
✍ ERD (Entity Relationship Diagram)
ERD란 한국말로 직역하자면 개체-관계 모델로서 데이터베이스를 구축할 때 가장 기초적인 뼈대 역할을 하는 것으로 쉽게 풀이하자면 데이터들의 관계를 가시적으로 보다 간결하게 정의한 것입니다.
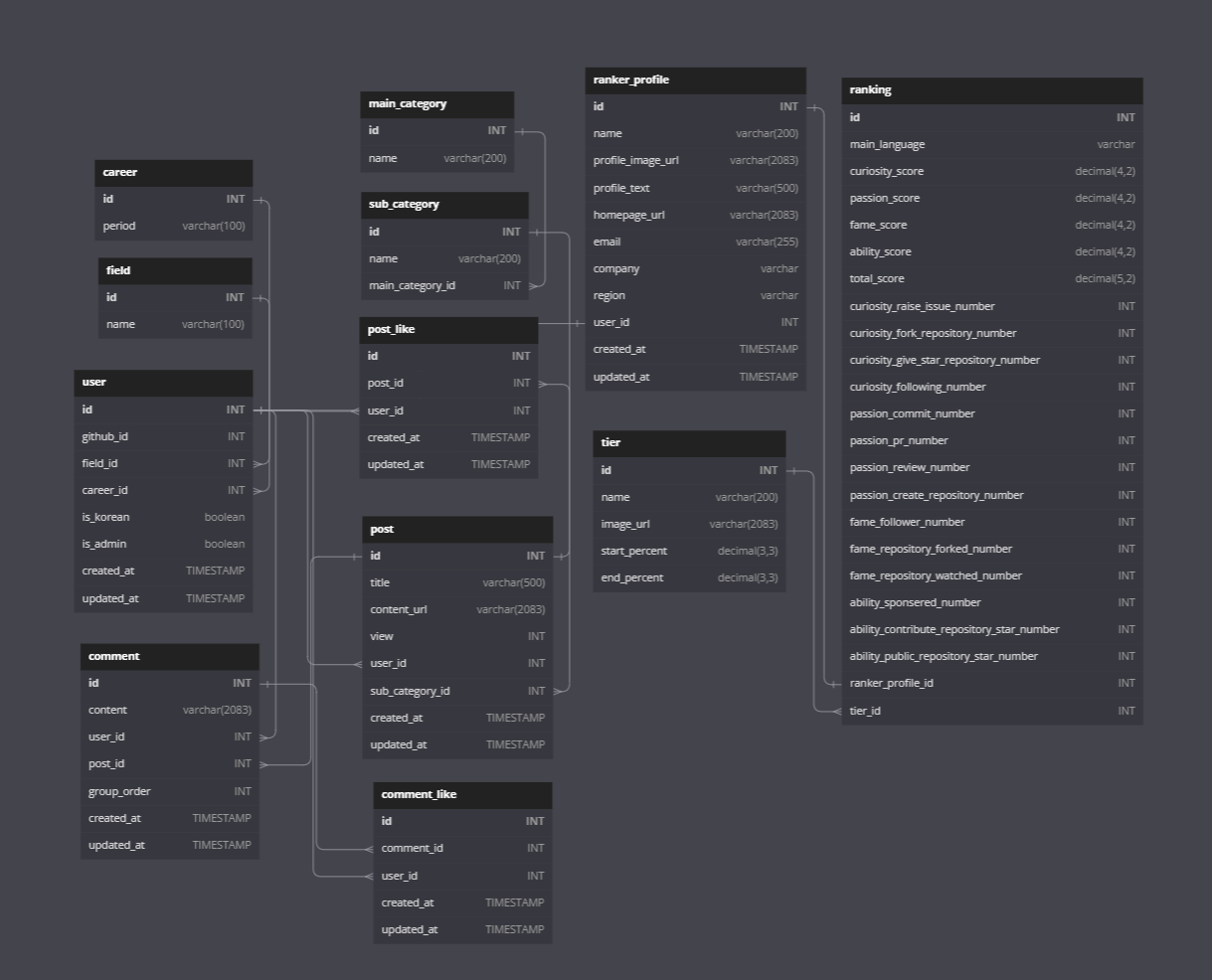
=> 위의 이미지는 실제 팀원들과 토이프로젝트를 하면서 만들었던 ERD이다.
📝 ERD의 필요성
-
데이터 모델의 가시화 : 시스템의 데이터 모델을 보다 명확하고 간결하게 가시화하여 개발자와 다른 부서의 동업자들이 엔티티, 속성, 그리고 시스템의 다른 요소들을 쉽게 파악할 수 있게 도와준다.
-
데이터베이스 설계의 청사진 역할 : ERD는 보통 정규화 작업이 진행되어 있는 상태이기 때문에 시스템에 필요한 청사진 역할을 하여 데이터베이스의 스키마를 생성하는데 보다 효율적이고 잘 구성되도록 도와준다.
-
협업 툴로써의 가치 : ERD는 일반적으로 개발자뿐만 아니라 다른 부서의 일원들도 쉽게 파악할 수 있게끔 간결한 언어로 작성되어있기 때문에 시스템의 요구사항과 설계를 이해하는데 큰 도움을 준다.
정리하자면, ERD는 개발자들이 DB를 설계하는데 있어 청사진 역할을 하며 개발자외의 부서들의 일원들과 의사소통을 쉽게 하게 하는 창구로서의 역할을 한다.
=> 경험상, 프론트와 백 모두 ERD를 제대로 파악하고 있으면 API DOCUMENTATION 자세하게 만들지 않아도 어떤 데이터가 어떤 방식으로 들어오는지 쉽게 파악이 가능하다.
📝 ERD의 특징 및 구성
-
엔티티 : ERD는 시스템 상에 있는 엔티티들의 관계를 나타내는데 집중되어 있다.
-
관계 : ERD 엔티티들의 관계를 1 대 1, 1 대 다, 다 대 다의 관계로 기호를 써서 나타낸다.
-
속성 : ERD는 각 각의 엔티티에 부여된 속성 값들을 보여주는데 대표적으로 이름, 크기, 그리고 데이터 형태 등이 있다.
-
기수 (Cardinality) : ERD는 기수를 사용해 엔티티의 인스턴스의 수 그리고 연결된 관계의 수를 나타낸다 (1:1, 1:N, N:N).
-
기본 키 (Primary Key), 외래 키 (Foreign Key) : ERD는 각 엔티티의 기본 키와 외래 키를 식별한다.
-
정규화 : ERD는 대체적으로 정규화를 기본으로 하기 때문에 DB의 중복된 엔티티를 줄이고 데이터의 무결성을 향상시킨다.
-
추상화 : ERD는 실제 세계의 시스템을 추상화한 것이기 때문에 설계자가 시스템에 더욱 효율적으로 집중할 수 있도록 도와준다.
✍ 정규화 (Normalization)
정규화란 릴레이션 간의 잘못된 종속 관계로 인해 데이터베이스 이상 현상이 일어나서 이를 해결하거나 방지를 위해 저장 공간을 효율적으로 관리함에 따라 여러 릴레이션을 여러 개로 분리하는 작업을 뜻한다.
정규화의 단계는 크게 5가지 있으나 3가지만 만족해도 4번째와 5번째는 어느정도 만족을 하기 때문에 제 3 정규화까지만 알아보고 넘어갈예정입니다.
📝 정규화의 필요성
-
데이터 중복의 최소화 : 정규화는 DB의 중복을 최소화 하여 효율적으로 저장 공간을 활용한다.
-
데이터 무결성 향상 : 데이터 중복 최소화, 데이터 이상 현상 최소화 및 데이터의 모순을 방지하기 때문에 무결성을 보장한다.
-
쿼리 효율 증가 : 정규화는 DB 구조를 최소화하고 쿼리 될 데이터의 양을 감소시키기 때문에 쿼리 효율을 증가 시킨다.
-
DB 설계 단순화 : 정규화는 데이터의 유지보수가 쉽게 쪼개기 때문에 DB 설계를 단순화 한다.
정규화가 무조건적으로 필요한 것은 아니다. 프로젝트의 규모, 효율, 그리고 데이터 웨어하우징에 필요에 따라 비정규화가 정규화보다 효율이 더 나을 수도 있지만 아직까지 비정규화를 적용해본 경험이 없기에 자세한 설명은 추후 비정규화를 다루게 되면 따로 해볼 의향이 있다.
📝 제 1 정규화 (비정규형 -> 1NF)
릴레이션의 모든 도메인이 더 이상 분해될 수 없는 원자 값으로 구성되어야 한다.
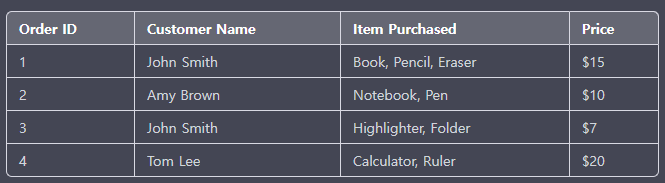
에를 들어, 위의 테이블의 경우에는 아직 정규화가 되지 않은 테이블이다.
보면 John Smith가 구입한 아이템이 Book, Pencil, Eraser로 원자 값으로 표현되지 않아 있다.
만약 테이블이 저게 전부이고 추후 확장 가능성이 없다면 하나의 테이블을 잘게 쪼개면 바로 1NF가 이뤄진다.
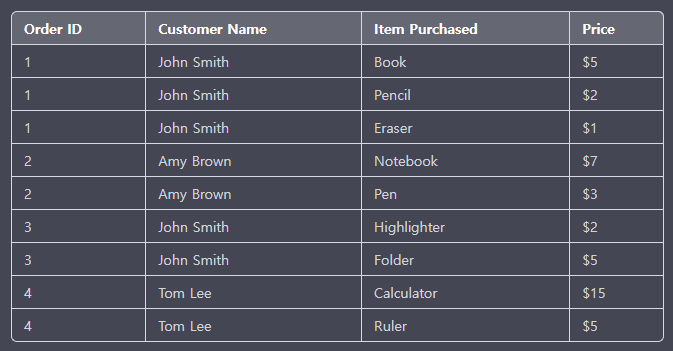
-
속성에 대한 값이 원자 값이어야 함
-
중복 될 수 있는 그룹은 따로 분리해서 관리
-
식별자로 관리
📝 제 2 정규화 (부분 함수의 종속성 제거)
기존에 제 1 정규화 과정을 거친 뒤, 부분 함수의 종속성을 제거한 형태를 말하며, 쉽게 말해 기본 키가 아닌 모든 속성이 기본키에 완전 함수 종속적인 것을 뜻한다.
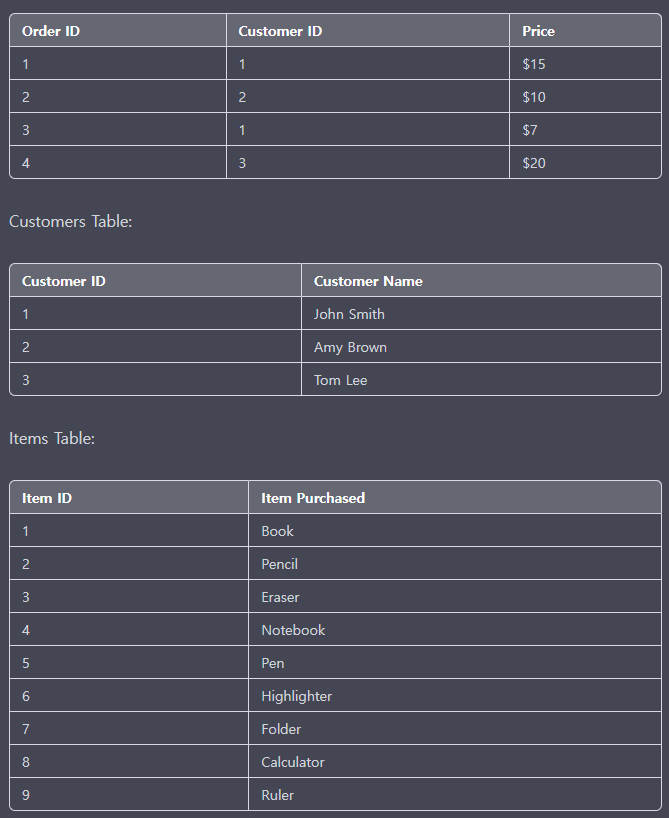
위 예제의 각 테이블을 보면 모든 테이블이 앞에 설정된 Order ID, Customer ID, Item ID에 종속되어 나타낸 것으로 볼 수 있으며 기본키를 제외한 나머지 사이에 의존성은 부여되지 않았다.
📝 제 3 정규화 (이행적 함수 종속 제거)
제 2 정규형이 완성된 상태이고 기본키가 아닌 모든 속성이 이행적 함수 종속을 만족하지 않는 상태를 뜻한다.
여기서, 이행적 함수 종속이란 A -> B 와 B -> C가 존재하면 논리적으로 A -> C가 성립하는데 (삼단논법), 이때 집합 C가 집합 A에 이행적으로 함수 종속이 되었다고 한다.
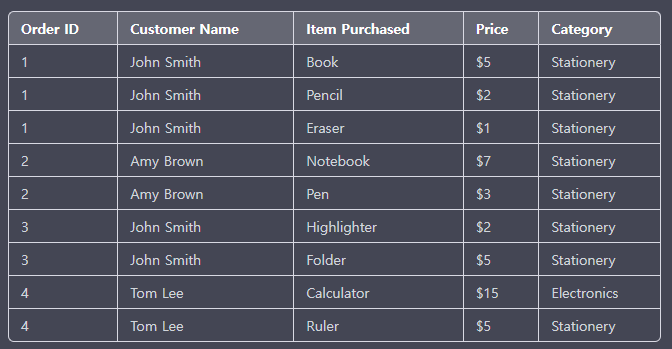
위 테이블을 예로들어보면, 구입한 품목들과 가격 그리고 카테고리가 구입자와 상관 없이 서로 종속이 되어 있는 상태인데 이를 제 3 정규화를 통해서 구별해보면...
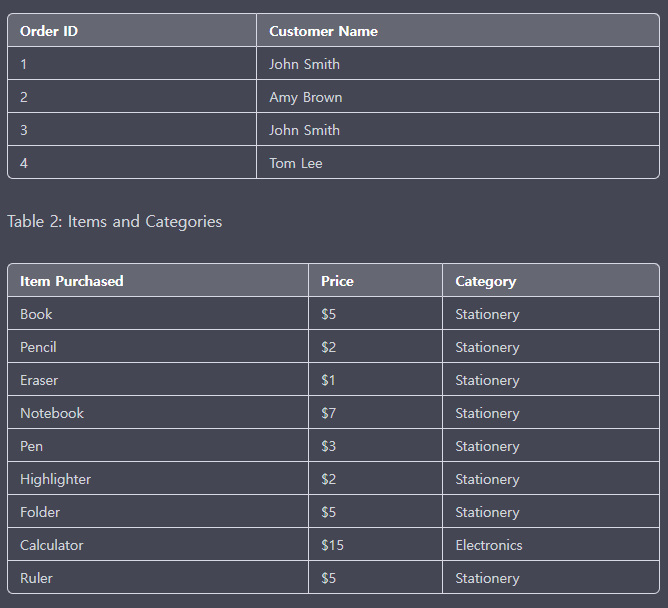
다음과 같이 종속 관계를 더욱 세분화하여 쪼갤 수 있다.
마지막으로, 위에서도 몇 번 언급했지만 정규화를 하고 DB에 이를 적용한다고 해서 성능이 무조건적으로 좋아지는 것은 아니다. 테이블을 저런 식으로 잘게 쪼개개 되면 JOIN 쿼리를 써야하고 이로 인해 성능 저하 현상이 느려질 수 있기 때문에 서비스에 따라 정규화 또는 비정규화 과정을 진행해야 할 필요가 있다.
