1. GNN 파이프라인
앞서 GNN 모델을 구성하는 요소들을 정리하였다. 이를 모델의 파이프라인으로 나타내면 다음과 같다.
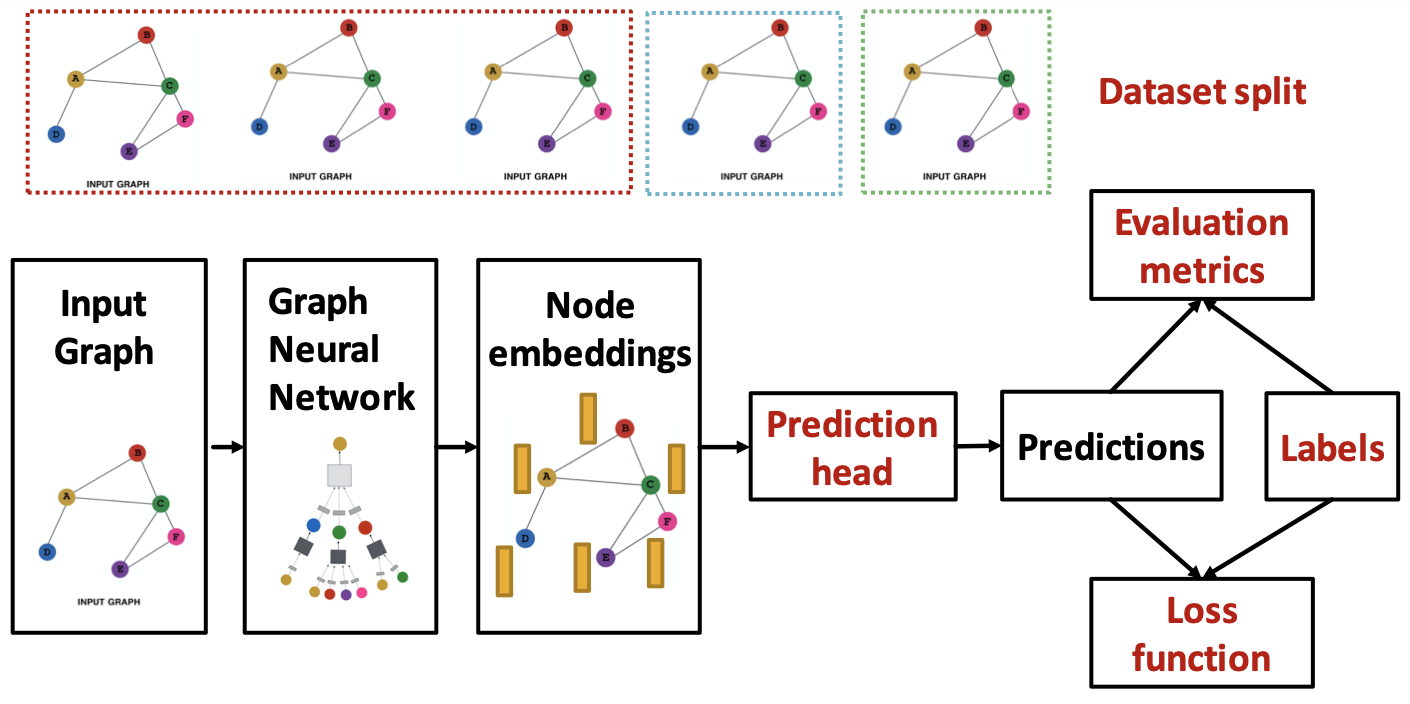
모델은 그래프 데이터를 입력하여 레이블을 기준으로 예측을 수행하는 방향으로 진행된다. 이러한 전반적인 흐름은 크게 두 부분으로 나눠 볼 수 있다. 먼저 입력 그래프로부터 노드 임베딩을 연산하는 부분이 있고, 이렇게 산출된 노드 임베딩으로 분류와 같은 특정 task를 수행하는 부분이 있다. GNN 모델에서 특징적인 부분은 노드 임베딩을 연산하는 앞 부분이다. 앞서서는 이 부분을 구성하는 요소들에 대해 알아봤다면, 이번에는 다른 관점으로 접근한다.
2. GNN의 표현력
우선 GNN을 지칭하는데 있어, 전체 모델 내에서 노드 임베딩을 연산하는 부분으로 그 범위를 제한한다. 여기서 입력된 그래프 데이터는 GNN 레이어들을 통과하여 노드 임베딩으로 변환된다.
2.1. 노드 임베딩과 표현력
개의 feature를 갖는 개의 노드로 구성된 그래프에 대해, 입력 데이터는 feature matrix (또는 이전 레이어가 산출한 임베딩 matrix )와 adjacency matrix 를 말한다. 각각은 그래프를 구성하는 각 노드의 feature와 그래프의 구조를 나타낸다. GNN 레이어는 이러한 요인들을 함께 반영하여 노드 임베딩을 출력한다. 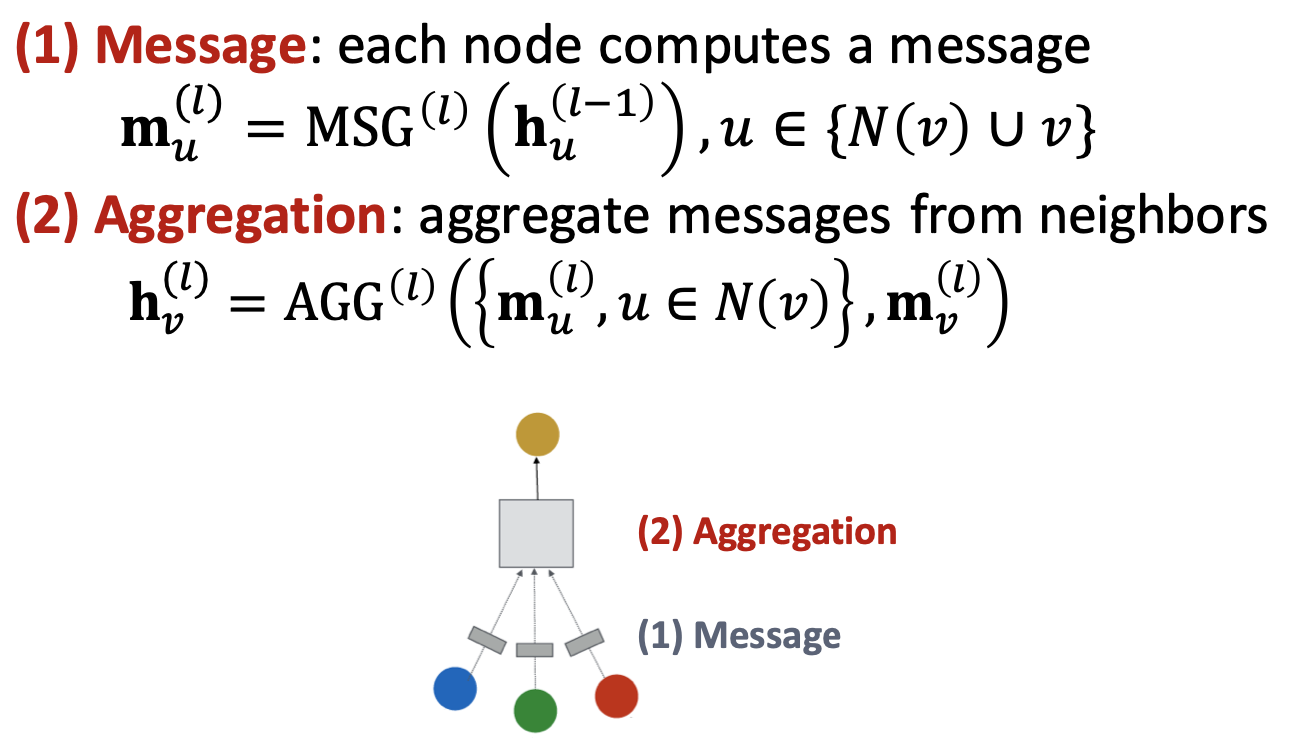
일반적으로 딥러닝 모델에서 표현력은 와 사이에 존재하는 관계, 즉 함수를 표현하는 능력을 말한다. 표현력이 높다면 더 다양한 관계를 반영할 수 있다. 반대로 표현력이 낮다면 다른 를 갖게하는 관계를 표현하지 못해 다른 를 갖는 에 대해서라도 같은 를 출력하게 된다.
GNN에서의 표현력은 노드 임베딩이 해당 노드를 얼마나 잘 표현할 수 있는지를 의미한다.
이와 관련해서 다음과 같은 그래프를 예로 들어보자. 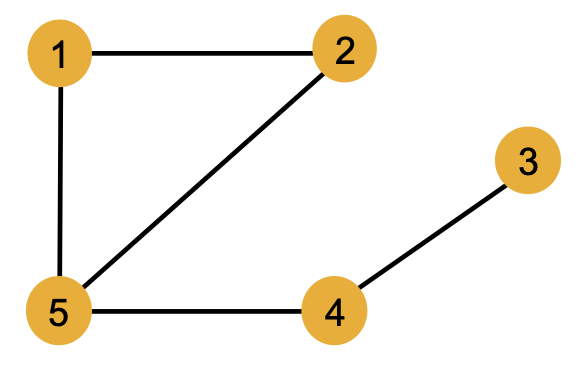
5개의 노드들이 undirected 엣지로 연결된 위 그래프에서 노드의 색상은 노드가 갖는 feature를 나타낸다. 1번부터 5번까지 서로 다른 노드들이지만 모두 노랑색으로 동일한 feature를 갖고 있음을 알 수 있다. 이러한 그래프에서는 서로 다른 노드들을 구별하기 위해 다음과 같이 이웃 구조를 활용할 수 있다.
(1) 이웃한 노드 수
: 노드 1 (2) vs. 노드 5 (3)
(2) 이웃 노드가 이웃한 노드 수
: 노드 1 (2, 3) vs. 노드 4 (1, 3)
하지만 이웃 구조만으로는 구별이 어려운 경우도 존재한다. 노드 1과 노드 2는 모두 2개의 노드와 이웃하며, 이웃한 2개의 노드들은 동일하게 각각 2개와 3개의 노드와 이웃한다. 이웃의 hop을 늘리더라도 두 노드의 2-hop과 3-hop 이웃 노드는 노드 4와 노드 3으로 동일하다. 이처럼 feature가 같은 두 노드가 이웃 구조도 완벽히 일치한다면 추가적인 정보 없이 두 노드를 구별하는 것은 어렵다.
이를 GNN으로 구한 노드 임베딩의 관점에서 접근하면, 노드 임베딩은 해당 노드를 표현하는 벡터이기 때문에 임베딩 결과를 통해 노드의 구별이 가능하다고 할 수 있다. 이러한 노드 임베딩의 연산에는 그래프의 구조적 특성이 반영되기 때문에, 같은 feature를 갖더라도 다른 이웃 구조를 갖는 노드들은 다르게 임베딩된다고 예상할 수 있다(1). 또한, 반영하는 이웃의 범위에 따라 달라질 수도 있다(2). 이처럼 GNN에서의 표현력은 노드 임베딩이 그래프의 다양한 구조적 특성을 얼마나 구별할 수 있는지로 해석된다.
2.2. 계산 그래프
노드 임베딩의 그래프 구조 구별 능력은 GNN이 노드 임베딩에 그래프 구조를 반영시키는 방법을 통해 파악될 수 있다.
GNN의 각 레이어에서는 이웃 노드들로부터 임베딩을 하나로 모아 타겟 노드의 임베딩을 구한다. 위의 그래프에 대해 2개의 레이어로 노드 1과 노드 2의 임베딩을 구하는 과정은 다음과 같이 그래프의 형태로 표현될 수 있으며, 이를 계산 그래프라 한다. 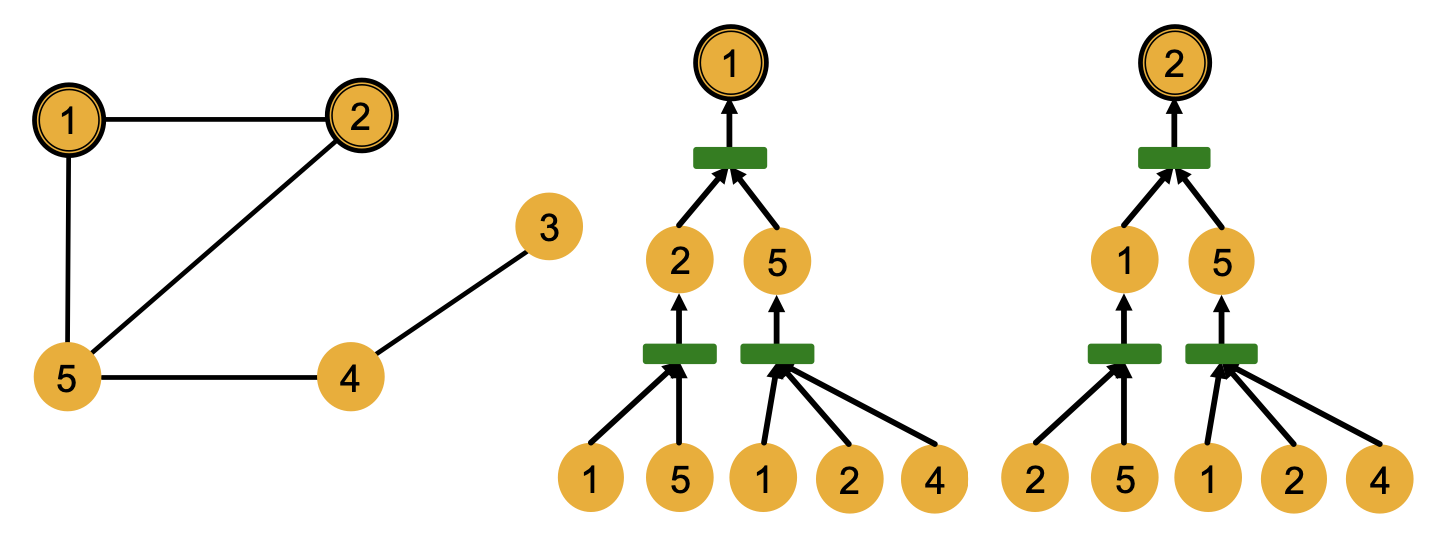
노드 1의 임베딩 연산을 살펴보면, 아래부터 첫 번째 레이어에서는 이웃 노드인 노드 2와 노드 5의 임베딩을 구하기 위해 각각의 이웃 노드들로부터 임베딩을 모으는 연산을 진행한다. 이후 두 번째 레이어에서는 노드 2와 노드 5의 임베딩을 하나로 모아 노드 1의 최종 노드 임베딩을 구한다.
이 과정에서 정보는 노드의 feature만이 사용되고 노드 번호와 같은 id는 사용되지 않는다. 따라서 계산 그래프에서 번호를 지우면 두 노드의 계산 그래프가 일치함을 확인할 수 있다. 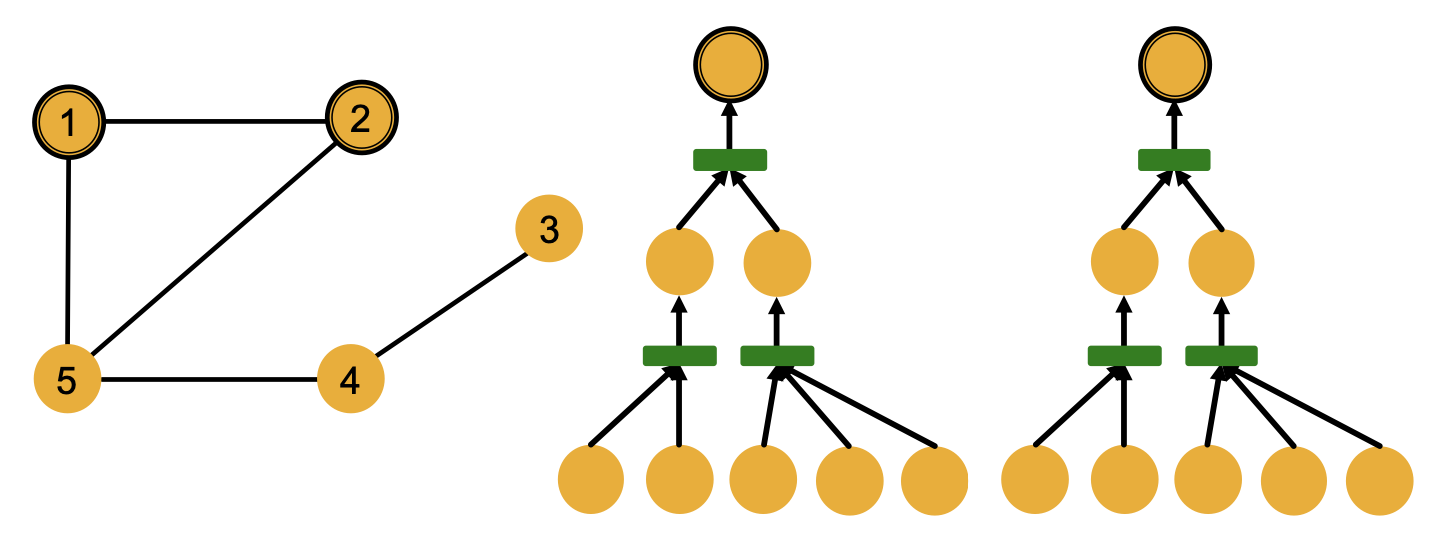
이러한 계산 그래프는 노드의 이웃 구조에 기반하여 정의되고 GNN은 이를 통해 연산을 진행함에 따라 노드 임베딩에 이웃 구조를 반영하게 된다. 따라서 위처럼 동일한 계산 그래프를 갖는 노드들은 동일하게 임베딩되어 구별할 수 없다.
물론, 이웃 구조가 다른 노드들은 다른 계산 그래프를 갖는다. 위 그래프에서 각 노드들의 계산 그래프를 나타내면 다음과 같다.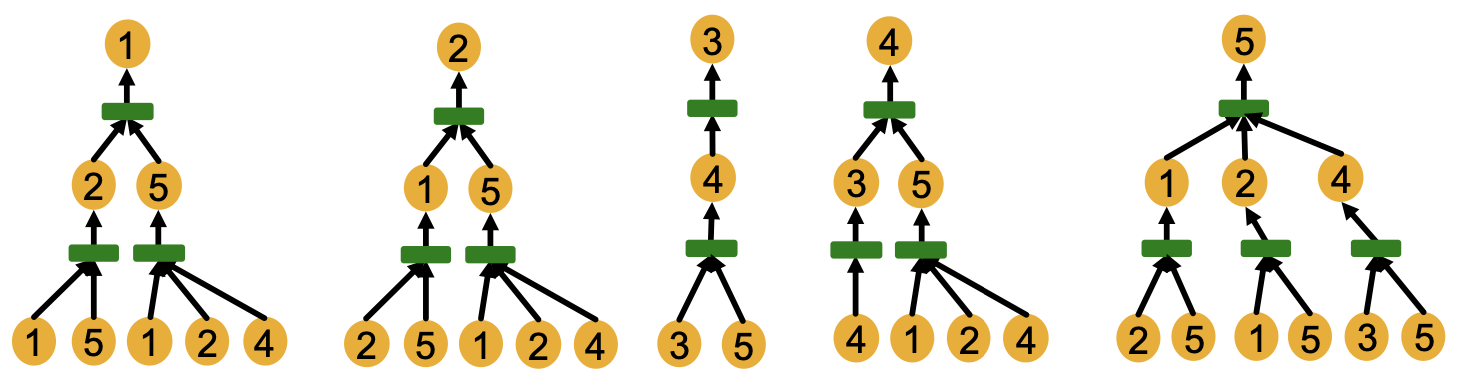
결국 GNN의 표현력에 있어 중요한 것은 형태가 다른 계산 그래프들로부터의 임베딩 결과가 임베딩 공간 상에서 다른 지점에 위치되게끔 하는 것에 있다.
2.3. 단사 함수(injective function)
다른 계산 그래프들을 임베딩 공간 상에서 다른 지점에 위치시킬 수 있는 방법은 꽤 간단하다. 임베딩 과정이 계산 그래프를 벡터로 변환하는 일종의 함수로 본다면 이를 단사 함수로 구현하면 된다. 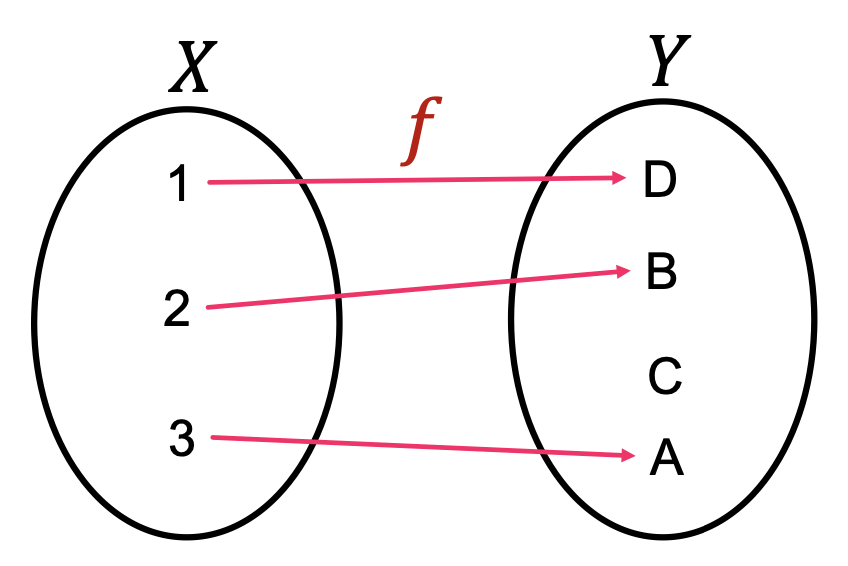
단사 함수는 정의역의 서로 다른 원소를 공역의 서로 다른 원소로 대응시키는 함수이다. 같은 를 입력하면 같은 를 출력하지만, 다른 에 대해서는 항상 다른 를 출력하는 것이다. 이는 공간 상에서의 정보가 공간으로 맵핑될 때 소실되지 않는다고도 해석할 수 있다.
이러한 단사 함수의 성질을 이용하면 형태가 다른 각각의 계산 그래프들을 항상 임베딩 공간 상에서 다른 지점에 위치시키는 것이 가능해진다.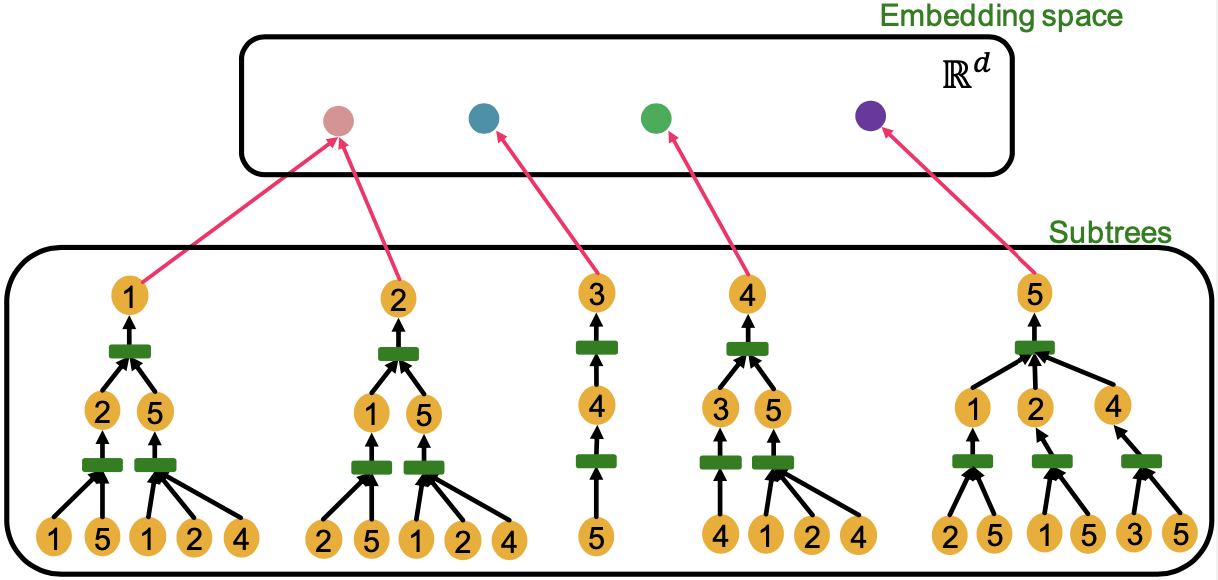
구체적인 구현은 GNN 레이어의 aggregation function을 통해 이뤄질 수 있다. 계산 그래프를 따라 정보가 전달되는 과정에서 각 레이어에서는 이웃 노드들의 정보인 임베딩을 모으게 된다. 여기서 적용되는 aggregation function이 이웃 노드들의 정보를 소실하지 않고 다음 레이어로 정보를 전달한다면, 계산 그래프의 가장 상단에 위치한 타겟 노드의 임베딩에는 하단에 위치한 이웃 노드들의 정보가 보존되어 전달될 수 있는 것이다.
따라서 각 레이어에서 이웃 노드의 임베딩을 모으는 연산을 단사 함수로 구현하면, 이러한 레이어를 연속적으로 쌓인 모델도 단사 함수의 성질을 갖게 되는 것이다. 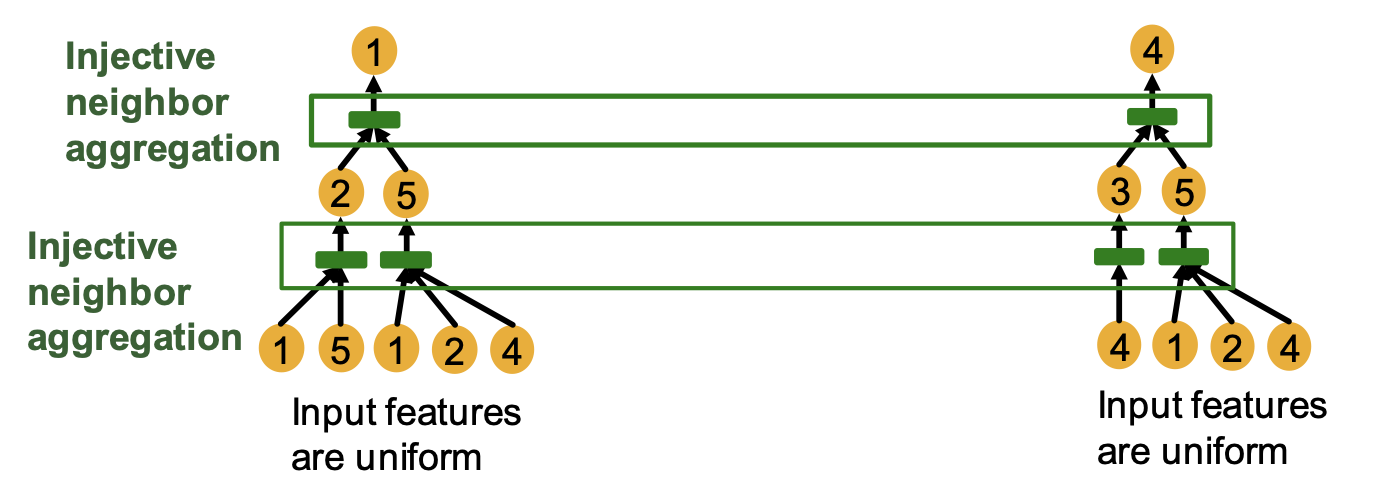
2.4. Aggregation function
돌고돌아 결국 GNN의 표현력을 결정하는건 레이어를 구성하는 aggregation function이다. 각 레이어의 aggregation 연산의 표현력이 좋을수록 전체 모델의 표현력도 증가하며, 단사 함수의 성질을 갖도록 구현되었을 때 표현력이 가장 좋다고 할 수 있다.
그렇다면 앞서 다뤄졌었던 GNN 모델들을 다시 가져와서, GCN과 GraphSAGE은 표현력이 좋은 모델인지 aggregation function을 통해 확인해보자.
먼저 GCN의 aggregation function은 평균(mean-pool)이 사용되었다.
그러나 평균은 입력되는 집합이 다르더라도 그 집합을 구성하는 원소의 비율이 같다면 같은 값을 출력한다. 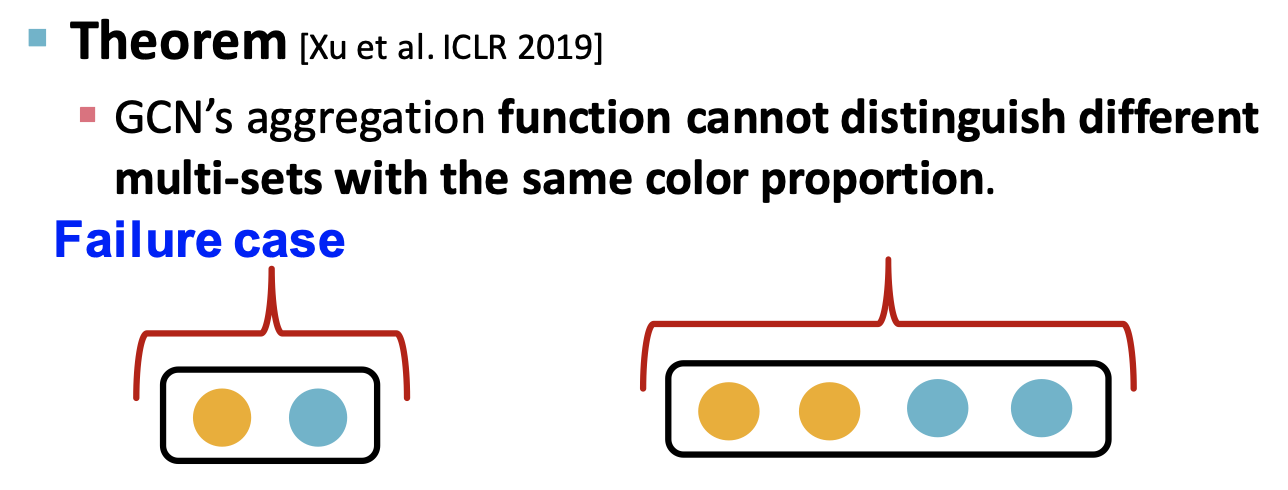
예를 들어 각각 2개와 4개의 노드와 이웃하는 임의의 노드 A와 B가 있다고 하자. 노드 A는 노랑색 노드 1개, 파랑색 노드 1개와 이웃하며, 노드 B는 노랑색 노드 2개, 파랑색 노드 2개와 이웃한다면, 평균을 이용하여 두 노드 각각을 aggregation한 결과는 같다.
GraphSAGE는 평균과 최댓값, 합이 모두 사용 가능한데 최댓값(max-pool)을 가정해보자.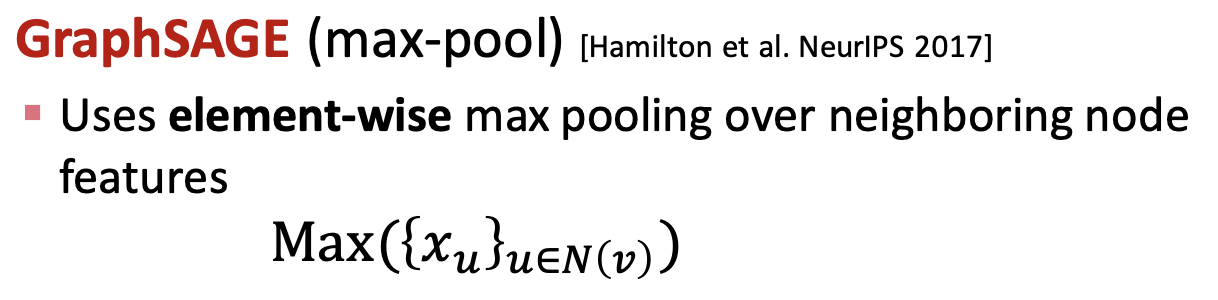
이 경우에는 가장 큰 값만 이용하기 때문에, 이웃 노드 집합을 구성하는 원소의 개수에 따른 구분이 불가능하다.
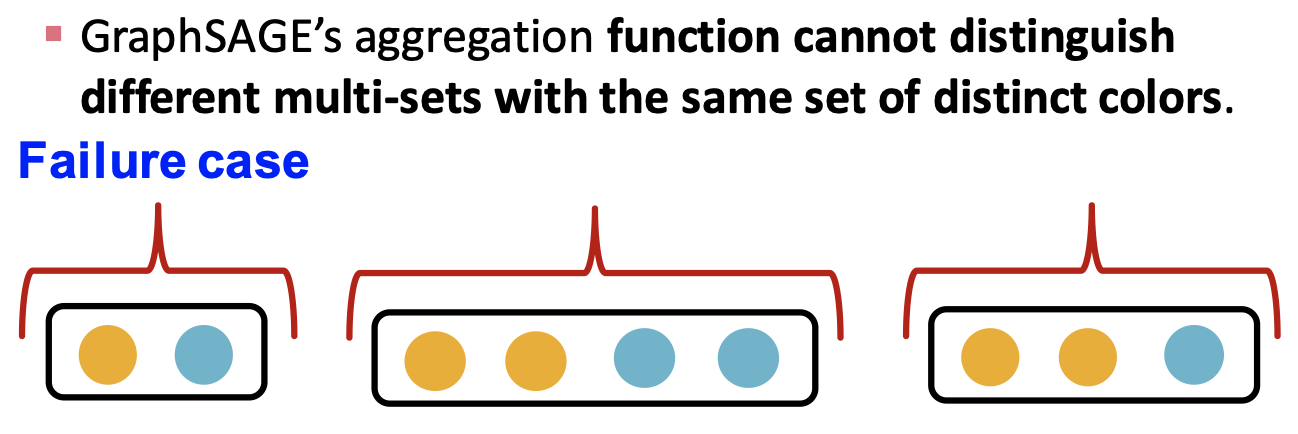
예를 들어 노랑색 노드와 파랑색 노드가 이웃 노드에 있다면, 최댓값을 이용한 aggregation에서는 각각의 개수는 구분할 수 없고 유무만을 구분하게 된다.
따라서 GCN과 GraphSAGE는 aggregation의 방식이 구분할 수 없는 몇몇 상황이 존재함에 따라 표현력에 있어 가장 강력한 모델로는 볼 수 없다.
3. Graph Isomorphism Network (GIN)
이제부터는 가장 강력한 표현력을 갖는 모델을 만들어보자. 이를 위해서는 aggregation function을 단사 함수의 형태로 구현하면 된다고 했었다. 말은 쉽지만 이웃 노드 집합의 가능한 모든 분포에 대해 각각 다른 값을 출력해야 하기 때문에 직관적이지는 않다.
3.1. Neighbor aggregation part of GIN
이에 따라 Xu et al. ICLR 2019은 다음과 같은 정리를 제시하였다.
는 이웃 노드로 이뤄진 집합이다. 각 이웃 노드들에 대해 비선형 함수인 를 통과시켜 얻은 결과를 모두 더한 후, 그 값을 다시 다른 비선형 함수인 에 통과시킨다. 이러한 정리를 이용하면 단사 함수의 표현이 가능해진다.
근데 그렇다고 해서 아무 비선형 함수를 와 로 사용할 수는 없다. 다만, Hornik et al., 1989이 제시한 Universal Approximation Theorem에 따르면, 어떠한 연속 함수라도 1개의 hidden 레이어로 구성된 MLP를 통해 근사가 가능하다.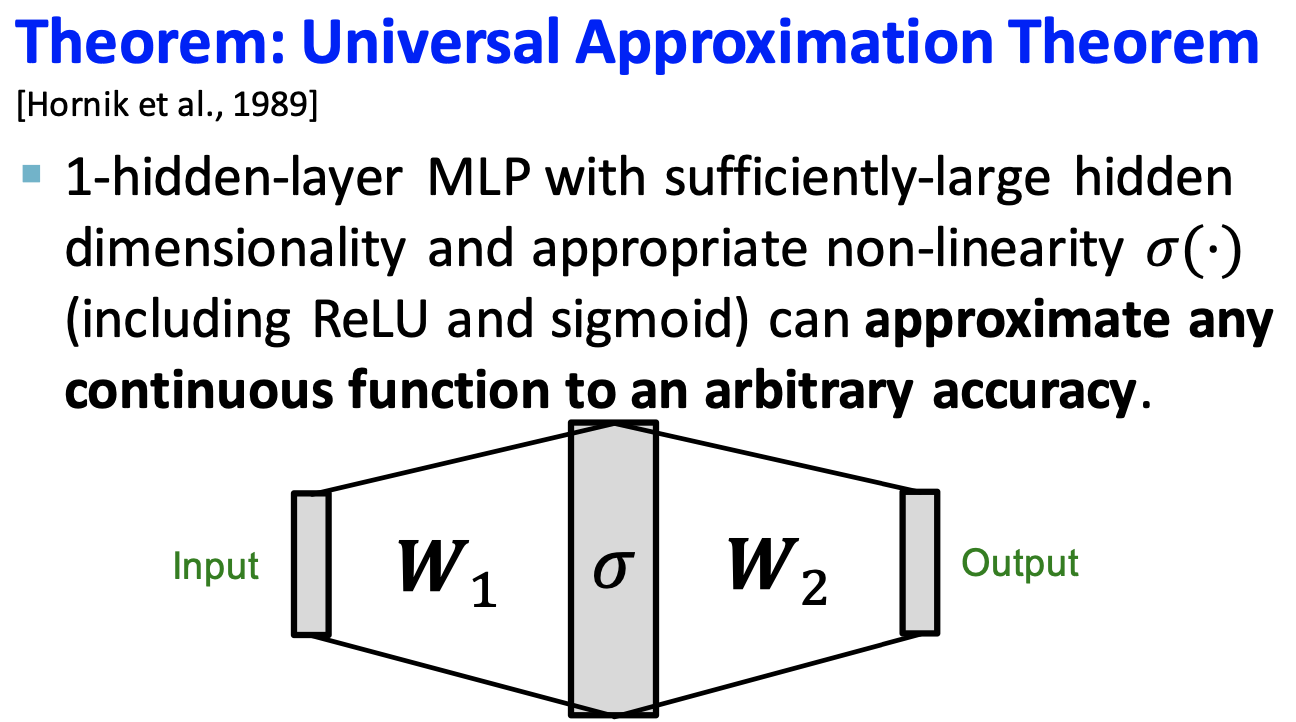
따라서 이러한 정리들을 이용하면 aggregation function을 다음과 같이 나타낼 수 있다.
GIN은 위의 함수를 aggregation function으로 사용한다. 앞선 정리에 근거하여 GIN의 aggregation function은 단사 함수이기 때문에 평균이나 최댓값과 달리 모든 경우에 대해 구별하는 것이 가능하다. 즉, GIN은 message-passing 기반 GNN 중 표현력이 가장 좋은 모델이다.
3.2. Full model of GIN
이러한 aggregation 방식을 바탕으로 GIN은 WL kernel과 유사하게 노드 임베딩을 계산한다.
WL kernel은 모든 노드에 초기 색상을 부여하고 해시 함수를 이용하여 각 노드의 색상을 업데이트 해나간다. 이를 수식으로 나타내면 다음과 같다.
해시 함수는 입력값이 바뀌면 결과가 바뀌도록 설계됨에 따라 단사 함수로서 기능하며, 번의 반복을 통해 계산된 에는 -hop 이웃의 구조가 반영된다.
GIN은 WL kernel에서 해시 함수를 신경망 로 구현한다. 해시 함수와 동일하게 입력값은 로 각각 타겟 노드의 feature와 이웃 노드들의 feature들을 의미한다. 입력값들을 위에서 정의한 단사 함수 형태의 aggregation function으로 맵핑하여 노드 임베딩을 연산한다. 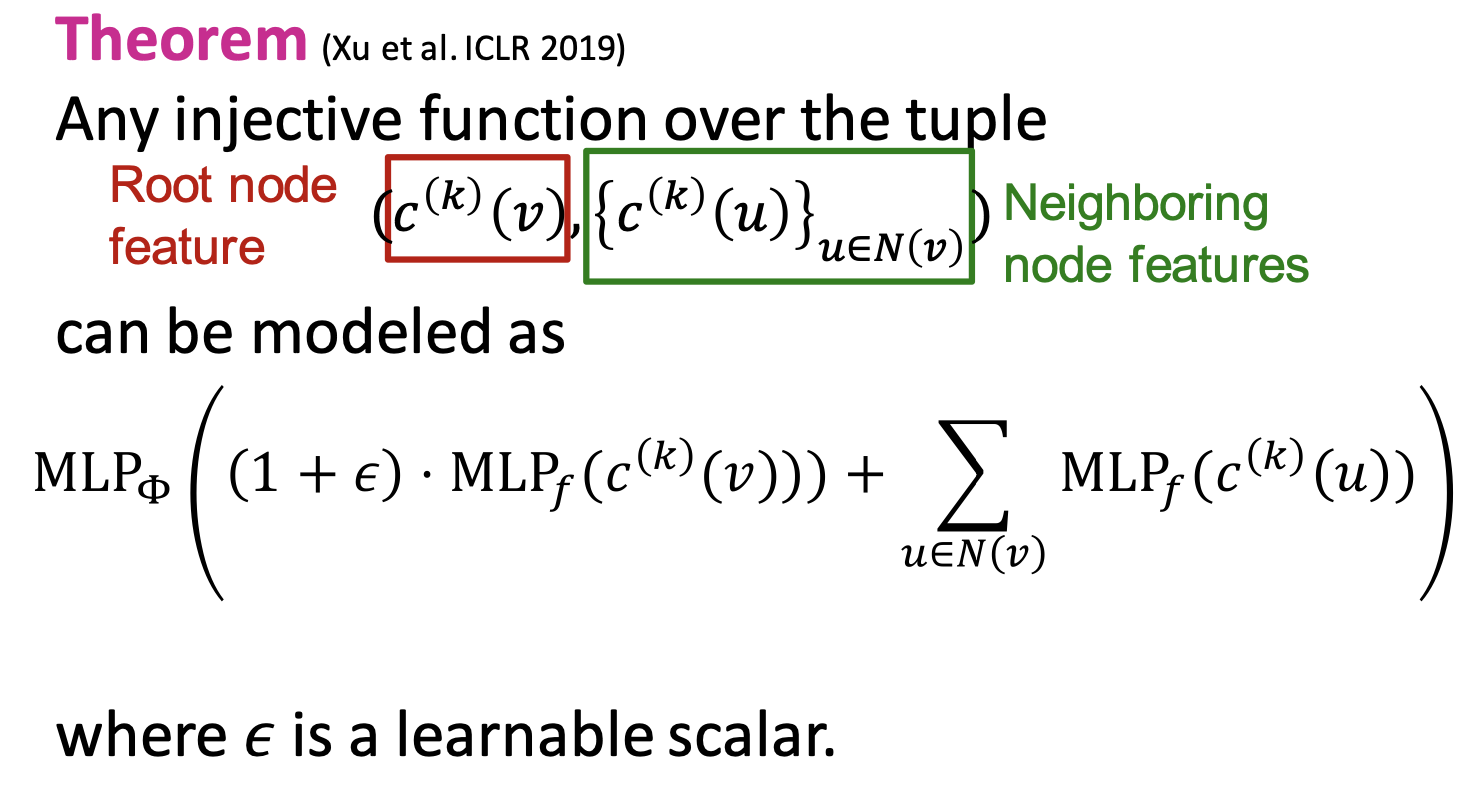
WL kernel은 이미 현실 세계의 대부분의 그래프를 구별할 수 있음이 확인되었다. GIN은 WL kernel을 일부 수정하여 근사한 형태로 구성되기 때문에 두 방식의 표현력은 완전히 같다. 따라서 GIN은 WL kernel처럼 현실 세계의 대부분의 그래프를 구별할 수 있을만큼 좋은 표현력을 갖게 된다.
