굉장히 간단하면서도 재밌는 아이디어를 가진 논문이다.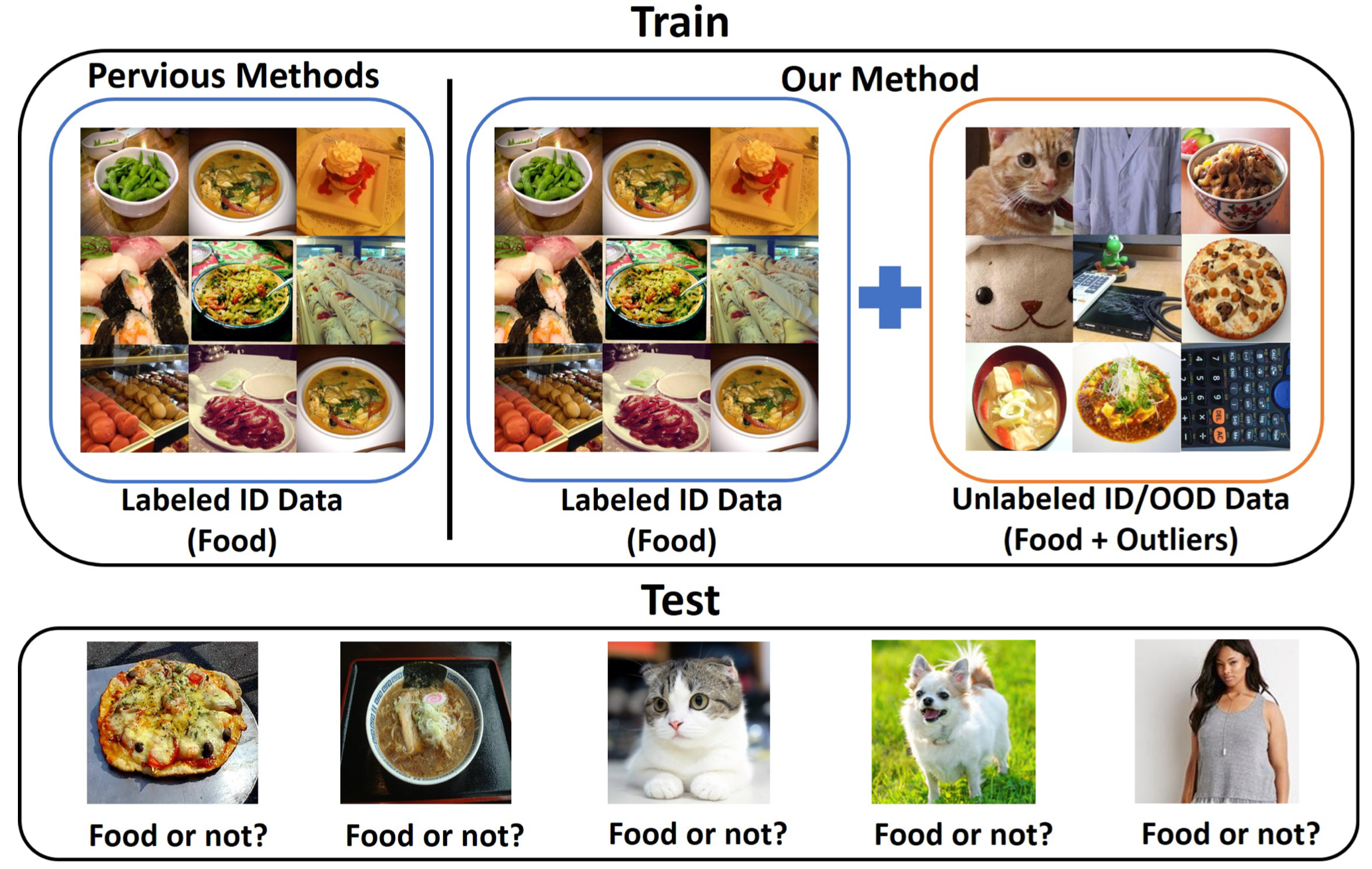
여느 논문들과 같이 이 논문도 Out-of-Distribution을 어떻게 하면 잘 잡을 수 있을지에 대한 방법을 다룬 논문이다.
논문에서 가장 핵심 아이디어는 다음과 같다.
- 먼저 가장 기본적으로 사용되는 OOD 방법처럼 Confidence를 이용한다
- 이 때 보통 OOD에 대한 Confidence값이 ID보다 작다 (ID로 훈련하니까 당연함)
근데 이 논문에서는 굉장히 재밌게 이 문제를 푸는데 바로 모델의 Feature Extractor에서 , 두개의 Classifier Network로 나눈 뒤에 이 두 Classifier의 Softmax값을 비교함으로써 문제를 해결했다.
이 때,저자들의 주장은 다음과 같다.
- The two classifiers having different parameters will be confused and output different results.
- Consequently, as shown in the lower left part of Fig.2, OOD samples will exist in the gap of the two decision boundaries, which makes it easier to detect OOD samples.
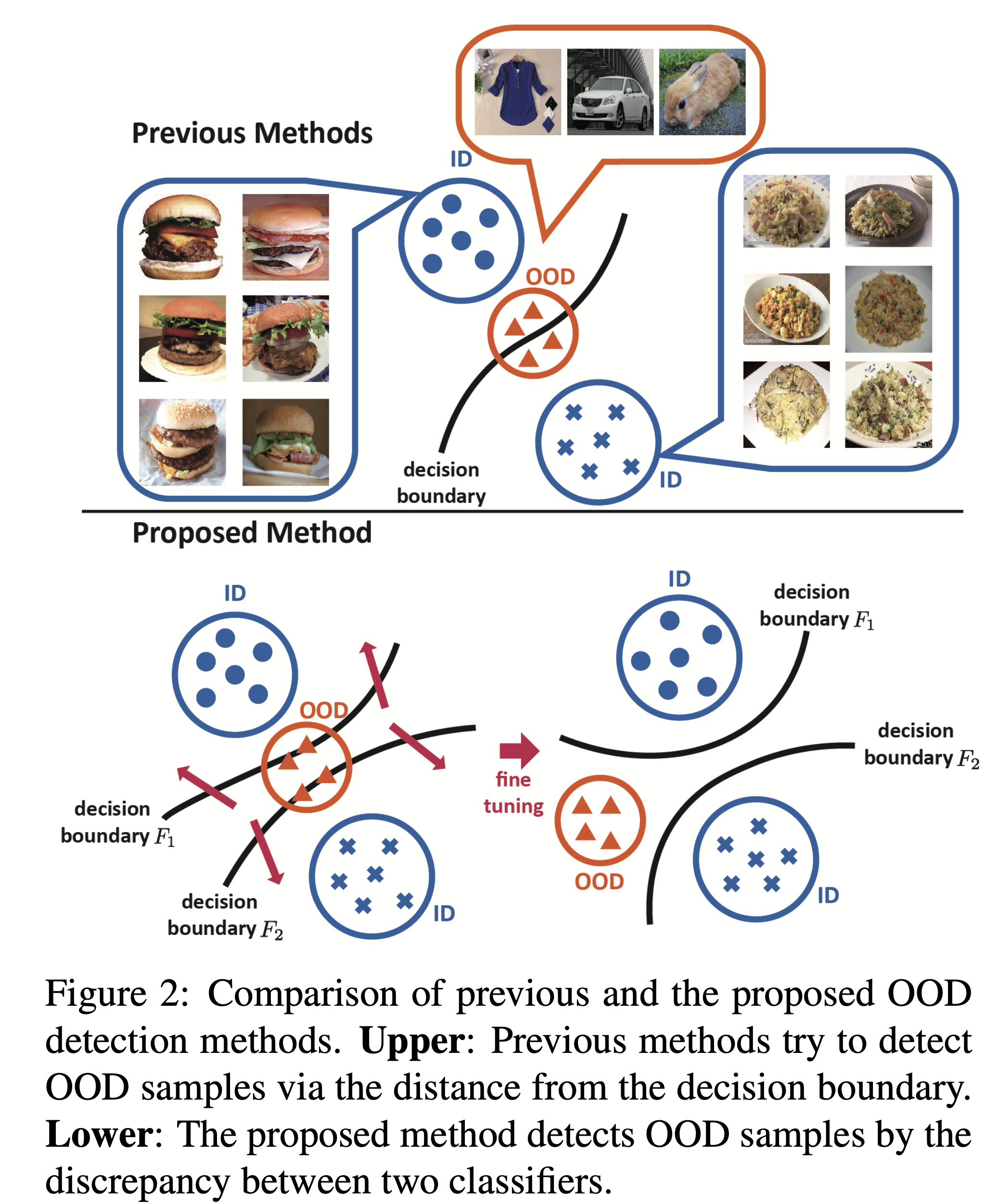
위 그림의 아래부분에서 볼 수 있는 것처럼, 두개의 Classifier에 대한 boundary가 당연히 완전히 같지는 않을 것이다(그림 왼쪽). 그렇다면, 어떤 입력에 대한 두개의 Classifier의 Softmax값 또한 다를것이다. 이 때, 만약에 Classifier에 같은 입력에 대한 Softmax값의 차이(discrepancy)를 크게 할 수록(fine tuning), 그림 오른쪽 처럼 OOD에 대한 차이가 확실해져서(discrepancy가 클것이다), 구분하기 쉬울 것이다. 라는 것이 이 논문 저자의 주장이다.
(일반적으로, 아무리 다른 network라고 해도, 같은 Feature extractor를 거친 classifier가 내놓는 Softmax값들의 차이가 처음보는 데이터 혹은 애매한 데이터보다 클 수가 없을 것임 이라는 것이 기저에 깔린 아이디어)
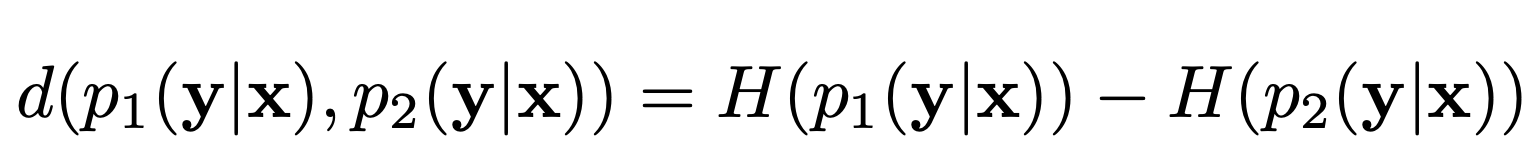
위 식이 두 Classifier의 Discrepancy를 구하는 공식이다. 두 Classifier의 Softmax값에 : 엔트로피의 차이이다.
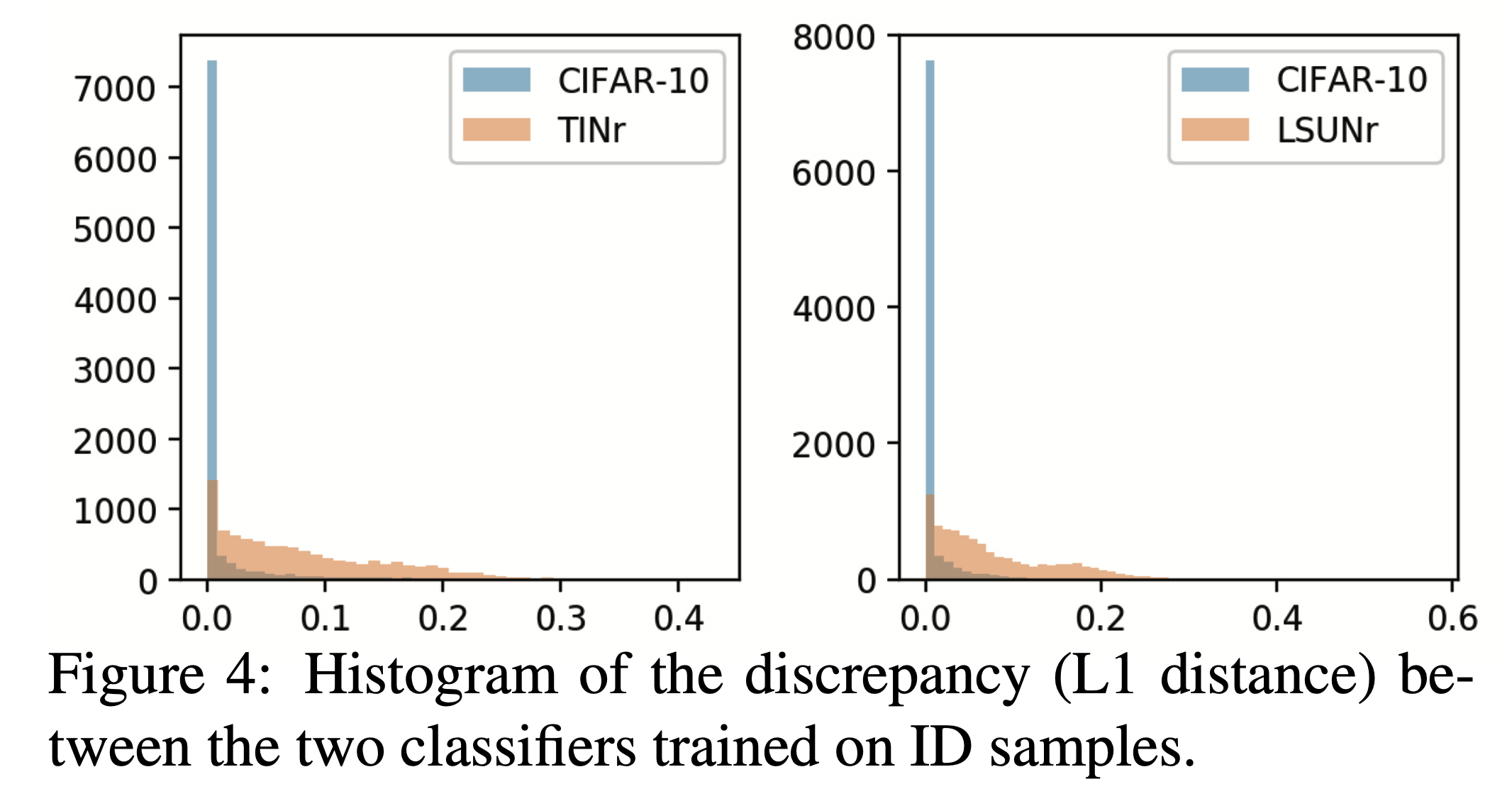
Figure.4를 보면 ID(CIFAR-10)와 OOD(TINr, LSUNr)의 두개의 Classifier에 대한 Discrepancy를 나타낸다. 확연히 CIFAR-10(pre-trained ID)같은 경우 두개의 Classifier가 낮은 모습을 볼 수 있고, 햇갈리는 데이터들 일부분이 매우 조금 차이가 나는 것을 확인할 수 있다.
반면에 OOD(TINr, LSUNr)을 두개의 Classifier에 넣어 Discrepancy를 구한 경우 확연히 차이나는 것을 볼 수 있다.
그러나 개인적으로, 이 둘의 차이가 그리 크지 않다고 생각되며, 이러한 점을 좀 보완할 수 있다면 좋지 않을까 싶다.
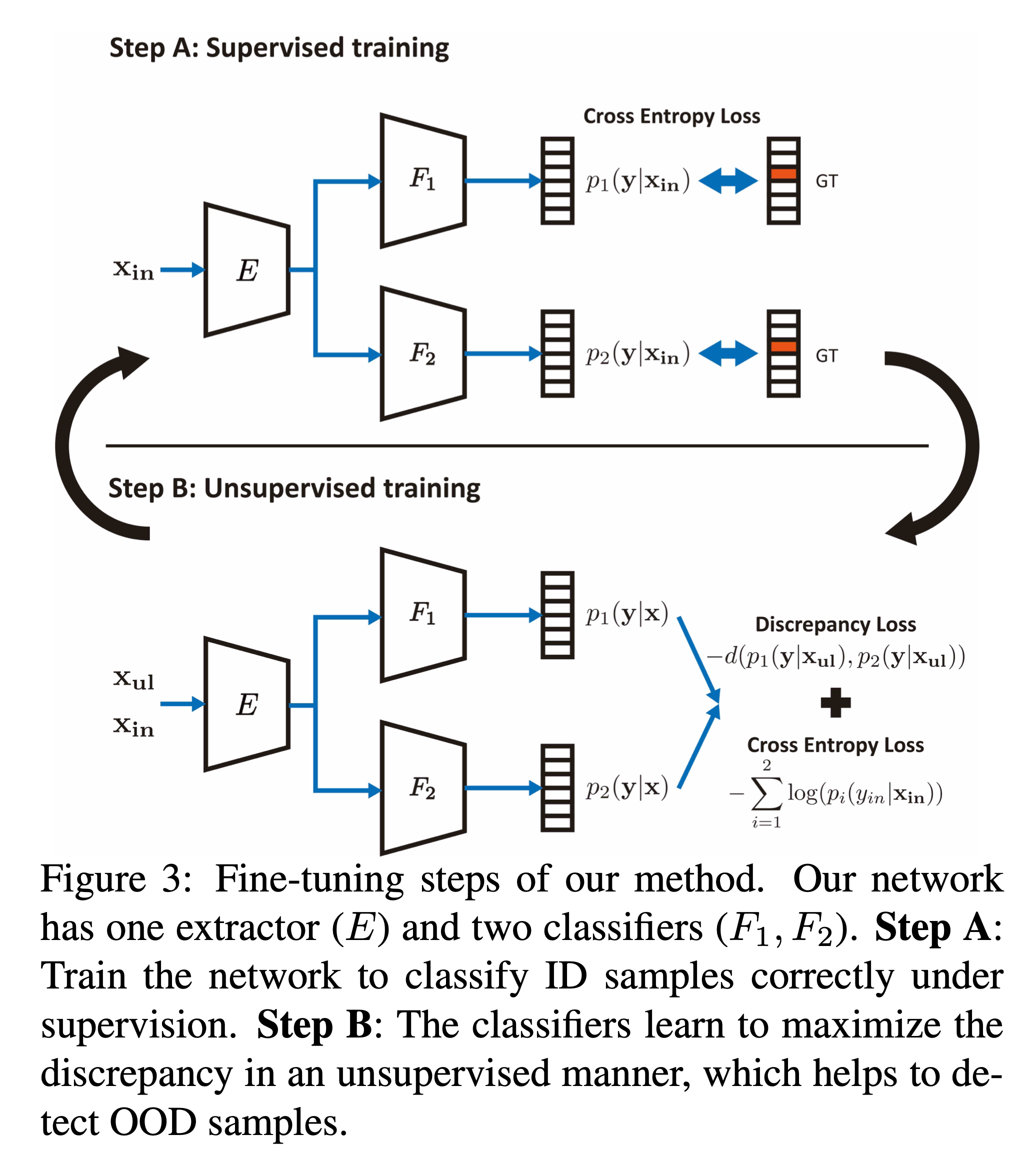
굉장히 재밌게 문제를 풀어낸다. ID samples에 대해서는 잘 분류하고, discrepancy는 크게 하기 위해서는, 하나의 pre-training Step과 두 단계(Step A 와 Step B)로 나눠진 fine-tuning Step을 반복하는 훈련을 진행한다. 가장 먼저, Discriminative features를 먼저 학습하고 ID samples를 잘 맞추기 위해서, labeled ID samples을 가지고 Supervised training을 진행한다. (Pre-training)
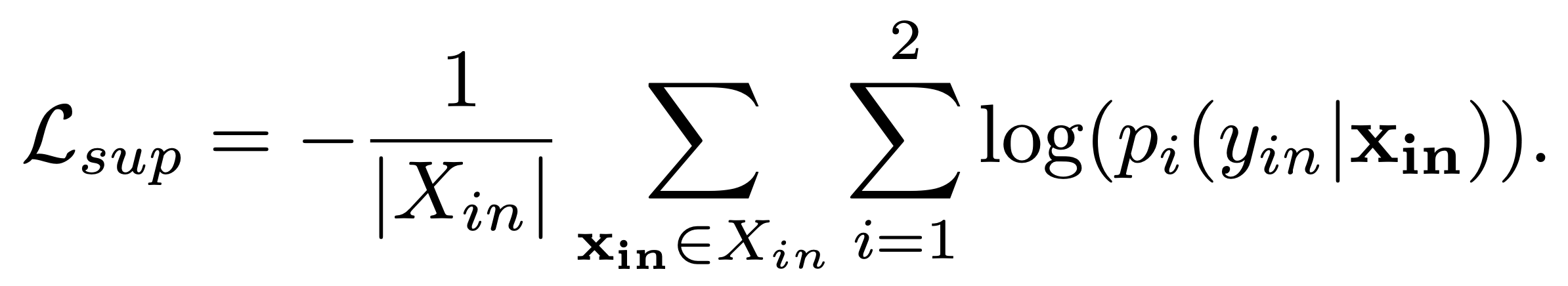
위 식은 Supervised training에서 사용되는 loss이다. 이러한 과정은 ID samples의 manifold를 유지하기 위함이다(manifold를 유지하기 위함이다에 대한 의미를 정확히 모름 확인 필요). 이는 성능을 향상시킴에 있어서 도움이 된다고 한다.
Fine-tuning
일단, 네트워크가 수렴했으면, OOD-samples를 잘 잡기 위해서 아래 두가지 steps들(위 그림)을 mini batch 단에서 반복하여fine-tune을 진행한다.
Step A
먼저, fine-tuning 과정이 진행되는 동안, 훈련 네트워크가 ID samples를 올바르게 분류하도록 해야한다.(Step A)
Step B
그러고나서, discrepancy가 unsupervised방식으로 증가하도록 만들어야 한다(Step B). 여기서
여기서는, unsupervised 방식을 이용해서, OOD 샘플을 잘 분류할 수 있도록 discrepancy를 maximize해준다.
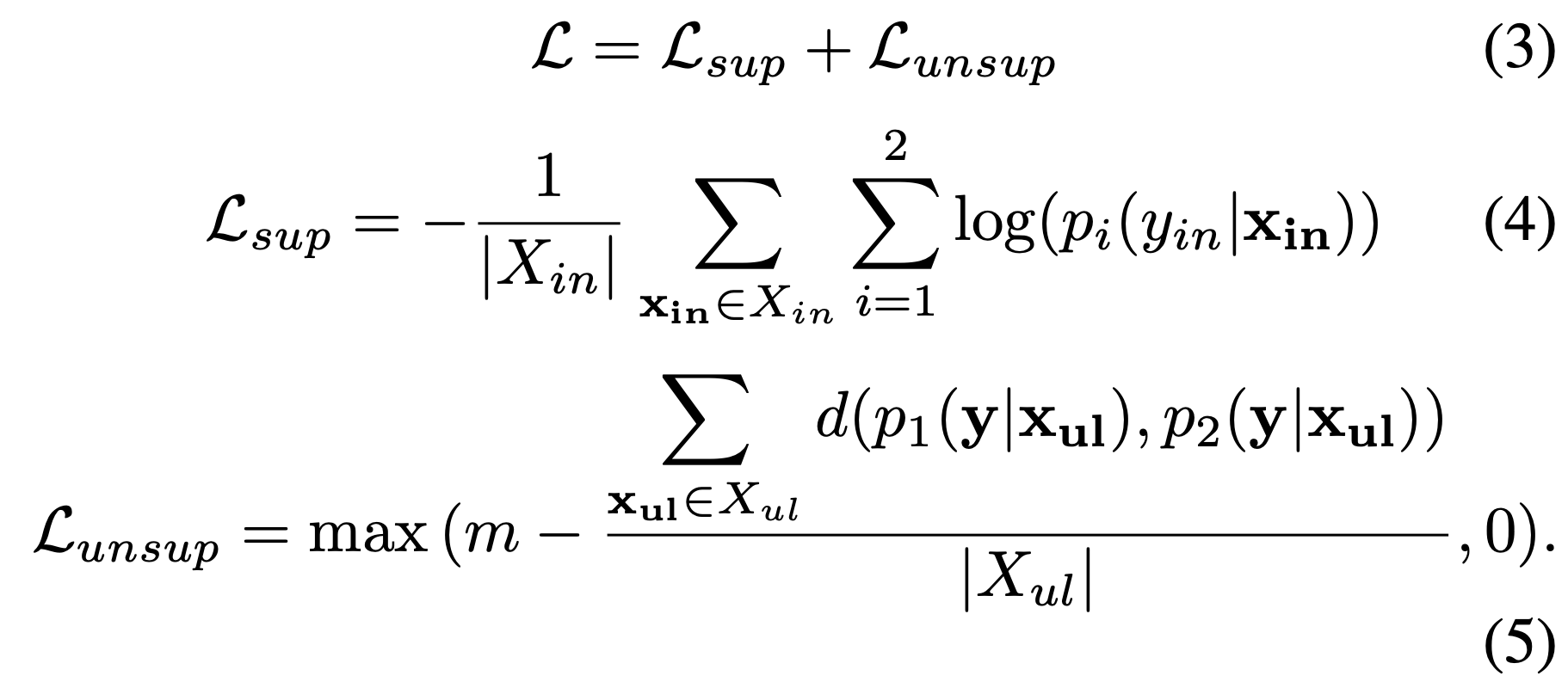
이건 코드좀 봐야 이해할 듯 싶다.
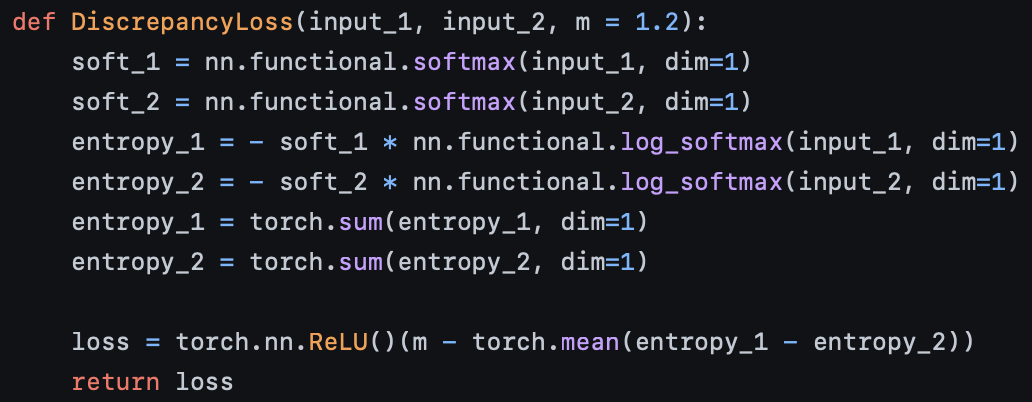
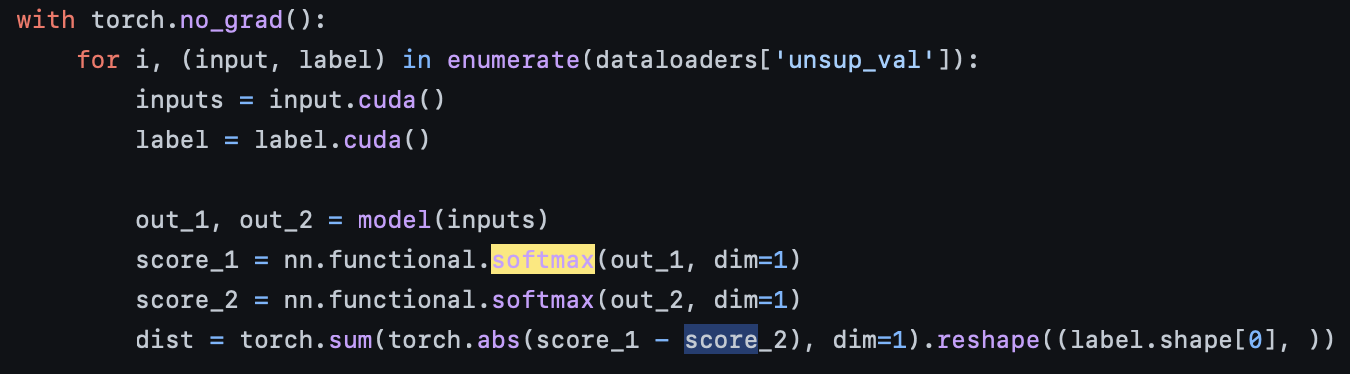
여기서 input_1와 input_2는 model(inputs)에서 나온 out_1과, out_2이다(즉, logit값). 이를 softmax를 통해 softmax distribution으로 만들어 준 다음, 이 값들을 log_softmax값을 취한 것들에다가 곱해준다. (이게 엔트로피 공식인 듯.) 그리고나서 F1의 엔트로피에서 F2의 엔트로피의 합을 빼주고, 평균값을 구해준다. 그런 다음, margin m을 둬서 overfitting을 방지한다.
Inference
직관적으로 OOD와 ID를 구분하기 가장 쉬운 방법은 위에 써있던 Discrepancy식을 사용하는 것이다. 그러나 그 식은 각 클래스의 discrepancy에 대해 포함되어 있지 않다. ㅇㅎ 그러면 온전히 이 아이디어를 쓰지 않으니까 이걸 어떻게 온전하게 사용할 수 있는지 한번 알아보면 좋을 것 같다.
저자들은 그래서 두 classifier의 output의 L1 distance를 통해 detection threshold를 주고 그것보다 크면 OOD, 아니면 ID라고 했다.
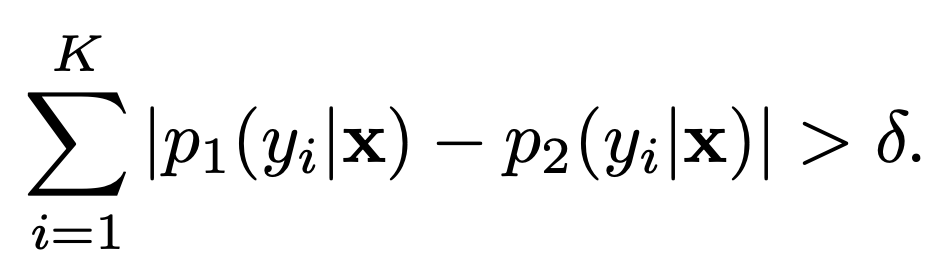
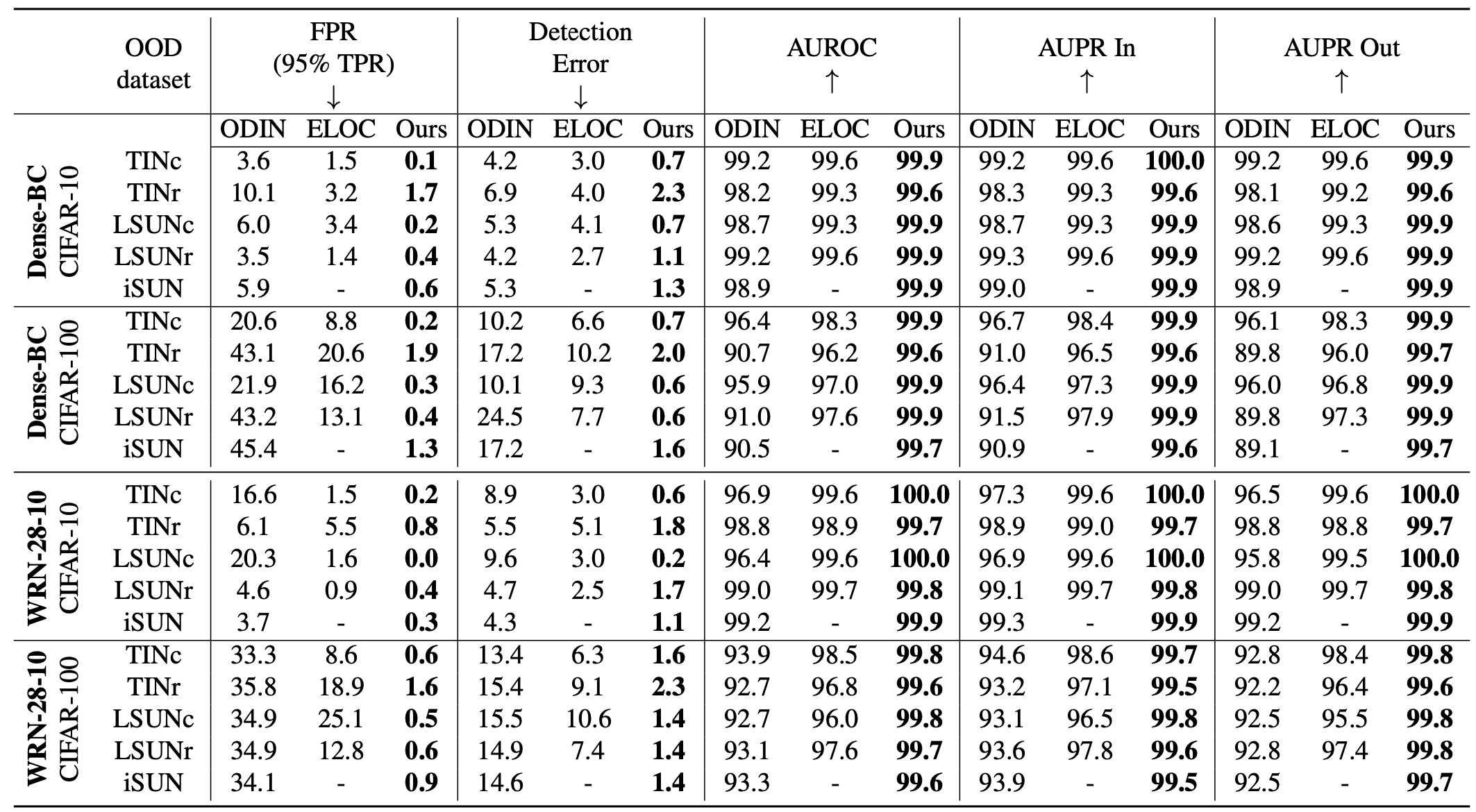
결과가 생각보다 엄청나다. 거의 모든 Out-of-Distribution을 잡는다.
