딥러닝모델구현순서
- 데이터셋 준비하기
- 딥러닝 모델 구축하기
- 모델 학습시키기
- 평가 및 예측하기
1. 데이터셋 준비하기 : Epoch와 Batch
Epoch:한번의 epoch는 전체 데이터셋에 대해 한번 학습을 완료한 상태
Batch: 나눠진 데이터 셋 (보통 mini-batch라고 표현) iteration는 epoch를 나누어서 실행하는 횟수를 의미
코드 예시
(Dataset API를 사용하여 딥러닝 모델 용 데이터 셋을 생성)
data = np.random.sample((100,2))
labels = np.random.sample((100,1))
# numpy array로부터 데이터셋 생성
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
dataset = dataset.batch(32)2.딥러닝 모델 구축하기: 고수준 API 활용

텐서플로우의 패키지로 제공되는 고수준 API
딥러닝 모델을 간단하고 빠르게 구현 가능
딥러닝 모델 구축을 위한 Keras 메소드(1)
모델 클래스 객체 생성
tf.keras.models.Sequential()모델의 각 Layer 구성
tf.keras.layers.Dense(units, activation)• units : 레이어 안의 Node의 수
• activation : 적용할 activation 함수 설정
Input Layer의 입력 형태 지정하기
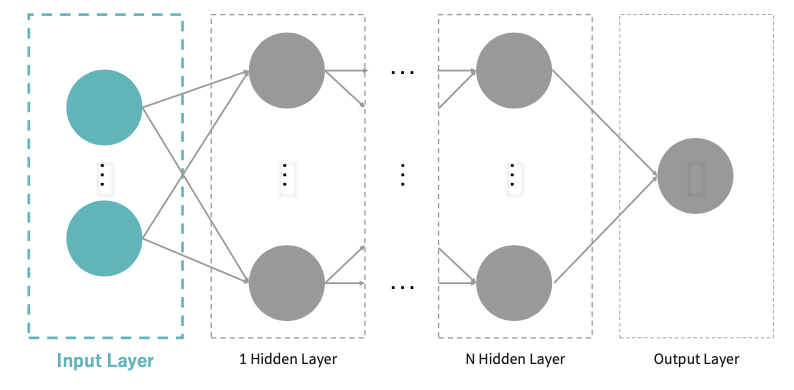
첫번째 즉,InputLayer는 입력 형태에 대한 정보를 필요로 함
input_shape / input_dim 인자 설정하기
모델 구축하기 코드 예시(1)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_dim=2, activation=‘sigmoid’),
tf.keras.layers.Dense(10, activation=‘sigmoid'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])딥러닝 모델 구축을 위한 Keras 메소드(2)
모델에 Layer 추가하기
[model].add(tf.keras.layers.Dense(units, activation))• units : 레이어 안의 Node의 수
• activation : 적용할 activation 함수 설정
모델 구축하기 코드 예시(2)
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(10, input_dim=2, activation=‘sigmoid’))
model.add(tf.keras.layers.Dense(10, activation=‘sigmoid’))
model.add(tf.keras.layers.Dense(1, activation='sigmoid’))3. 딥러닝 모델 학습시키기 : Keras 메소드
모델 학습 방식을 설정하기 위한 함수
[model].compile(optimizer, loss)• optimizer : 모델 학습 최적화 방법
• loss : 손실 함수 설정
모델을 학습시키기 위한 함수
[model].fit(x, y)• x : 학습데이터
• y : 학습 데이터의 label
딥러닝 모델 학습시키기 코드 예시
model.compile(loss='mean_squared_error’, optimizer=‘SGD')
model.fit(dataset, epochs=100)4.평가및예측하기:Keras메소드
모델을 평가하기 위한 메소드
[model].evaluate(x, y)• x : 테스트 데이터
• y : 테스트 데이터의 label
모델로 예측을 수행하기 위한 함수
[model].predict(x)• x : 예측하고자 하는 데이터
평가및예측하기코드예시
# 테스트 데이터 준비하기
dataset_test = tf.data.Dataset.from_tensor_slices((data_test, labels_test))
dataset_test = dataset.batch(32)
# 모델 평가 및 예측하기
model.evaluate(dataset_test)
predicted_labels_test = model.predict(data_test)
👩🏻💻