
0. PyG
Pytorch Geometric, 줄여서 PyG는 그래프 신경망(GNN)을 쉽게 작성하고 훈련할 수 있도록 PyTorch를 기반으로 구축된 라이브러리다. 그래프 혹은 불규칙한 구조에 대해 여러 논문에서 제안된 딥러닝 기법들로 구성되어 있다.
1. 데이터
1.1. 데이터 핸들링
PyG에서 다루는 데이터는 그래프다. 이에 따라 그래프를 torch_geometric.data.Data 클래스를 통해 데이터 형태로 변환한다.
예를 들어, 그림과 같이 3개의 노드로 구성된 그래프를 PyG에서 정의된 데이터로 변환해보자.
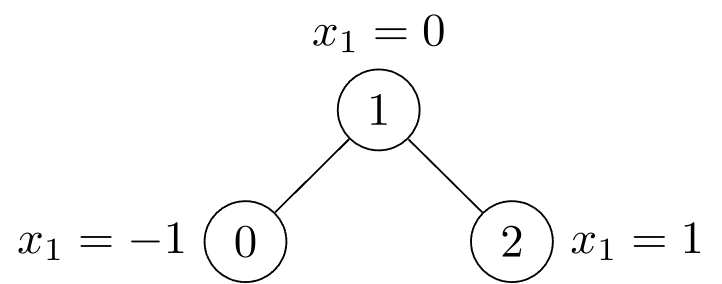
그래프 내의 노드들은 모두 1개의 feature를 갖고 있고, 이들 중 노드 0과 1, 노드 1과 2는 방향성이 없는 엣지로 연결되어 있다. 이러한 정보들을 텐서로 표현하면 다음과 같다.
import torch
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
edge_index = torch.tensor([[0, 1, 1, 2], # 출발 노드 인덱스
[1, 0, 2, 1]], # 도착 노드 인덱스
dtype=torch.long)x는 노드 feature 행렬을, edge_index는 노드들 간의 연결을 나타낸다. 여기서 edge_index는 연결에 있어 방향성을 고려하여, 노드 0과 1을 연결하는데 0 -> 1과 1 -> 0을 모두 포함한다.
이러한 정보들은 Data 타입의 파라미터로 사용되어 그래프 데이터를 표현한다.
from torch_geometric.data import Data
data = Data(x=x, edge_index=edge_index)
>>> Data(x=[3, 1], edge_index=[2, 4])위 그래프를 Data 타입으로 나타낸 data가 노드 feature 행렬 x와 노드들 간의 연결을 나타내는 edge_index를 파라미터로 갖는 것을 확인할 수 있다.
이 외에도 Data 타입의 객체에는 그래프 데이터가 보유할 수 있는 attribute들이 존재한다.
edge_attr: 엣지 feature 행렬,[엣지 수, 엣지 feature 수]y: 그래프 수준 또는 노드 수준의 레이블,[1, *]또는[노드 수, *]pos: 노드의 위치 행렬,[노드 수, 차원 수]
데이터의 통계량이나 기타 정보를 확인하는 것도 가능하다.
num_nodes: 그래프 내의 노드 수num_edges: 그래프 내의 엣지 수num_node_features: 각 노드가 갖는 feature 수has_isolated_nodes(): 고립 노드 존재 여부has_self_loops(): self-loop 존재 여부is_directed(): 그래프 내 모든 엣지의 방향성 존재 여부
data.num_nodes
>>> 3
data.num_edges
>>> 4
data.num_node_features
>>> 1
data.has_isolated_nodes()
>>> False
data.has_self_loops()
>>> False
data.is_directed()
>>> False1.2. 벤치마크 데이터셋
PyG 라이브러리는 통용되는 벤치마크 데이터셋을 제공한다. 간단한 초기화 과정을 통해 raw 데이터를 다운로드하고 앞서 설명한 Data로 가공된다. 아래는 ENZYMES 데이터셋을 불러오는 과정이다.
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES')
>>> ENZYMES(600)
len(dataset)
>>> 600ENZYMES(600)은 ENZYMES 데이터셋 내에 600개의 그래프가 존재함을 의미한다.
dataset.num_classes
>>> 6
dataset.num_node_features
>>> 3또한, num_classes와 num_node_features attribute를 이용하여 6종류로 그래프들을 구분할 수 있고 그래프의 노드들은 모두 3개의 feature를 보유함을 확인할 수 있다.
ENZYMES 데이터셋은 그래프 분류를 위한 데이터셋으로, 하나의 그래프가 하나의 데이터 포인트에 해당한다. 즉, 인덱싱 및 슬라이싱이 가능하다.
data = dataset[0]
>>> Data(edge_index=[2, 168], x=[37, 3], y=[1])
data.is_undirected()
>>> True
train_dataset = dataset[:540]
>>> ENZYMES(540)
test_dataset = dataset[540:]
>>> ENZYMES(60)dataset[0]는 데이터셋에서 1번째 그래프를 의미한다. 해당 그래프를 호출하여 정보를 확인할 수 있다. 슬라이싱을 통해 학습 및 평가를 위해 데이터셋을 분할할 수도 있다.
노드 분류를 위한 Cora 데이터셋은 그 형태가 약간 다르다.
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='/tmp/Cora', name='Cora')
>>> Cora()
len(dataset)
>>> 1Cora()에는 ENZYMES와 달리 괄호 안에 숫자가 없는데, 노드 분류를 위한 데이터셋이기 때문에 여러 개의 노드로 구성된 하나의 그래프를 의미한다.
dataset.num_classes
>>> 7
dataset.num_node_features
>>> 1433Cora 데이터셋의 7개의 클래스는 노드를 분류하는 레이블이며 1433개의 노드 feature가 존재한다.
data = dataset[0]
>>> Data(edge_index=[2, 10556], test_mask=[2708],
train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])
data.is_undirected()
>>> True하나의 그래프가 전체 데이터셋을 구성함에 따라, 각 데이터 포인트는 그래프를 구성하는 노드들이 된다. 이 때, 그래프 내에서 노드 간의 연결 관계를 무시할 수 없기 때문에 Cora 데이터셋은 인덱싱 및 슬라이싱이 불가능하다. 대신 모델의 학습 및 평가에서의 사용을 위해 노드 수준의 attribute인 mask가 추가된다. 예를 들어, 1번째 노드를 학습에 사용하려면 train_mask에서 1번째 값을 1로, 그렇지 않으면 0으로 지정하여 해당 노드를 학습 또는 평가, 검증에서만 사용되도록 하는 것이다.
data.train_mask.sum().item()
>>> 140
data.val_mask.sum().item()
>>> 500
data.test_mask.sum().item()
>>> 1000기본적으로는 학습과 검증, 평가를 위해 각각 140개, 500개, 1000개의 노드가 사용되도록 mask가 지정되어 있는 것을 확인할 수 있다.
1.3. 미니배치
추가적으로 PyG는 torch_geometric.loader.DataLoader를 통해 데이터를 배치 단위로 분할하여 불러오는 기능을 지원한다.
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoader
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)위 코드는 dataset으로 초기화한 ENZYMES 데이터셋을 DataLoader를 이용해 batch_size를 32로 설정하여 불러온다.
for batch in loader:
batch
>>> DataBatch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32])
batch.num_graphs
>>> 32loader에 불러진 데이터는 DataBatch 타입으로, 각 배치에는 batch_size로 설정한 32개 만큼의 그래프 데이터가 존재한다. 32개의 그래프가 존재하기 때문에 y의 크기도 [32]로 구성된다.
DataBatch의 x는 32개의 그래프를 구성하는 모든 노드의 feature 행렬을 표현하게 된다. 따라서 x만으로는 각 노드가 어느 그래프에 속하는지를 알기 어려워 추가적인 attribute로 batch가 존재한다. 이러한 batch는 열 벡터로 구성되어 각 노드가 속하는 그래프를 나타내게 된다.
1.4. 데이터 변환
이번에는 그래프가 아닌 데이터를 그래프로 만들어보려 한다.
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'])
dataset[0]
>>> Data(pos=[2518, 3], y=[2518])ShapeNet 데이터셋으로부터 비행기(Airplane) 카테고리의 데이터를 불러오면, 3차원 좌표를 갖는 2518개의 점을 불러올 수 있다.
이 점들을 노드로 간주하고 K=6인 K-nearest neighbor 그래프로 데이터셋을 불러올 수도 있다.
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],
pre_transform=T.KNNGraph(k=6), # pre_transform 추가
transform=T.RandomJitter(0.01)) # transform 추가
dataset[0]
>>> Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])앞서와 달리 Data 타입의 객체에 edge_index가 추가된 것을 확인할 수 있다. transform을 추가하여 불러온 데이터를 추가적으로 증강하는 것 또한 가능하다.
1.5. 그래프 학습 방법
PyG를 이용하여 Cora 데이터셋을 학습해보자. 학습시키는 신경망으로는 GCN 레이어를 이용한다. 전반적인 과정은 기존의 파이토치와 유사하다.
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='/tmp/Cora', name='Cora')
>>> Cora()우선 Cora 데이터셋을 불러온다.
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(dataset.num_node_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)그 다음엔 모델을 구성한다. PyG에서는 GCNConv라는 이름으로 GCN 레이어가 구현되어 있으며 GCN 외에도 여러 레이어가 구현되어 있다. 이를 이용해 2개의 GCN 레이어를 만들고, forward() 메소드를 통해 모델의 흐름을 구현한다. 그래프 신경망의 특성 상, 레이어에 노드 feature 행렬(x)와 연결 정보(edge_index)가 입력되는 것을 확인할 수 있다. 비선형 활성함수로는 ReLU를 사용하였고 softmax 함수로 분류를 진행한다.
이렇게 구성한 모델에 대해 epoch를 200으로 하여 학습을 진행하고 평가한다. 학습 및 평가에는 Cora 데이터셋에서 지정된 mask에 따라 데이터를 구분하여 사용한다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
model.eval()
pred = model(data).argmax(dim=1)
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')
>>> Accuracy: 0.8150