딥러닝 학습을 효율적으로 할 수 있는 가중치 초기화 방식은 LSUV를 소개하는 논문입니다.
[Abstract]
해당 논문에서는 deep net learning을 위한 가중치 초기화의 단순한 방법인 LSUV(Layer-sequential unit-variance)를 제안합니다. 해당 방법은 2단계로 이루어졌습니다. 첫째, convolution 또는 inner-product layer마다 orthonormal 행렬을 활용하여 pre-initialize weight를 얻습니다. 둘째, 각 layer의 output 분산을 1이 되도록 normalizing을 합니다.
1. Introduction
Deep nets는 많은 computer vision과 natural language processig에서 좋은 결과를 보였습니다.
매우 깊은 deep nets를 방해하는 주된 장애물 중 하나는 end-to-end 학습에 있어서 일반화하고, 재현가능하고, 효율적인 과정이 없다는 점입니다. 과거 연구에서는 deep and thin networks는 5층 이상일 경우 uniform initialization을 활용하여 backpropagation을 통해 학습하는 것이 어렵다고 밝혔습니다.
He(2015)에서 만약 ReLU-aware initialization으로 network weight를 초기화한다면 sing optimization으로 VGGNet을 학습할 수 있다고 보였습니다. He(2015) 과정에서 ReLU non-linearity로 일반화하였습니다. Batch마다 output을 평균 0, 분산 1로 변환하는 layer를 삽입하는 기술인 batch normalization은 GoogLeNet 22개의 layer를 효율적으로 학습할 수 있도록 해주었습니다. 하지만 batch normalization은 각 반복마다 30%의 연산량 증가가 있다는 단점이 있습니다.
해당 논문의 주된 기여는 SGD와 함께 활용하여 SOTA 성능을 보이는 단순한 initialization을 소개합니다. 결과는 very deep nets에서 initialization의 중요성을 강조합니다.
2. Initialization in Neural Networks
Glorot & Bengio(2010)에서 layer들 사이 linearity 가정하에서 layer들의 input, output channel 수의 표준편차를 추정하는 공식을 제안하였습니다. Glorot initialization은 다양하게 적용되었습니다. He(2015)에서 위 공식을 ReLU non-linearity로 확장하였고 ReLU 기반의 net에서 가장 좋은 성능을 갖는다는 점을 보였습니다.
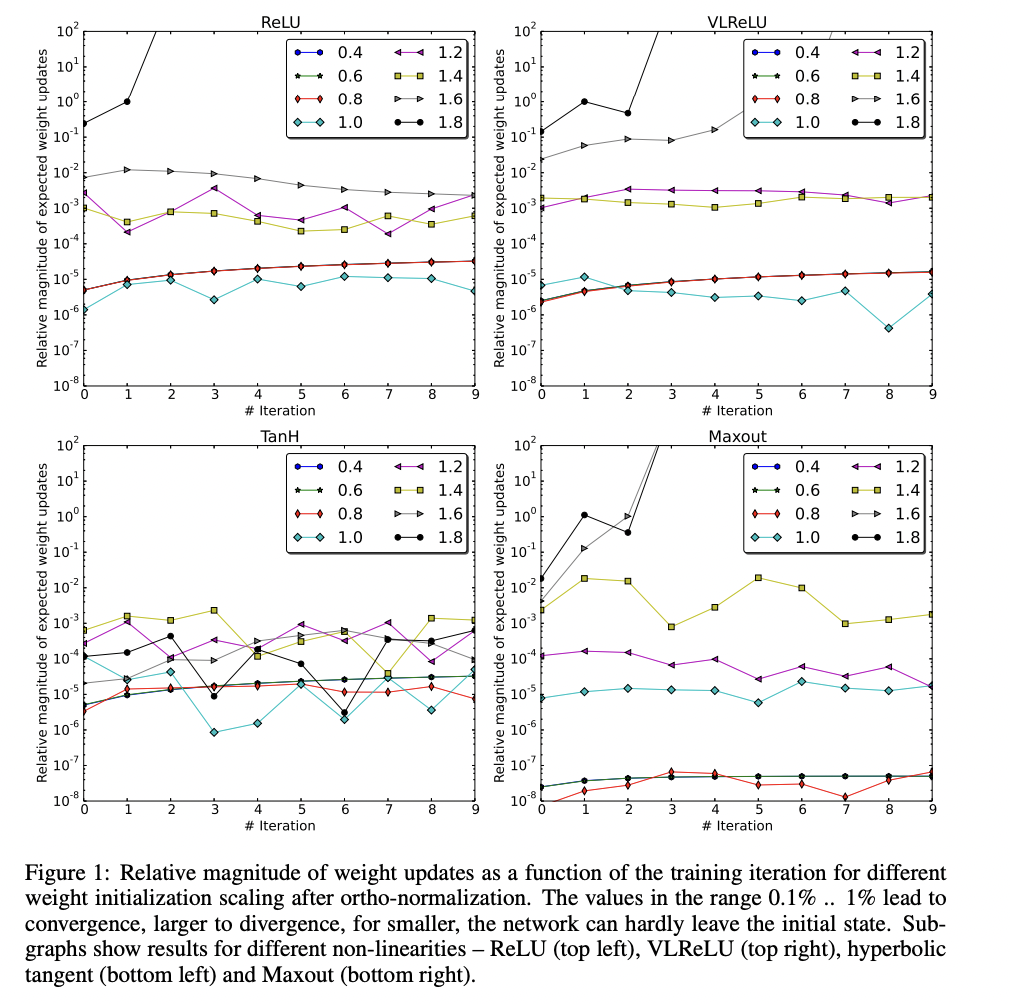
큰 가중치는 initial value일때보다 갱신을 할 때 divergence를 만들었고, 작은 가중치는 학습 반복마다 신경망의 학습이 매우 작게 이루어지도록 합니다.
Sussillo & Abbott(2014)에서 RWI(Random walk initializaion)을 제안하였습니다.
Hinton(2014)와 Romero(2015)에서 initializaion의 새로운 접근법을 제안하였고, teacher nework prediction을 흉내내는 방식을 만들었습니다.
Srivastava(2015)는 LSTM-inspired gating 방법을 제안하였습니다.
Saxe(2014)는 orthonormal matrix initialization이 Gaussian noise보다 더 나은 성능을 보이는 것을 밝혔습니다.
3. Layer-sequential Unit-Variance Initialization
Glorot & Bengio(2010) 방식을 ReLU 이외의 tanh, maxout과 같은 다른 non-linearity까지 확장하는 시도가 없었습니다. 또한 해당 방식은 max-pooling, local normalization layer와 activation variance에 영향을 미치는 다른 종류의 layer까지는 커버하지 않습니다. 해당 논문에서는 data-driven weights initalization을 소개합니다.
해당 논문에서는 Saxe(2014)가 제안한 orthonormal initialization을 iterative procedure로 확장하였습니다. Saxe(2014)는 2단계로 수행하였습니다. 첫째, 가중치는 분산 1인 Gaussian noise로 채워집니다. 둘째, 해당 가중치들을 QR 또는 SVD-decomposition을 활용하여 orthonormal basis로 분해하고 가중치를 대체합니다.
LSUV는 각 convolution과 inner product layer의 output 분산을 추정하고 weight의 분산이 1이되도록 weight를 조절합니다.
제안된 방법은 first mini-batch에만 batch normalization을 수행하는 것이 결합된 orthonormal initialization으로 볼 수 있습니다. Batch normalization과 분산을 1로 만든다는 점에서 공통점이 있지만, weight 행렬의 ortho-normalization은 layer activation을 효율적으로 de-correlate를 수행합니다.
LSUV는 아래 Algorithm1로 요약됩니다.

Input과 output에 normalizing은 standard feed-forward net에서 동일하지만 maxout을 사용하거나 input으로 multiple layer의 output을 사용하는 network에서는 normalizing input이 좀 더 복잡합니다.
4. Experimental Validation

4.1 MNIST

4.2 CIFAR-10/100
5. Analysis of Empirical Results
5.1 Initialization Startegies and Non-linearities



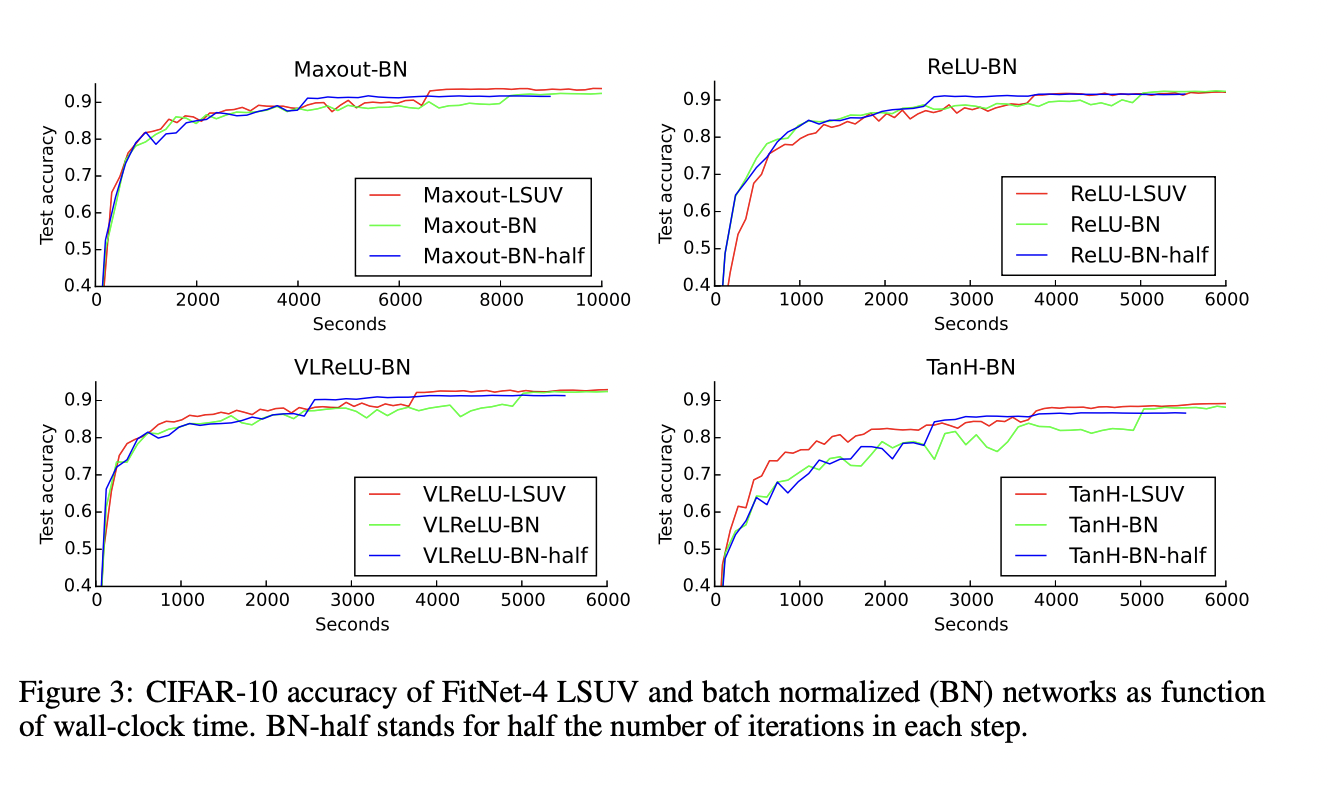
5.2 Comparison to Batch Normalization(BN)
LSUV는 학습 시작 전에 수행되는 layer output의 batch normalization으로 볼 수 있습니다.
5.2.1 Where to put BN - Before or After Non-linearity?
Batch-normalization을 non-linearity 뒤에 두는 것이 성능이 더 좋습니다.

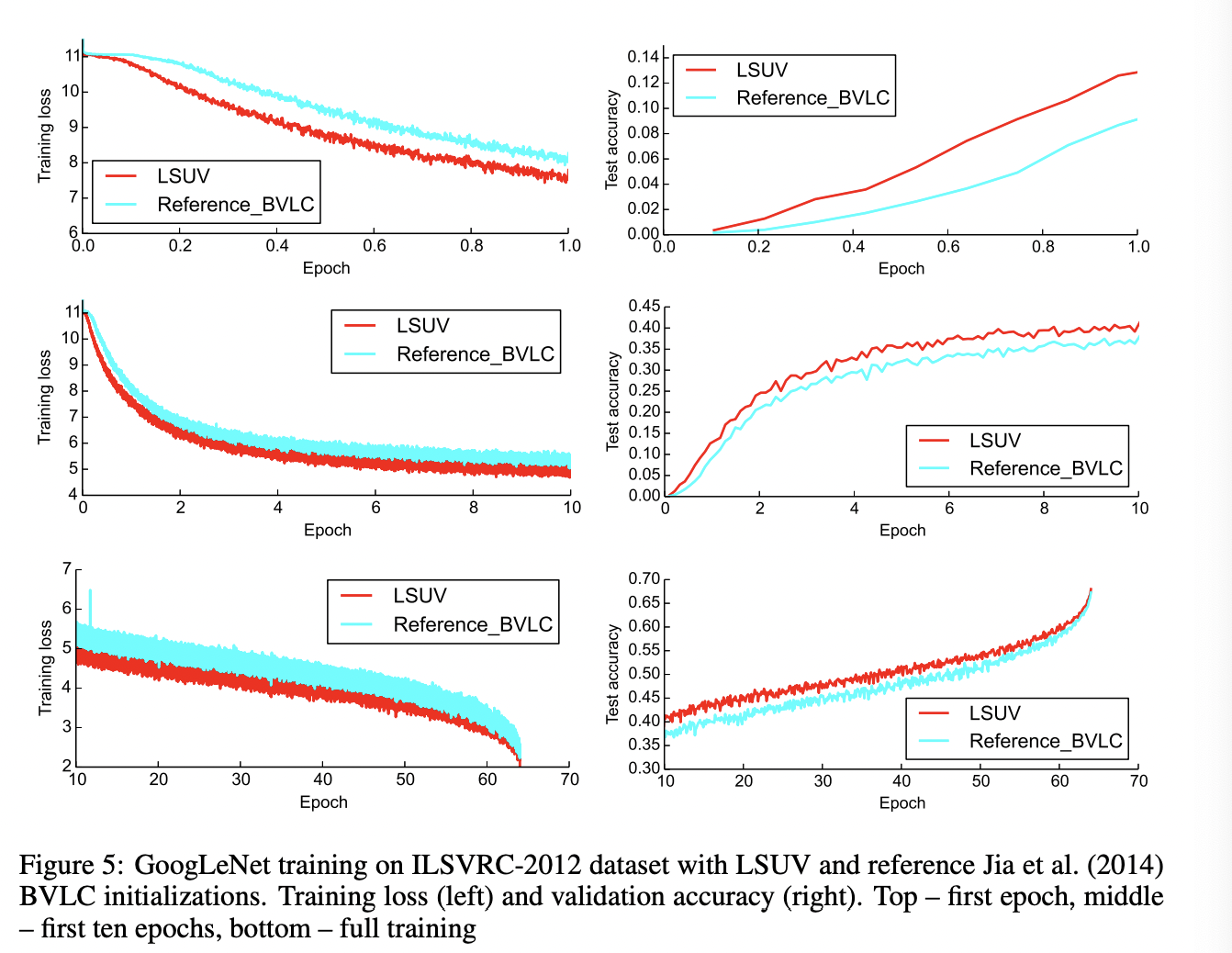
5.3 Imagenet Training

5.4 Timings

6. Conclusions
해당 논문에서는 LSUV(Layer Sequential Uniform Variance)라고 불리는 deep net learning의 단순한 가중치 초기화 전략을 제안합니다. LSUV는 다양한 activation function에 대해서도 잘 적용되었습니다.
