
짱피곤한 하루....회사에서 일마치고 와서 Python으로 django공부도 좀 해보려고 하는데 되는게 없다....아마 디렉토리나 터미널을 쓰면서 문제가 생긴거 같은데 SW를 재설치하고 파이썬을 몇차례 재설치해도 해결이 되지 않으니 머리가 터질거 같다@.@
주변에서 도움을 줄 사람도 없다....이래서 컴공을 나왔어야 하는데 눙무리 난다..ㅠ

그래도 어찌저찌 Pycharm community edition으로 맛보기 정도는 진행하고 3주차 강의를 정리한다. 그것도 못했으면 나 오늘 우울해서 그냥 다 놓아버렸을거야.
힘내서 정리해보자!😂😂😂
지난번 반복문 조건문 이후에 본격적으로 뭔가 실습을 해보았는데 첫 실습은 Html, CSS, Javascript로 진행했던 것과 비슷하다. openAPI를 가져와서 조건에 맞는 결과 도출하기.
Python에서는 우선 import 라는 명령문을 통해 사용가능한 라이브러리를 설치해주어야 한다. request 라이브러리 설치를 통해 json형태의 데이터를 받을 준비를 해주자.
import requests # requests 라이브러리 설치 필요 //requests 를 사용해 요청(Request)하기 response_data = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99') //응답(response) 데이터인 json을 쉽게 접근할 수 있게 만들어 city_air 에 담고 city_air = response_data.json() gu_infos = city_air['RealtimeCityAir']['row'] for gu_info in gu_infos: if gu_info['PM10'] < 20: print(gu_info['MSRSTE_NM'], gu_info['PM10'])
위에서 실행한 실습은 좀 쉬운편이다. 지난번 html이나 css, javascript를 통해서 몇번 해보았으니까. 그런데 스크래핑(크롤링이라고도 하더라)은 조금 수준이 다른 얘기다.
여기서 중요한건 "BeautifulSoup"이라는 라이브러리를 활용해줘야 한다. 라이브러리가 많이 나와서 당황스러울 수 있는데 전혀 그럴필요 없다. 왜냐? 처음에는 외우기 어려우면 복붙하면 된다. 그러기 위해서 구글님은 존재하시니까 ㅎㅎ

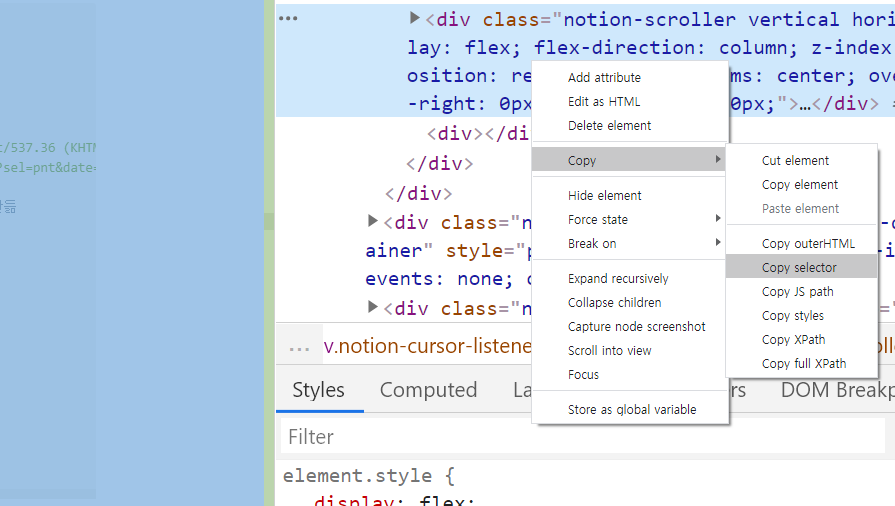
이제 스크래핑을 본격적으로 하려면 select와 selct_one, 그리고 검사 도구를 이용해 해당 웹페이지의 경로를 잘 확인하는 습관을 길러야 한다. "잘"이다. 경로를 확인하기 위해서는 물론 검사도구 앞에 붙어있는 class나 태그를 일일이 확인해줘도 된다. 그런데 이건 수능 수리영역 문제를 노가다로 푸는거랑 같다. 그니까 우린 기능을 이용하자.
아래와 같이 검사 도구에서 우클릭을 이용해 copy selecor를 클릭한 후 붙여넣기를 하면 해당 영역의 경로값이 나온다. 스크래핑(크롤링)에서는 정말 유용하다. (나중에는 어떻게 쓰일지 모르겠다 또 ㅎㅎ)
우리가 수업시간에 실습한 것은 영화페이지나 스포츠 야구에서 값들을 긁어오는 것이었는데 음...작성하다보니 나는 축구로 해보고 싶다. 그러면 네이버 스포츠의 해외축구에서 순위들을 긁어와보자. 우선 페이지 접속을 하는데 상당히 마음에 안든다...나는 리버풀 팬이니까요....
라는 것은 실패했다고 한다....튜터님께 질문을 드리니 동적 html이라 requests, BS4로는 실행이 불가능하다는 것이 이유....(따흙...ㅠㅠㅠ) 그래서 얌전히 우선 수업때 진행한 코드만 리뷰해보자 😂😂😂 우리의 숙제는 국내 야구구단들의 순위표에서 승률이 5할 이상인 팀의 값들만 가져오는 것!
import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} data = requests.get('https://sports.news.naver.com/kbaseball/record/index.nhn?category=kbo', headers=headers) soup = BeautifulSoup(data.text, 'html.parser') rank_table = soup.select('#regularTeamRecordList_table > tr') for info in rank_table: team_rank = info.select_one('th>strong').text team_name = info.select_one('td>div>span').text win_rate = info.select_one('td>strong').text if float(win_rate) > 0.5: print(team_rank, team_name, win_rate) #regularTeamRecordList_table > tr:nth-child(1) > td:nth-child(7) > strong #regularTeamRecordList_table > tr:nth-child(4) > td:nth-child(7) > strong
우선 requests라는 프레임워크를 입력하고 bs4에서 BeatifulSoup을 불러와준다.그리고 아래의 headers까지는 복붙을 사용하자. (복붙사용한다고해서 쉬운거 아니다, 무조건 있어야한다)(1)
그리고 data에는 request의 get함수를 통해 data를 불러올 url을 입력해주자.(2)
그리고 soup이란 변수에 BeautifulSoup과 parser를 이용해 url의 데이터를 검색과 정제하기에 용이하도록 만들어준다.(3)
그리고 여기서 앞서 공부한 copy selector가 활약할 차례이다. 순위를 클릭 후 copy selector를 이용하면 아래와 같은 디렉토리들이 나오는데 여기서 태그명과 클래스명을 활용해 데이터를 긁어와야 한다.
#regularTeamRecordList_table > tr:nth-child(1) > td:nth-child(7) > strong
여기서 select문을 통해서 table(순위표)과 각 변수들의 데이터가 검색될 수 있도록 경로를 지정해준다(4) 추가로 뒤에 .text를 추가해줘야 태그 사이의 속성값을 가져올 수 있기 때문에 까먹지 말자.
그리고 마지막으로 print문을 통해 값들을 출력해주는데(5)
❗여기서 주의할 점! 현재 우리가 뽑은 값들은 text를 통해서 변환한 값이라 모두 속성이 모두 string인 상태이다. 그런데 우리는 if문을 통해 승률이 5할 이상인 값들만 가져와야하는데 string 상태로는 >0.5 라는 조건문을 적어봤자 실행되지 않는다.
이럴때는 win_rate를 float()으로 감싸주자. 그러면 소수점까지 찍히는 실수형태로 값이 변환되기 때문에 문제없이 5할 이상의 팀들이 검색될 것이다.
자 이렇게 오늘의 수업 리뷰 #2도 완료!!! 근데 또 남았다....😂
우리는 mongodb를 통해 검색된 값들을 테이블에 집어넣는 실습까지 했는데 이거는 또 다음 편에 기록하는걸로!!!
요즘 django도 같이 공부하고 있는데....django는....스파르타 실습 다 끝나야 기록 가능할거 같다....비전공자 하루하루 내 머리를 비워내고 집어넣고 힘들지만 앞으로도 화이팅해서 누구나 보고 한눈에 이해할 수 있는 코딩을 하는 백엔드 개발자가 되자!🔥🔥🔥🔥🔥🔥
