Discourse vector(주제 벡터)를 활용하여 sentence embedding을 unsupervised하게 구하는 방법을 소개하는 논문입니다. Sentence embedding은 단순 평균이 아닌 문장 내 단어들의 가중 평균으로 볼 수 있습니다.
[Abstract]
신경망을 활용한 word embedding의 성공은 문장, 문단과 같은 길이가 긴 text의 semantic embedding에 영감이 되었습니다.
해당 논문에서는 최근의 연구를 넘어서 매우 좋은 성능의 baseline 역할을 할 수 있는 unsupervised sentence embedding을 소개합니다. 해당 방법은 Wikipedia와 같은 unlabeled corpus에 널리 알려진 word embedding 방법을 적용한 vector를 활용하고, 이 vector들의 가중 평균으로 문장을 표현합니다. 이처럼 단순하게 보이는 방법이더라도 앞으로는 labeling이 되어 있지 않거나 거의 되어 있지 않은 학습 dataset만이 존재할 때 baseline의 역할로 무궁무진하게 사용할 수 있을 것입니다.
해당 논문은 또한 앞서 언급한 unsupervised 방법이 성공한 이유의 이론적인 설명을 제공합니다.
1. Introduction
다양한 방법을 활용하여 계산된 word embedding은 NLP분야와 IR(정보검색)분야의 기틀이 되고 있습니다. 최근에는 word 수준을 넘어 문장, 문단과 같은 word sequence 수준의 의미를 표현할 수 있는 embedding을 계산하기 위하여 word vector를 단순하게 더하는 것뿐만 아니라 CNN, RNN과 같은 신경망을 활용하기도 합니다.
해당 논문에서는 매우 단순한 sentence embedding 방법을 제안합니다. 해당 방법은 문장 내에 있는 word vector들을 가중평균을 한 후 평균 vector의 first singular vector로의 projection을 빼주는 common component removal을 수행합니다. 단어 w의 가중치는 a/(a+p(w))로 표현할 수 있으며, a는 parameter이고 p(w)는 (estimated) word frequency입니다. 이런 가중치는 SIF(smooth inverse frequency)라고 합니다.
SIF 가중치는 sentence를 document라고 생각하고, 문장이 반복되는 단어를 포함하지 않는다고 가정한다면 TF/IDF와 매우 유사하다는 것을 느낄 수 있습니다. 이러한 reweighting(사전으로부터 자주 등장하는 단어를 제거하는 방식)은 매우 좋은 방식이지만 word embedding setting에서 이론적인 정당성을 설명한 적은 한 번도 없습니다.
해당 논문에서는 Arora et al 2016에서 소개한 text 생성을 위한 Random Walk on Discourses model의 수정된 버전 모델인 문장 생성모델을 활용하여 reweighting의 이론적 정당성을 설명합니다. Arora et al 2016 논문에서는 sentence embedding을 문장에 등장하는 word vector들의 단순평균으로 구합니다.
해당 논문에서는 Arora et al 2016에서 소개된 모델을 실질적으로 관측되는 사실인 단어는 때때로 document의 문맥 밖에서도 등장할 수 있다는 것을 반영할 수 있도록 수정하였습니다. 이는 대부분의 word embedding 방법의 실질적 특성을 반영하여 수정하였습니다. word embedding은 vector inner product를 활용하여 동시에 등장하는 단어의 확률을 찾아내려고 하기 때문에, 자중 등장하는 단어에 더욱 큰 vector 값을 줌과 동시에 단어 쌍에 필요 이상으로 큰 값을 줍니다.
흥미롭게도, 이론적으로 도출된 SIF는 전통적인 TF/IDF보다 좋은 성능을 보였습니다. 또한 해당 논문에서는 일반적인 통념과는 반대로 CBOW가 word vector의 단순 평균을 사용하지 않는 다는 것을 보였습니다.
2. Related Work
Word embedding
Word embedding은 단어의 어휘적, 의미적 특성을 가진 채로 낮은 차원의 공감으로 continuous한 값을 갖는 vector로 표현하는 방법입니다. Word embedding은 신경망을 활용하거나 co-occurrence statistics를 low rank approximation을 적용하여 얻을 수 있습니다.
Phrase/Sentence/Paragraph embeddings
과거 연구들에서는 phrase나 sentence embedding을 word embedding을 vector나 행렬 연산에 활용하여 얻었습니다.
3. A simple method for sentence embedding
Arora et al 2016에서 소개된 latent variable generative model을 되뇌어봅니다. 이 모델은 corpus generation을 step t에서 t번째 단어를 만들어내는 dynamic process로써 처리했습니다. 이 process는 discourse vector c_t(d 차원)의 random walk로부터 만들어졌습니다. 단어 w 역시 d 차원의 vector 공간에 있습니다. Discourse vector는 '말하고자 하는 바'로 표현할 수 있습니다. 즉, 주제벡터 정도라고 생각할 수 있습니다. discourse vector c_t와 단어 w의 vector v_w의 inner product는 단어와 주제의 연관성을 잡아냅니다. Time t에 단어 w가 등장할 확률은 log-linear word production model로부터 구할 수 있으며 아래와 같은 식을 얻을 수 있습니다.
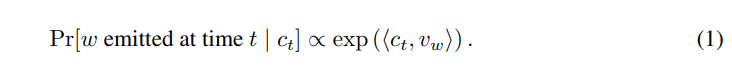
Discourse vector ct는 slow random walk(c(t+1)은 c_t에 samll random displacement vector를 더해 얻어집니다)이기 때문에 근접한 단어들은 유사한 discourse로부터 얻어진 것이라고 볼 수 있습니다. Random walk 모델은 c_t에 때때로 big step을 추가함으로써 완화시킬 수 있습니다. 이러한 단순한 연산은 단어의 cooccurrence 확률에는 아주 미미한 영향을 미치기 때문에 적용해도 큰 문제가 되지 않습니다.
Our improved Random Walk model
문장이 주어졌을 때, discourse vector의 MAP estimator가 sentence embedding이 되도록 합니다. 해당 논문에서는 문장 안의 단어 하나를 빼더라도 discourse vector c_t는 크게 변하지 않을 것이라고 가정하며, 문장의 모든 c_t들을 하나의 discourse vector c_s로 단순히 바꿀 수 있다고 가정합니다. Arora et al 2016에서 c_s의 MAP estimate는 문장의 단어들의 embedding의 평균과 동일하다는 것을 보였습니다.
해당 논문에서는 좀 더 현실적인 모델링을 위하여 (1) 모델을 다음과 같이 변경합니다. 모델은 2개의 'smoothing term'을 갖습니다. 이는 몇몇 단어들은 문맥 밖에서 등장할 수 있고, 빈도가 높은 단어(ex. the, and)들은 discourse(주제)와 관련 없이 등장할 수 있다는 것을 의미합니다.
- ap(w) : a는 scalar이며 p(w)는 단어의 unigram probability -> 이 term은 단어가 c_s와 inner product 값이 작더라도 등장할 수 있도록 해줍니다.
- c_0 : d차원 common discourse vector, 문법과 관련이 있는 가장 자주 등장하는 discourse의 correction term 역할을 합니다. -> 단어의 co-occurrence 확률을 c_0와 관련이 있도록 합니다.

위 모델을 통해서 단어 w는 discourse c_s와 관련이 없더라도 2가지 이유로 등장할 수 있도록 해줍니다. 첫째, ap(w) term에 의해 둘째, w가 common vector c_o와 관련이 있기 때문입니다.
Computing the sentence embedding
Sentence embedding은 vector c_s의 MLE로 정의할 수 있습니다.(Prior가 uniform일 때 MLE는 MAP와 동일합니다) 해당 논문에서는 Arora et al 2016의 주된 가정을 차용합니다.


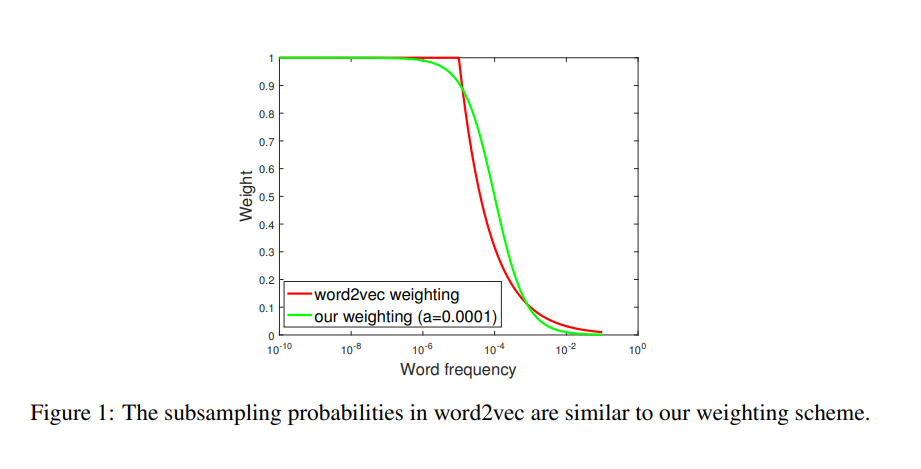
3.1 Connection to subsampling probabilities in word2vec
Word2vec은 단어 w의 marginal probability인 p(w)값을 활용하여 1/sqrt(p(w))만큼의 확률로 단어 w를 downsampling합니다. 이는 학습 속도를 빠르게 해주는 것뿐만 아니라 regular word representation을 학습할 수 있도록 해줍니다.

4. Experiments
4.1 Textual Similarity Tasks
datasets
Task의 목적은 두 문장 사이의 유사성을 측정하는 것입니다. 평가지표는 측정치와 실제 유사도 사이의 Pearson correlation을 활용합니다.
Experimental settings
- Unsupervised : ST(Skip-thought vectors) / avg-Glove(Glove vector의 단순 평균) / tfidf-Glove(TF-IDF값을 가중치로 하는 Glove vector의 가중평균)
- Semi-supervised : avg-PSL(PARAGRAM-SL999 word vector의 단순평균)
- Supervised(모든 방법들은 PSL word vector trained on PPDB dataset로 initalized) : PP(Arora et al 2016에서 제안, word vector의 평균) / PP-proj(Arora et al 2016에서 제안, PP에 linear projection 추가) / DAN(deep averaging network) / RNN / iRNN(RNN with activation being the identity) / LSTM(o.g) (with output gates) / LSTM(no) (without output gates)
- 해당 논문의 방법 : 각 방법 이름 뒤에 +WR 추가 -> Glove+WR(Glove vector에 해당 논문의 방법 적용) / PSL+WR(PSL vector에 해당 논문의 방법 적용)
Results
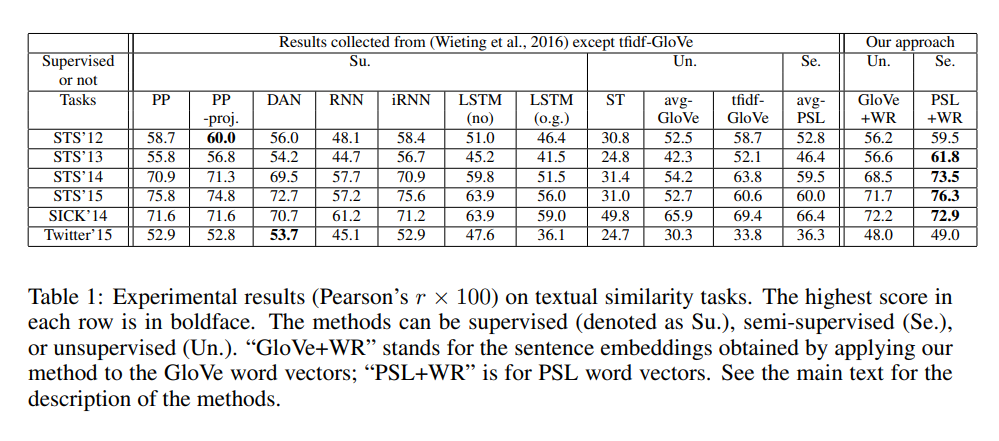
Dataset의 top singular vector c_0는 문법 정보 혹은 자주 등장하는 단어와 관련이 있다는 것을 알아냈습니다. SICK dataset에서 c_0와 가장 근접한 단어들은 just, when, even, one, up, way, but, while,there와 같은 단어들이었습니다.
4.1.1 Effect of weighting parameter on performance
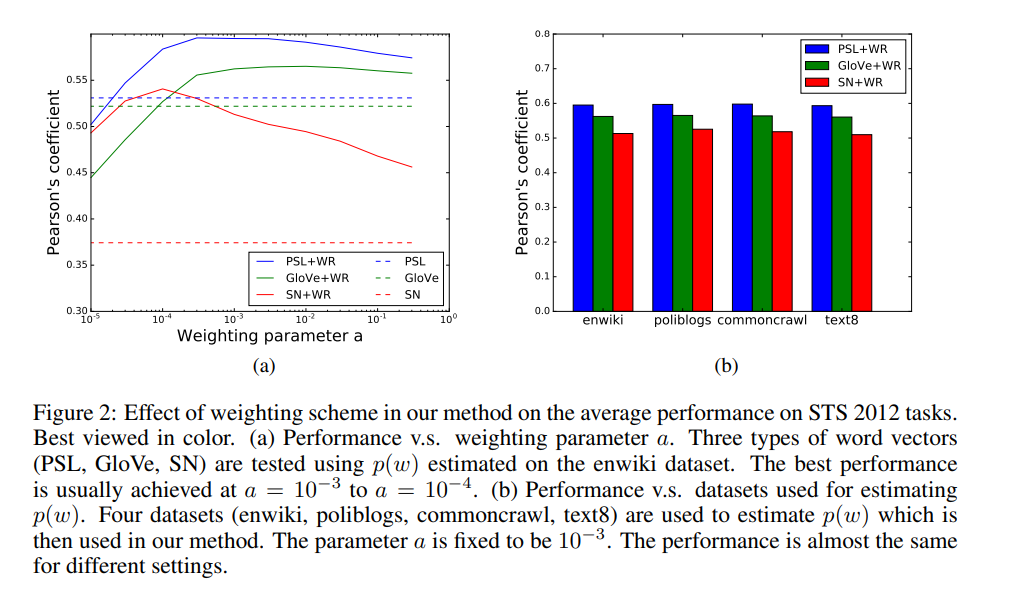
4.2 Supervised tasks
Unsupervised하게 학습된 sentence embedding vector의 효과를 강조하기 위하여 embedding은 고정시킨 채 classifier만 학습하였습니다.
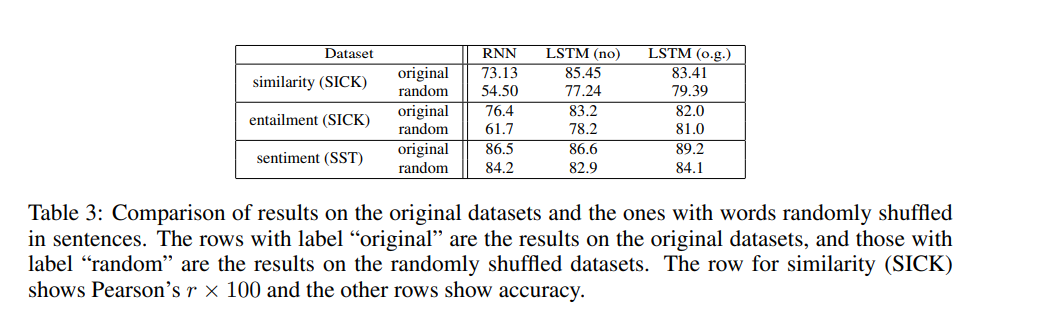
4.3 The effect of the order of words in sentences
해당 논문에서 소개한 방식의 가장 흥미로운 특징은 단어의 순서를 무시한다는 점입니다.
5. Conclusions
해당 논문에서는 Arora et al 2016에서 제안된 random walk model for generating text의 discourse vector를 활용한 sentence embedding 방법을 소개하였습니다. Unsupervised 방식을 활용하면서 매우 단순하지만 textual similarity task에서 매우 좋은 성능을 보였습니다. 심지어 RNN, LSTM을 활용한 모델보다도 좋은 성능을 보였습니다.
