데이터베이스
교착상태(Dead Lock)
두 개 이상의 트랜잭션이 특정 자원의 Lock을 획득한 채 다른 트랜잭션이 소유하고 있는 잠금을 요구하면 아무리 기다려도 상황이 바뀌지 않는 상태가 되는데 이를 교착상태라고 한다. 즉, 여러 개의 트랜잭션들이 실행되지 못하고 서로 무한적 기다리고 있는 상태
오라클의 경우, 데드락을 감지하면 한쪽 Transaction을 풀어버린다.
데드락 빈도 낮추는 방법
- 트랜잭션을 자주 커밋
- 정해진 순서로 테이블에 접근
- 읽기 잠금 획득(SELECT ~ FOR UPDATE)의 사용을 피한다.
- 한 단위의 복수 행을 복수에 연결해서 순서 없이 갱신하면 교착 상태가 발생하기 쉽다. 이 경우에는 테이블의 잠금을 획득해 갱신을 직렬화하면 동시성이 떨어지지만 교착 상태를 피할 수 있다.
- Index 설계 (Update시 Index를 타지 않으면 테이블 전체에 Lock이 걸릴 수 있다.)
- 고립 수준을 낮춘다. (서비스 검토 필요)
해결 방안
https://jaehoney.tistory.com/162
JOIN
둘 이상의 테이블을 연결해서 데이터를 검색하는 방법
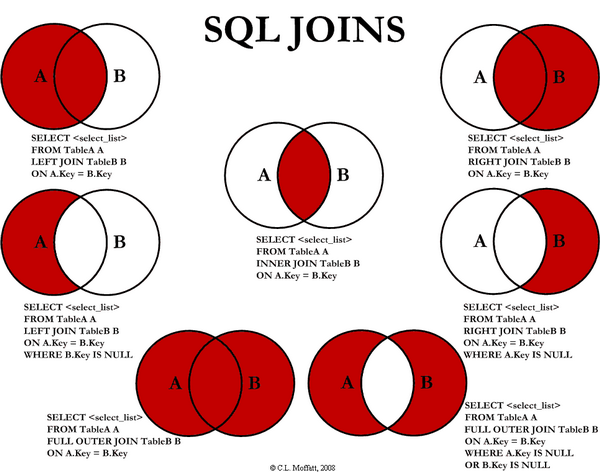
- INNER JOIN: 내부 조인(교집합)
- LEFT/RIGHT JOIN: 부분 집합
- OUTER JOIN: 외부 조인(합집합)
- 인덱스를 활용하면, 조인 연산의 비용을 극적으로 낮출 수 있다.
SQL Injection(SQL 삽입 공격)
보안 상의 취약점을 이용해 임의의 SQL 문을 주입하고 실행되게 함으로써 데이터베이스가 비정상적인 행동을 하도록 조작하는 행위
인젝션 공격은 OWASP Top10 중 첫 번째에 속해 있으며, 공격이 비교적 쉬운 편이고 공격에 성공할 경우 큰 피해를 입힐 수 있는 공격이다.
인증 우회, 시스템 명령어 삽입, 입쉘 생성 등이 있다.
2017년 3월에 일어난 "여기어때"의 대규모 개인정보 유출 사건도 SQL Injection으로 인해 피해 발생
공격 종류 및 방법
- Error based SQL Injection
- UNION based SQL Injection
- Blind SQL Injection(1)
- Blind SQL Injection(2)
- Stored Procedure SQL Injection
- Mass SQL Injection
대응 방안
- 입력 값에 대한 검증
- Prepared Statement 구문 사용
- Error message 노출 금지
- 웹 방화벽 사용
Statement, PrepareStatement
자바에서 DB로 쿼리문을 전송할 때, 2가지 인터페이스를 사용할 수 있다.
Statement와 PreparedStatement이다.
DBMS 쿼리 실행 절차
1. Parsing (Query의 문법적, 의미적 오류 체크, 재사용 가능 SQL 확인, 쿼리실행계획 수립 등)
2. Execution (쿼리를 실행한다.)
3. Fetch(실행된 값을 가져오는 절차이므로 Select 만 해당됨. 반환하는 값이 없는 Insert, Update, Delete는 미해당.)Statement
- Statement 인터페이스를 구현한 객체를 Connection 클래스의 createStatement() 메소드를 호출함으로써 얻어진다.
- Statement 객체가 생성되면 executeQuery() 메소드를 호출해 SQL 문을실행시킬 수 있다.메소드의 인수로 SQL문을 담은 String 객체를 전달한다.
- Statement는 정적인 쿼리문을 처리할 수 있으므로, 쿼리문에 값이 미리 입력되어 있어야 한다.
장점
- 테이블, 칼럼에 대한 동적 쿼리 작성이 가능하다. 즉, DDL 작성에 적합하다.
- 쿼리 실행문을 직접 확인 가능하므로 쿼리 분석이 쉽다.
단점
- 1번 처리 구간을 매 요청마다 실행하므로 Query 처리비용이 많이 든다. 즉, 캐시 처리를 못한다.
- SQL Injection으로 인한 공격에 노출된다.
- ex) 비밀번호를 확인하는 Where 구문의 변수 부분에 '1234 OR 1 = 1' 같은 구문을 끼워넣을 경우 항상 참이 되므로 악용이 가능하다.
PreparedStatement
- Connection 객체의 preparedStatement() 메소드를 이용해 생성한다. 인수로 SQL문을 담은 String 객체가 필요하다.
- SQL 문장이 미리 컴파일되고, 실행 시간 동안 인수 값을 위한 공간을 확보할 수 있다는 점에서 Statement 객체와 다르다.
- Statement 객체의 SQL은 실행될 때, 매번 서버에서 분석해야 하는 반면 PreparedStatement 객체는 한 번 분석되면 재사용이 용이하다.
- 각 인수에 대해 위치홀더(placeholder)를 사용해 SQL 문장을 정의할 수 있게 하며, 위치 홀더는 '?'로 표현된다.
- 동일한 SQL문을 특정 값만 바꾸어서 여러 번 실행해야 할 때, 인수가 많아서 SQL문을 정리해야 할 필요가 있을 때 사용하면 유용하다.
장점
- 1번 처리 구간을 건너뛰고 2번부터 처리하기 때문에 SQL 처리가 빠르다.(Soft Parsing)
- 1번 구간은 SQL을 분석하는 처리도 하고 있지만, 건너뛰기 때문에 대입된 값은 SQL로 인식하지 않는다. 즉, SQL Injection을 예방할 수 있다.
단점
- 쿼리에 오류가 생긴 경우 분석하기 어렵다. 바인드변수 부분이 '?' 처리되므로 실제 실행된 쿼리를 확인하기 어렵다.
- 바인드변수는 일부 허용된 위치에서만 사용할 수 있기 때문에 동적 쿼리 작성이 힘들다.
- ex) 변수를 활용해 동적으로 테이블을 변경하는 쿼리를 작성해야 하는 경우 Prepared Statement로는 처리가 불가능하다.
Statement와 PreparedStatement의 차이점
- Statement: SQL문을 실행할 때마다 매번 구문을 새로 작성하고 해석해야하므로 오버헤드 존재
- PreparedStatement: 선처리 방식을 사용하므로 SQL문을 미리 준비해놓고 바인딩 변수(? 연산자)를 사용해서 반복되는 SQL문 쉽게 처리
RDBMS, NoSQL
RDBMS
관계형 데이터베이스 관리 시스템으로, RDBf란 모든 데이터를 2차원 테이블 형태로 표현하는 DB를 말한다.
- 관계를 맺고 있는 데이터가 자주 변경되는 경우
- 변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에 중요한 경우 사용
장점
- 정해진 스키마에 따라 데이터를 저장해야 하므로 명확한 데이터 구조 보장
- 각 데이터 중복 없이 한 번만 저장
단점
- 테이블 간 관계를 맺고 있어 시스템이 커질 경우 JOIN문이 많은 복잡한 쿼리가 만들어질 수 있다.
- 성능 향상을 위해서는 Scale-up만을 지원하므로 비용이 기하급수적으로 증가할 수 있다.
- 스키마로 인해 데이터가 유연하지 못함. 나중에 스키마가 변경될 경우 번거롭고 어렵다.
*Scale-up(=수직 스케일링(vertical scaling)): 기존 서버를 보다 높은 사양으로 업그레이드
Scale-out(=수평 스케일링(horizontal scaling)): 장비를 추가해서 확장
NoSQL(Not Only SQL)
RDB 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술
-
RDBMS와 달리 테이블 간 관계를 정의하지 않는다. 따라서 테이블은 그냥 하나의 테이블이며 일반적으로 테이블 간 조인도 불가능하다.
-
빅데이터의 등장으로 데이터와 트래픽이 기하급수적으로 증가함에 따라 RDBMS의 단점인 성능을 향상시키기 위해 등장
-
데이터 일관성은 포기하되 비용을 고려해 여러 대의 데이터에 분산해 저장하는 Scale-Out을 목표로 등장
-
정확한 데이터 구조를 알 수 없거나 변경/확장될 수 있는 경우
-
읽기를 자주 하지만, 데이터 변경은 자주 없는 경우
-
데이터베이스를 수평으로 확대해야 하는 경우(막대한 양의 데이터를 다뤄야 하는 경우) 사용
저장 형태
- Key-Value: Redis, Riak, Amazon DYnamo DB
- Document: MongoDB, CouthDB
- Wide Column: HBase, Hypertable
- Graph: Neo4J
장점
- 스키마가 없으므로 유연하며 자유로운 데이터 구조를 가질 수 있다.
- 언제든 저장된 데이터를 조정하고 새로운 필드를 추가할 수 있다.
- 데이터 분산이 용이하며 성능 향상을 위해 Scale-up 뿐만 아니라 Scale-out도 가능
단점
- 데이터 중복이 발생할 수 있으며, 중복된 데이터가 변경될 경우 모든 컬렉션에서 수정해야 한다.
- 스키마가 존재하기 않으므로 명확한 데이터 구조를 보장하지 않으며 데이터 구조를 결정하기 어려울 수 있다.
ORM(Object Relational Mapping)
객체-관계 매핑으로 OOP에서 쓰이는 객체라는 개념을 구현한 클래스와 RDB에서 사용되는 데이터인 테이블을 자동으로 매핑하는 것을 말한다.
객체 모델과 관계형 모델 간에 불일치가 존재하는데 이 객체간의 관계를 바탕으로 SQL을 자동 생성하여 불일치를 해결하는 것
Object <- 매핑 -> DB 데이터 에서 매핑의 역할을 해준다.
- SQL 문법 대신 어플리케이션의 개발 언어를 그대로 사용할 수 있게 함으로써, 개발 언어의 일관성과 가독성을 높여준다는 장점을 갖고 있다.
- ex) Python-Flask SQLAlchemy, Node.js-Sequlize, Java-Hibernate, JPA
장점
- 객체지향적 코드로 더 직관적이고 비즈니스 로직에 집중할 수 있도록 도와준다.
- CRUD를 위한 긴 SQL 문장 작성할 필요 X
- SQL의 절차적 접근이 아닌 객체적인 접근으로 생산성 증가
- 재사용 및 유지보수의 편리성 증가
- 매핑 정보가 명확해 ERD를 보는 것에 대한 의존도 낮출 수 있음
- ORM은 독립적으로 작성돼있고 해당 객체들은 재사용 가능
- DBMS에 대한 종속성 감소
- 대부분의 ORM은 DB에 종속적이지 않다.
- Object에 집중함으로써 DBMS를 교체하는 극단적 작업에도 비교적 적은 리스크와 시간 소요
- 구현 방법 뿐 아니라 많은 솔루션에서 자료형 타입에서까지 종속적이지 않다.
단점
- 완벽한 ORM만으로는 구현하기 어렵다.
- 프로시저가 많은 시스템에서는 ORM의 객체지향적 장점을 활용하기 어렵다.
*프로시저: 특정작업을 위한 프로그램의 일부, 함수와 같은 의미
Ref:
https://velog.io/@yrkim/Database-트랜잭션-deadlock
https://jaehoney.tistory.com/162
https://dev-jwblog.tistory.com/94?category=1004261
https://noirstar.tistory.com/264
https://velog.io/@dingdoooo/JDBC-Statement-PreparedStatement-이용하기
https://iksflow.tistory.com/127
https://pythontoomuchinformation.tistory.com/528
https://woooseogi.tistory.com/97
https://velog.io/@alskt0419/ORM에-대해서...-iek4f0o3fg
