용자 feature matrix
- V (DXM) : 영화 feature matrix


식(4)의 local minimum은 U와 V에 gradient descent를 적용하여 찾을 수 있습니다.
해당 모델은 SVD model의 probabilistic extension으로 볼 수 있습니다.

3. Automatic Complexity Control for PMF Models
PMF model이 일반화가 잘 될 수 있도록하기 위해서 capacity control은 필수적입니다. 충분히 많은 factor들이 주어진다면, PMF model은 어떠한 주어진 행렬이라도 잘 근사할 수 있습니다. PMF model의 capacity control을 할 수 있는 단순한 방법은 feature vector의 차원수를 바꿔주는 것입니다.
위에서 정의한 regularization parameter들을 조절하는 것이 더욱 유연하게 regularization을 수행할 수 있는 방법입니다. 적절한 parameter값을 찾는 가장 쉬운 방법은 parameter 값이 될 수 있는 집합을 먼저 만든 뒤 train data와 validate data를 활용하여 결정하는 것입니다. 이 방법은 하나의 모델만 학습하는 것이 아닌 여러 개의 모델을 학습하여 비교하기 때문에 계산 비용이 많이 든다는 단점이 있습니다.

4. Constrained PMF
PMF model이 fitting이 되면, 평가를 거의 하지 않은 user들은 prior mean이나 다른 사용자들의 평균과 근접한 feature vector를 갖게 됩니다. 그 결과 평가를 거의 하지 않는 user들의 예측 평가 값은 영화 평균점수와 유사해집니다. 이러한 사용자들을 제대로 다루기 위하여 추가적인 user-specific feature vector를 constrain하는 방법을 소개합니다.


5. Experimental
5.1 Description of the Neflix Data
5.2 Details of Training
- mini batch size : 100,000
- learning rate : 0.005
- momentum : 0.9
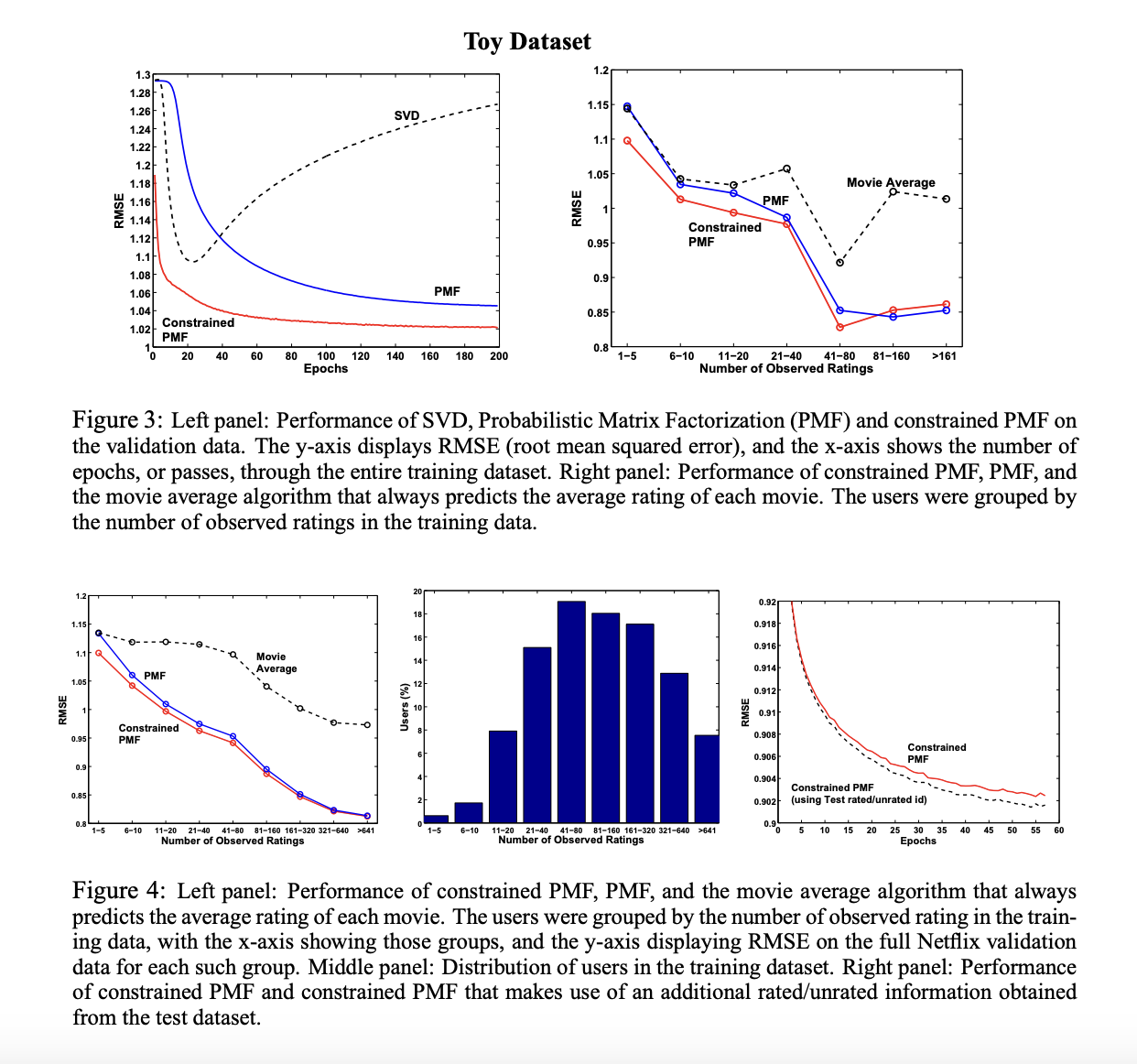
5.3 Results for PMF with Adaptive Priors

5.4 Results for Constrained PMF
6. Summary and Discussion
해당 논문에서는 PMF와 2가지 변형(PMF with a learnable prior / constrained PMF)를 소개했습니다. PMF를 활용하여 매우 큰 dataset에 성공적으로 적용하고 효율적으로 학습할 수 있었습니다.
PMF model 학습의 효율성은 model parameter와 hyperparameter의 point estimate를 찾는 것에서 얻을 수 있었습니다.
