
여러 개의 뉴런으로 XOR 문제를 해결
- 하나의 뉴런으로는 XOR문제를 해결할 수 없지만 뉴런을 여러 개 쌓으면 이 문제를 해결할 수 있음
#XOR를 뉴런으로 구현 import numpy as np X = np.array([[0,0], [0,1], [1,0], [1,1]]) y = np.array([[0], [1], [1], [0]]) b = tf.random.normal([1], 0, 1) #입력이 2개라서 가중치를 2개 생성 w = tf.random.normal([2], 0, 1) for i in range(2000): #오차의 합계를 저장할 변수 error_sum = 0 #모든 입력을 대입해서 수행 for j in range(4): output = sigmoid(np.sum(X[j] * w) + 1 * b) error = y[j][0] - output w = w + X[j] * 0.1 * error b = b + 1 * 0.1 * error error_sum += error if i % 100 == 0: print(i, error_sum) #predict for i in range(4): print("X:", X[i], "Y:", y[i], "Predict:", sigmoid(np.sum(X[i]*w)+b))X = np.array([[0,0], [0,1], [1,0], [1,1]]) y = np.array([[0], [1], [1], [0]]) model = tf.keras.Sequential([ tf.keras.layers.Dense(units=2, activation='sigmoid', input_shape=(2,)), tf.keras.layers.Dense(units=1, activation='sigmoid') ]) model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.01), loss='mse') model.summary() history = model.fit(X, y, epochs=8000, batch_size=1) model.predict(X)#가중치 와 편향 확인 for weight in model.weights: print(weight)# loss 시각화 import matplotlib.pyplot as plt plt.plot(history.history['loss'])
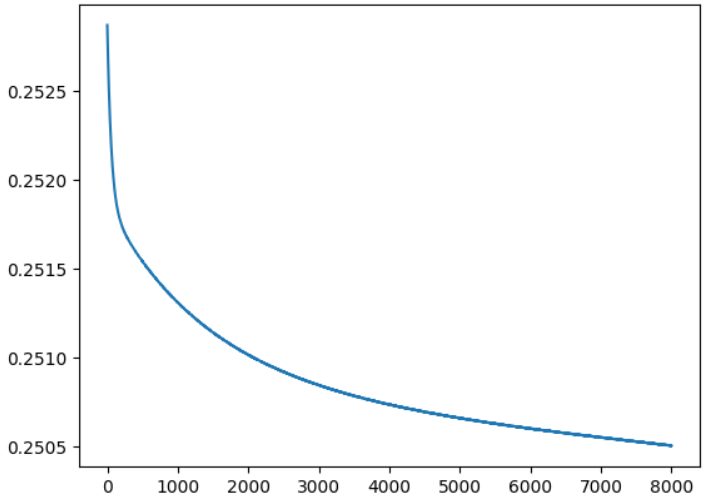
-
위의 구조는 입력 2개 뉴런 2개로 구성된 첫번째 층 과 두번째는 첫번째 층의 출력인 2개의 입력을 받아서 하나을 출력
-
입력 피처가 뉴런 각각에 모두 대입되고 거기서 나온 가중치를 가지고 다음 뉴런에서 입력으로 사용해서 가중치를 수정
-
각각의 레이어를 통과할 때 마다 편향이 추가
-
훈련을 한 뒤, 리턴되는 데이터에는 훈련에 관련된 정보가 전부 저장됩니다.
-
손실의 값을 확인할 수 있습니다.
✔ Tensorflow Data API
개요
- DL 에서는 아주 큰 규모의 Dataset을 가지고 훈련해야 하는 경우가 많은데, Data를 로드하고 Preprocessing하는 작업이 번거로운데, 이러한 작업을 쉽게 할 수 있도록 해주는 API 이다.
- Multi Threading, Queue, Prefetch같은 처리를 수행한다.
- 데이터를 읽을 때, 나누어서 순서에 상관없이 읽어도 되는 것인지 아니면 순서가 있는 것인지, 나누어서 읽어야 하는 건지를 판단하는 것이 중요하다.
- CSV, RDBMS, Big Query 등에서 데이터를 읽어오는 기능을 제공함
- one-hot-encoding같은 전처리를 읽으면서 수행하는 것도 가능함
메모리에서 데이터 생성
# 메모리에서 데이터 생성 X=tf.range(10) dataset=tf.data.Dataset.from_tensor_slices(X) print(dataset) ## dataset=tf.data.Dataset.range(10) print(dataset) for item in dataset: print(item)dataset=tf.data.Dataset.range(10) dataset=dataset.repeat(3).batch(8, drop_remainder=True) # 3번 반복하는데, 8개씩 묶어서, 8개로 안묶이면 버리기 for item in dataset: print(item)# help(dataset.map) # map은 데이터 변환할 때 쓰인다. # map(map_func, num_parallel_calls=None, deterministic=None, name=None) # num_parallel_calls 스레드의 개수 설정가능함 dataset=tf.data.Dataset.range(10) # 데이터를 변환할 때 스레드 2개를 사용 dataset=dataset.map(lambda x : x*2, num_parallel_calls=2) for item in dataset: print(item) print(dataset)dataset=tf.data.Dataset.range(10) for item in dataset.take(3): print(item)
Data shuffling
- 경사 하강법은 훈련 세트에 있는 샘플이 독립적이고 동일한 분포일 때, 최고의 성능을 발휘함
- shuffle이라는 함수를 이용하면, 데이터를 랜덤하게 추출할 수 있는데 Dataset에서 batch_size만큼 데이터를 랜덤하게 추출하고, 아이템 요청이 오면 버퍼에서 랜덤하게 하나를 꺼내서 반환하고, Dataset에서 새로운 아이템을 버퍼에 제공하는 형태로 동작함
- 버퍼의 크기를 크게 만드는 것이 효과를 높이는 방법이긴 하지만, 버퍼의 크기가 너무 크면 메모리에 부담을 주게 됩니다.
- 데이터셋보다는 클 필요는 당연히 없다.
- shuffling에서 기억할 것은, 데이터를 일정한 순서대로 제공하려 한다면, random_seed를 상수로 부여해야 합니다.
#shuffling dataset=tf.data.Dataset.range(30) # seed 를 상수로 고정하지 않으면 랜덤하게 셔플링 # 버퍼의 크기는 5, 배치는 6 dataset=dataset.shuffle(buffer_size=5, seed=42).batch(6) for item in dataset: print(item)
- 메모리 용량보다 큰 대규모 Dataset은 버퍼가 Dataset보다 작기 때문에, 지금까지의 방법으로는 충분하지 않아서 이런 경우에는 원본 데이터 자체를 섞어야 합니다.
- Linux에서는 shuf 명령을 활용 - 한 번 훈련하는 과정을 epoch라고 하는데, epoch마다 데이터를 섞어주는 것이 좋습니다.
- epoch에서 데이터를 섞지 않는다면, 데이터에 포함된 가짜 패턴(편향)이 학습되어버린다. - 하나의 파일에 존재하는 데이터는 동일한 방식으로 처리되기에, 딥러닝이나 머신러닝에 사용해야 하는 데이터를 파일에 저장할 때는 여러개의 파일로 데이터를 나누고, 학습을 할 때 파일들의 일부분을 랜덤하게 읽어서 학습에 사용하는 것도 좋은 방법이다.
# 데이터를 읽어서 나누어 저장하고 읽어오는 작업을 해보자. from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler housing=fetch_california_housing() # train- 훈련, valid-훈련 중 검증, test- 모델 생성 후 테스트 X_train_full, X_test, y_train_full, y_test=train_test_split(housing.data, housing.target.reshape(-1,1), random_state=42) X_train, X_valid, y_train, y_valid=train_test_split(X_train_full,y_train_full, random_state=42) scaler=StandardScaler() scaler.fit(X_train) X_mean=scaler.mean_ X_std=scaler.scale_ print(X_mean) print(X_std)# 데이터를 여러 개의 파일로 나누어서 저장하는 함수 # param : 데이터, 파일 맨앞 공통이름, 헤더 포함 여부, 파일 개수 import os def save_to_multiple_csv_files(data, name_prefix, header=None, n_parts=10): # 파일을 저장할 디렉 생성 housing_dir=os.path.join("Datasets","housing") os.makedirs(housing_dir,exist_ok=True) # 파일 경로 패턴 생성 path_format=os.path.join(housing_dir, "my_{}_{:02d}.csv") filepaths=[] #파일 경로 저장 리스트 m=len(data) #데이터 개수 # m개수만큼 숫자열 만들고 n_parts 만큼 분할 # 분할한 그룹번호는 file_idx, 행번호는 row_indices에 저장 for file_idx, row_indices in enumerate(np.array_split(np.arange(m), n_parts)): # 실제 파일 경로 생성 part_csv=path_format.format(name_prefix,file_idx) filepaths.append(part_csv) # 데이터 기록 with open(part_csv, 'wt', encoding='utf-8') as f: if header is not None: f.write(header) f.write('\n') # 행 인덱스로 데이터 순회하며 각 데이터 ,로 구분해서 작성 for row_idx in row_indices: f.write(','.join([repr(col) for col in data[row_idx]])) f.write('\n') return filepathstrain_data=np.c_[X_train, y_train] valid_data=np.c_[X_valid, y_valid] test_data=np.c_[X_test, y_test] headers_cols=housing.feature_names+['MedianHouseValue'] header=','.join(headers_cols) train_filepaths=save_to_multiple_csv_files(train_data,"train",header,n_parts=20) valid_filepaths=save_to_multiple_csv_files(valid_data,"valid",header,n_parts=20) test_filepaths=save_to_multiple_csv_files(test_data,"test",header,n_parts=20)
- 잘 만들어지긴 했다.
# 파일 이름 랜덤하게 가져오기 filepath_dataset=tf.data.Dataset.list_files(train_filepaths) for filepath in filepath_dataset: print(filepath)
- seed 상수 넣으면 고정되긴함
# 5개의 파일에서 번갈아가면서 데이터를 읽어오자 n_readers=5 # 파일 경로에 있는 내용을 5개씩 번갈아가면서 # 줄단위로 읽어오기 dataset=filepath_dataset.interleave( lambda filepath:tf.data.TextLineDataset(filepath).skip(1), cycle_length=n_readers ) for line in dataset.take(5): print(line.numpy())
- 메모리 인터리븐
- 과연 램 64gb 하나가 좋을까 32 2개가 좋을까?
- 하나만 돌리면 64가 좋겠지..- interleave는 기본적으로 병렬화를 하지 않음
- num_parallel_calls 매개변수에 코어의 개수를 지정하면, 동시에 읽어옵니다.
- 개수를 설정을 못하는 경우에는tf.data.experimental.ATUOTUNE을 지정하면, 가능한 최대 코어 개수로 설정을 하게 됩니다.(-1과 같은 효과)
Tensorflow Dataset 프로젝트
- https://www.tensorflow.org/datasets?hl=ko 에 가면, 널리 사용되는 데이터셋을 손쉽게 다운로드 할 수 있다.
✔ Tensorflow를 이용한 회귀와 분류
Keras의 Dense
Dense
- 완전 연결층을 만들기 위한 클래스
- 생성할 때 파라미터
- unit : 뉴런의 개수 - 많을 수록 학습을 잘함
- activation : 활성화 함수 - sigmoid, softmax, hanh, relu 등..
- input_shape : 입력 데이터의 차원을 설정
선형 회귀 구현
- 하나 이상의 독립 변수들이 종속 변수에 미치는 영향을 추정하는 통계 기법
Keras의 모델 생성 방법
- Sequential API
- 순서대로 층을 쌓는것 - Functional API
- 함수에 대입하는 것 - SubClassing
- 기반 클래스로부터 상속을 받아서 사용
- inheritance -> is A -> SubClassing , 조금씩은 다르긴 함
- is A는 기능 구현, 구체화, 구현의 의미
- SubClassing은 기능 확장의 의미 (오버라이딩)
Sequential API 사용
- list 이용
model=tf.keras.Sequential([tk.keras.layers.Dense(10),
tk.keras.layers.Dense(5),
tk.keras.layers.Dense(1)])- add로 추가하는 방법
model=tf.keras.Sequential()
model.add(tk.keras.layers.Dense(10))
model.add(tk.keras.layers.Dense(5))
model.add(tk.keras.layers.Dense(1))- 성능 상의 차이는 없다. 방법의 차이이다.
- 첫 번째 층은 입력층이어야 합니다.
- 첫 층에서는 input_shape로 입력 데이터의 차원을 설정해야 합니다.
- 어떤 데이터가 (150,4)형식의 입력 구조라면, (4,), [4]로 설정하면 됩니다.
- 앞에 150 뺀 이유는, 데이터 차원 중 첫째는 데이터의 개수이기 때문이다.
- DL에서 훈련하는 것은 데이터 개수와는 상관이 없고, 데이터 구조와 관계가 있으므로, 150은 뺀 것이다. - 입력이 1개인 차원의 단순 선형회귀는 하나의 Layer로 해결이 가능합니다.
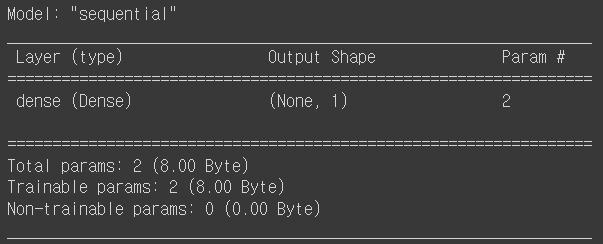
import tensorflow as tf # 입력 차원이 1개인 단순 선형 회귀 X=np.arange(1,6) y=3*X+2 # 모델 만들기 model=tf.keras.Sequential([ tf.keras.layers.Dense(1, input_shape=[1]) ]) # 모델의 구조 확인하기 model.summary()
- 컴파일
- 훈련 과정에서 적용할 Optimizer, Loss Function, Metrics를 넣어야 한다.# 컴파일 model.compile(optimizer='sgd',loss='mean_squared_error', metrics=['mean_squared_error','mean_absolute_error']) # 축약이 가능하다 model.compile(optimizer='sgd',loss='mse',metrics=['mse','mae']) # 매개변수를 인스턴스나 함수 또는 변수로 설정하기 model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.005), loss=tf.keras.losses.MeanSquaredError(), metrics=[tf.keras.losses.MeanSquaredError(), tf.keras.losses.MeanAbsoluteError()])
- 훈련
- 훈련은 fit 함수로 수행릏 가ㅔ 되는데, fit을 할 때는 데이터를 제공해야 하고, epoch를 설정하는데, epoch는 훈련 횟수이며, verbose=0을 설정하면 훈련 과정이 출력이 안됩니다.
- fit 함수에 옵션을 설정하면, 검증 데이터 세트를 이용해서 검증을 할 수 도 있습니다.
- fit 함수가 return하는 데이터는, epoch 별 훈련 손실과 평가 지표가 dict형태로 저장됩니다.#훈련 #verbose 는 훈련 중간에 로그출력 0이면 과정 내용 출력 x history=model.fit(X,y, epochs=2000, verbose=0)
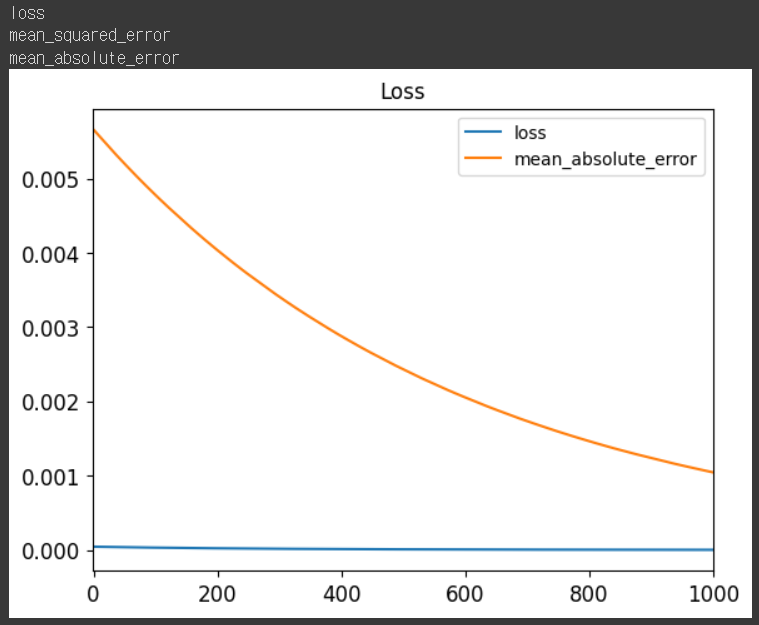
- 훈련 과정에서 발생하는 손실갑소가 평가 지표 시각화
- fit 함수를 호출하고# 훈련 과정에서 발생하는 손실갑소가 평가 지표 시각화 for key in history.history: print(key) plt.plot(history.history['loss'],label='loss') plt.plot(history.history['mean_absolute_error'],label='mean_absolute_error') # plt.plot(history.history['mean_squared_error'],label='mse') plt.xlim(-1,1000) plt.title("Loss") plt.legend() plt.show()
# 검증 model.evaluate(X,y)
- [1.4789044371354976e-06, 1.4789044371354976e-06, 0.0010437965393066406]
# 예측 y=3*X+2 model.predict([10])
- array([[32.005043]], dtype=float32)
✔ Classification (분류)
데이터
- 텐서플로 허브의 와인 데이터
- 레드와 화이트 와인으로 분류
- 가져오는 URL 달라서 가져와서 하나의 데이터로 합쳐야 한다.
- feature만 존재(target X) - feature
- fixed acidity : 주석산
- volatile acidity : 초산
- citric acid : 구연산
- residual sugar : 당도
- chlorides : 소금
- free sulfur dioxide : 자유 이산화 황
- total sulfur dioxide : 총 이산화 황
- density : 밀도
- pH : 산도
- sulphates : 황산 칼륨
- alcohol : 알코올 도구
- quality :품질(1 ~ 10) - http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv
- http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv
이항 분류
- 두 가지 중 하나로 분류하는 것
레드인지 화이트 와인인지 분류를 해 보자
- 데이터 로드
import pandas as pd red=pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv', sep=';') white=pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv', sep=';') print(red.head()) print(white.head())
- 2개의 데이터 합치고 타겟 생성
# 타겟 만들기 red['type']=0 white['type']=1 # 2개의 데이터를 세로 방향으로 합치기 wine=pd.concat([red,white]) print(wine.describe)
- 타겟의 분포를 확인하자
- 분류의 경우는 분포가 고르게 되어야 하고, 회귀의 경우는 정규 분포와 유사한 경우에 예측이 잘 됩니다.
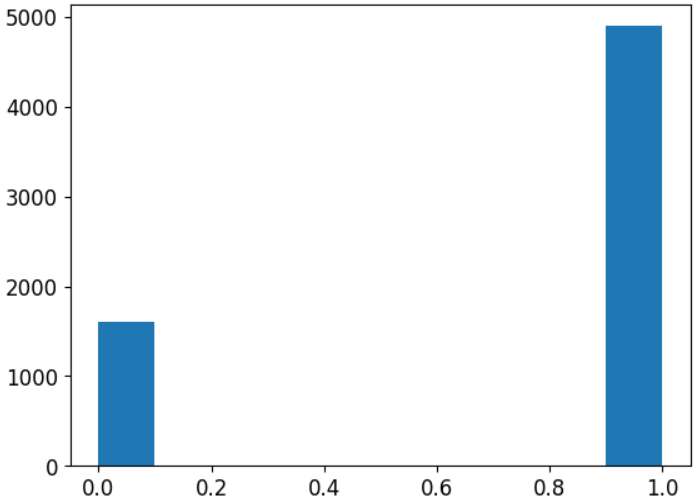
- 분류의 경우는 histogram을 많이 그리고, 회귀의 경우에는 산포도를 많이 그립니다.# 타겟 분포 확인 plt.hist(wine['type']) plt.show() # 3배정도 차이ㅏ가 나는데 이 정도는 괜찮아 한 5배까진 괜찮아
- feature 정규화
# 데이터 정규화 #sklearn의 MinMaxScaler 이용한것과 동일함 wine_norm=(wine-wine.min())/(wine.max()-wine.min()) print(wine_norm.head()) print(wine_norm.describe())
- 데이터 샘플링
# Data Sampling wine_shuffle=wine_norm.sample(frac=1) #frac : 비율, sample : 랜덤, frac=1이면 전체 print(wine_shuffle.head())
- Tensor와 numpy의 ndarray는 호환이 되지만, pandas의 df는 호환이 안되어서 np의 배열로 변경
# pd의 df를 np의 ndarray로 변환 wine_shuffle.values # wine_shuffle.to_numpy() # 결과는 똑같다
- 이전에 머신러닝에서 csv파일의 데이터를 pd의 df로 읽은 경우, 이렇게 랜덤하게 섞어서 numpy 배열로 변환하면, 딥러닝에 이용이 가능합니다.
- 딥러닝에서는 DataFrame 사용 불가
- 현재 타겟은 0과 1인데, 이를 맞다 틀리다 or 서로 배타적 분류로 취급할 것인지를 결정해야 한다.
- 이것이 단항분류와 이항분류의 차이
- yes no : 단항분류로 간주
- red white : 배타적 분류, 이항분류로 간주- 왜 해야 하냐?
- 이항분류는 타겟을 One-Hot-Encoding을 해줘야 하기 때문이다.- One-Hot-Encoding을 하려고 한다면
-tf.keras.utils.to_categorical(데이터, num_classes=클래스개수)
- 훈련에 사용할 데이터를 생성하자
# 훈련에 사용할 데이터를 생성하자 train_idx=int(len(wine_np)*0.8) # 맨 마지막 열을 기준으로 열 단위 분할해서 feature와 target으로 분리 train_X, train_y=wine_np[:train_idx,:-1],wine_np[:train_idx,-1] test_X, test_y=wine_np[train_idx:,:-1],wine_np[train_idx:,-1] # 레드와 화이트로 분류할것이라 원핫인코딩 수행 train_y=tf.keras.utils.to_categorical(train_y, num_classes=2) test_y=tf.keras.utils.to_categorical(test_y, num_classes=2) print(train_X.shape, test_X.shape) print(train_y.shape, test_y.shape)
- shape를 잘 확인하자
- 분류를 수행할 때, 모델을 만드는 방법
- 입력 층 1개와 출력 층 1개는 필수입니다.
- 입력층에서 input_shape에 입력 데이터의 열의 수를 설정해야 한다
- 출력층에서는 activation에 출력을 위한 함수를 지정해야 하는데, 다항분류는 softmax를 사용해야 합니다.
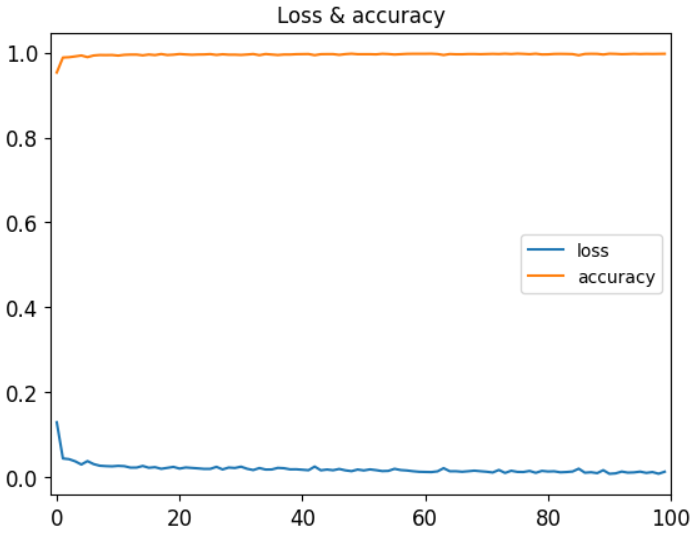
- 중간 Hidden층은 몇개를 설정해도 관계가 없지만, 일반적으로 상위층보다 뉴런의 개수가 같거나 작아야 합니다.# 분류 모델을 만들어보자 ''' model=tf.keras.Sequential([ tf.keras.layers.Dense(units=?, activation=?, innput_shape(입력 피처의 개수, )), tf.keras.layers.Dense(), tf.keras.layers.Dense(units=출력 클래스 개수, activation=?) ]) ''' # 이항분류이고 피처 개수 12개 # 첫 입력측 input_shape는 무조건 (12,) # 마지막 출력층 units은 클래스 개수이므로 2 # 다항 분류이기에 activation은 softmax 고정 # 중간 층들의 units는 마음대로 설정가능 model=tf.keras.Sequential([ tf.keras.layers.Dense(units=48, activation='relu', input_shape=(12,)), tf.keras.layers.Dense(units=24, activation='relu'), tf.keras.layers.Dense(units=12, activation='relu'), tf.keras.layers.Dense(units=6, activation='relu'), tf.keras.layers.Dense(units=2, activation='softmax') ]) #모델을 만들었으면 컴파일을 해야합니다. # 최적화 함수는 Adam, 학습률 0.005 # 손실함수는 카테고리 크로스 엔트로피 # 평가 지표는 정확도 model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.005), loss='categorical_crossentropy', metrics=['accuracy']) # 구조를 확인해보자 model.summary() # 훈련 history=model.fit(train_X,train_y, epochs=100, verbose=0)# 평가 지표 시각화 for key in history.history: print(key) plt.plot(history.history['loss'],label='loss') plt.plot(history.history['accuracy'],label='accuracy') plt.xlim(-1,100) plt.title("Loss & accuracy") plt.legend() plt.show()
- softmax 함수
- 출력 값들을 자연 로그의 밑인 e의 지수를 사용해서 계산한 뒤, 모두 더한 값
- 각 출력의 합은 1.0
- 각 클래스별 확률을 구해주는 함수
- 분류 문제나 RNN에서 다음 토큰을 예측, 강화학습에서 다음 행동 확률을 구하는 경우에 사용- Entropy
- 물리학에서 불확실한 정보를 숫자로 정량화한 수치
- 통계학에서는 확률의 역수에 로그를 취한 값
- 확률의 역수를 취하는 이유는 확률이 높은 사건일수록 놀랍지 않다고 판단하기 때문
비가 올 확률은 1%, 안올확률은 99% h(비)=-log0.01=4.605 h(비x)=-log0.99=0.010
- 엔트로피의 기대값은 정보량에 확률을 곱해준 값
비 : 0.01*4.605=0.0461 비X : 0.99*0.010=0.0099
- 엔트로피의 총 합을 줄여나가는 방식으로 알고리즘을 학습
- 엔트로피가 높은 사건이 더 가치있는 사건일 가능성이 높음
- CrossEntropy
- 실제로 확률대신에 분류 네트워크가 예측한 라벨의 확률값을 곱함
- 이 값도 손실이므로, 낮은 쪽으로 가도록 학습을 해야 합니다.
- 훈련 & 평가
# 훈련 # validation_split을 설정하면 그 비율만큼을 검증 데이터로 # 사용해서 검증을 수행합니다. # batch_size는 데이터를 분할해서 학습을 수행합니다. # 중요한 의미를 갖습니다. history=model.fit(train_X, train_y, epochs=100, validation_split=0.25, batch_size=64)# 이제 평가를 해야한다. model.evaluate(test_X, test_y)
다항 분류
- 2개 보다 많은 클래스로 분류하는 것 - 3개의 클래스 분류
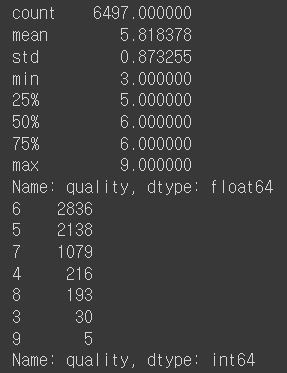
- quality를 확인해보자.
- 데이터는 다시 새로 가져오는게 좋다 (type 불필요)
print(wine['quality'].describe()) print(wine['quality'].value_counts())
- 3 ~ 5를 0, 6을 1, 7 ~ 9 를 2로 그룹화 할 것이다.
# 타겟 생성 wine.loc[wine['quality']<=5, 'new_quality']=0 wine.loc[wine['quality']==6, 'new_quality']=1 wine.loc[wine['quality']>=7, 'new_quality']=2 wine.head()
- feature만 정규화
- 이전에는 타겟이 0과 1로만 이루어져 있으므로 min_max정규화를 해도 그대로이다.
- 이제는 타겟이 0,1,2 이라 정규화하면 0, 0.5, 1이 되어버릴것이다. 그러니 타겟은 빼자
- feature만 골라서 정규화, 전체 데이터를 copy해두고 전체 정규화하고 target만 복제본에서 가져오기# 피처 정규화 - 타겟 제외 정규화 # del wine['quality'] # 한번하면 주석처리하기 wine_backup=wine.copy() #복제본 wine_norm=(wine-wine.min())/(wine.max()-wine.min()) wine_norm['new_quality']=wine_backup['new_quality'] wine_norm.head()# 훈련 데이터와 테스트 데이터 분할 wine_shuffle=wine_norm.sample(frac=1) wine_np=wine_shuffle.to_numpy() train_idx=int(len(wine_np)*0.8) train_X, train_y=wine_np[:train_idx, :-1], wine_np[:train_idx, -1] test_X, test_y=wine_np[train_idx:, :-1], wine_np[train_idx:, -1] # target one-hot-encoding train_y=tf.keras.utils.to_categorical(train_y, num_classes=3) test_y=tf.keras.utils.to_categorical(test_y, num_classes=3) print(train_X.shape, test_X.shape) print(train_y.shape, test_y.shape)# model model=tf.keras.Sequential([ tf.keras.layers.Dense(units=256, activation='relu', input_shape=(12,)), tf.keras.layers.Dense(units=128, activation='relu'), tf.keras.layers.Dense(units=64, activation='relu'), tf.keras.layers.Dense(units=32, activation='relu'), tf.keras.layers.Dense(units=16, activation='relu'), tf.keras.layers.Dense(units=8, activation='relu'), tf.keras.layers.Dense(units=3, activation='softmax') ]) # loss는 분류시 categorical_crossentropy를 많이 씁니다. # metrics는 알아보기 쉬운 것으로 model.compile(optimizer=tf.keras.optimizers.RMSprop(learning_rate=0.0001), loss='categorical_crossentropy', metrics=['accuracy']) model.summary() history=model.fit(train_X, train_y, epochs=500, batch_size=32, validation_split=0.2)
- 분류해야 할 클래스 개수가 늘어나면 층의 깊이가 더 깊어지거나 학습률을 더욱 낮추어야 잘 훈련한다.
model.evaluate(test_X, test_y)
- lr에 epoch조절하니 좀 오른다

오늘의 자습 주제 - Thread & Coroutine
https://velog.io/@haero_kim/Thread-vs-Coroutine-%EB%B9%84%EA%B5%90%ED%95%B4%EB%B3%B4%EA%B8%B0
-
thread를 살펴 볼 때, mutual exclusion, synchronize, semaphore, dead lock의 개념도 함께 살펴보기
-
ml 6장의 문제 중 분류 문제를 ml이나 dl dense층을 이용해서 해결해보기

밀가루 귀여워요