데이터베이스
JDBC
자바에서 데이터베이스에 접속할 수 있도록 하는 자바 API
이를 통해 DBMS의 종류에 관계 없이 데이터베이스를 연결하고 작업을 처리할 수 있다.
단일키, 복합키, index
https://prohannah.tistory.com/175
join 연산 속도
조인 연산 알고리즘
- Neested Loops Join
- Hash Join
- Sort Merge Join
어떤 알고리즘을 사용할지는 데이터 크기, 결합키(Key), 인덱스와 같은 요인에 따라 옵티마이저가 결정
*옵티마이저(Optimizer): 여러 결과 도출 방법 중 가장 성능이 좋은 계획을 선택해주는 도구
구동 테이블(Driving Table)이 작을수록, 내부 테이블(Inner Table)의 결합키 필드에 인덱스가 존재하는 경우 가장 성능을 높일 수 있다.
구동테이블: 조인이 진행될 때 먼저 액세스되어 Access Path를 주도하는 테이블. 즉, 주도적으로 다른 테이블의 결합키에 다가가서 매칭을 시도하는 테이블
내부테이블: 구동테이블의 대상이 되는 테이블
인덱스: 검색 시 레코드를 Full Scan하지 않고 색인화되어 있는 INDEX 파일을 검색해 검색 속도를 빠르게 해준다.
조인은 실행계획에 변동이 일어나기 가장 쉬운 연산이다. 조인을 대체할 수 있는 다른 수단을 잘 활용하는 것이 좋다.
ex) 윈도우 함수
더 자세한 정보) https://schatz37.tistory.com/2
select 조회 시 칼럼이 많은 데이터가 효율적일까, 로우가 많은 데이터가 효율적일까?
실행계획, 옵티마이저
옵티마이저는 사용자가 질의한 SQL문에 대해 최적의 실행 방법을 결정하는 역할 수행한다. 이러한 최적의 실행 방법을 실행계획(Execution Plan)이라고 한다.
옵티마이저
- 규칙기반 옵티마이저(RBO, Rule Based Optimizer)
- 비용기반 옵티마이저(CBO, Cost Based Optimizer)
실행계획
- 조인 순서
- 조인 기법
- 액세스 기법
- 최적화 정보
- 연산
복제(Replication)
두 개 이상의 DBMS를 이용해 Master/Slave의 수직적 구조를 활용해 DB의 부하를 분산시키는 기술
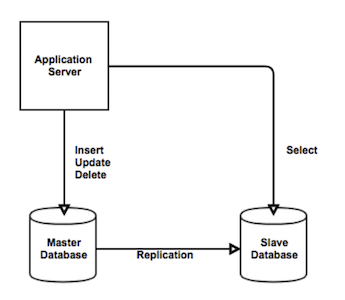 출처: https://nesoy.github.io/articles/2018-02/Database-Replication
출처: https://nesoy.github.io/articles/2018-02/Database-Replication
- Master DB에는 Insert, Update, Delete 작업 수행
- Slave DB는 Select 작업 수행
- Select 작업이 시간이 많이 걸리기 때문에 따로 뺀다.
장점
- Select 성능 향상
- 데이터 백업
단점
- 데이터 정합성을 보장할 수 없음
- Binary Log File 관리
- Master는 Binary Log가 무분별하게 쌓이는 걸 막기 위해 데이터 보관 주기를 설정하지만 Master는 Slave까지 관리하지는 않기 때문에 Master에서 Binary Log File을 삭제했다고 해서 Slave에서 Binary Log가 삭제되지는 않음
- Fail Over 불가
- Master에서 에러가 발생한 경우 Slave로 Fail Over하는 기능을 지원하지 않는다. Slave 역시 Master와 Log 위치가 다르면 관리자가 작업해야 한다.
더 자세한 내용) https://velog.io/@zpswl45/DB-Replication-개념-정리
파티셔닝/샤딩
파티셔닝(Partitioning)
데이터베이스를 여러 부분으로 분하라는 것
VLDB(Very large DBMS)와 같이 하나의 DBMS에 너무 큰 테이블이 들어가면서 용량과 성능 측면에서 많은 이슈가 발생할 때 파티셔닝 기법을 이용해 해결할 수 있다.
즉, 큰 테이블이나 인덱스를 작은 팦티션 단위로 나누어 관리하는 것
데이터가 너무 커져서 조회하는 시간이 길어질 때 또는 관리 용이성, 성능, 가용성 등의 이유로 사용된다.
장점
- 성능(Performance)
- 특정 쿼리의 성능을 향상
- 대용량 Data Write 환경에서 효율적
- 필요한 데이터만 빠르게 조회 가능
- Full Scan에서 데이터 접근의 범위를 줄임으로써 성능 향상
- 가용성(Availability)
- 물리적인 파티셔닝으로 전체 데이터의 훼손 가능성이 줄고 데이터 가용성 향상
- 파티션 별로 독립적인 백업과 복구 가능
- 파티션 단위로 Disk I/O를 분산해 경합을 줄이므로 Update 성능 향상
- 관리용이성(Manageability)
단점
- 테이블 간 Join 비용 증가
- 테이블과 인덱스를 별도로 파티셔닝할 수 없으므로 테이블과 인덱스를 같이 파티셔닝해야 한다.
종류
- 수평 파티셔닝(Horizontal Partitioning)
- 수쥑 파티셔닝(Vertical Partitioning)
범위
- 범위 분할(range partitioning)
- 목록 분할(list partitioning)
- 해시 분할(hash partitioning)
- 합성 분할(composite partitioning)
샤딩(Sharding)
같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 기법
같은 데이터베이스 내에서 하나의 큰 테이블을 쪼개 저장하는 수평 파티셔닝과 달리
샤딩은 하나의 큰 테이블을 쪼개 각각 다른 데이터베이스에 분산 저장하는 기법이다.
샤딩은 수평 파티셔닝의 장점을 모두 갖는다.
장점
- 데이터의 개수를 기준으로 나눠 파티셔닝 한다.
- 데이터의 개수와 인덱스의 개수가 줄어 성능이 향상된다.
단점
- 데이터베이스 서버 간의 연결 과정이 많아져 비용이 증가할 수 있다.
- 하나의 서버가 고장나면 데이터의 무결성이 깨질 수 있다.
ERD(Entity Relationship Diagram)
개체-관계 모델로, 테이블 간의 관계를 설명해주는 다이어그램이다.
즉, API를 효율적으로 뽑아내기 위한 모델 구조도
Ref)
https://velog.io/@fud904/DB-옵티마이저와-실행계획
https://velog.io/@zpswl45/DB-Replication-개념-정리
https://code-lab1.tistory.com/202
https://velog.io/@kjhxxxx/DataBase-ERD란
