1. 모델의 라이프사이클
로우 데이터 -> 데이터 전처리
데이터 전처리 -> 학습 및 검증
2. 어떤 정보를 기록해야하는가?
나중에 최종 모델을 결정하기 위해서는
- Model 소스 코드
- Evaludation Metric 결과
- 사용한 parameters
- Model.pkl 파일
- 학습에 사용한 데이터
- 데이터 전처리용 코드
- 전처리된 data
...
...
- 이처럼 방대한 정보를 기록해야한다
만약 저장박식이 제각각 다르다면 통합하고 비교하기 쉬울까?
문제점:
- 비슷한 작업이 반복적으로 일어남
- Dependency 패키지들이 많고, 버전관리가 어렵다
- 사람 Dependency가 생긴다.
- 테스트가 어렵다.
- Reproducce 되지 않는 경우가 많다.
- Model 학습용 코드를 구현하는 사람과 Serving용 코드를 구현하는 사람이 분리 되어있다.
......
......
3. 다양한 모델 관리 툴
- mlflow
- tensorflow
- neptune.ai
- comet
- Weights & Biases
4. MLflow의 구성요소
mlflow tracking
mlflow projects
mlflow models
mlflow model registry
mlflow tracking
- 모델 하이퍼 파라미터나 코드를 변경하면서 실험할 때,
각각 모델의 metric을 기록하는 저장소를 제공
mlflow projects
- 모델 학습 코드가 재사용 (reproducable)하도록
파라미터의 데이터 타입, 파이토치 버전, 텐서플로우 버전, 콘다 버전, 도커 버전 등 모델 의존성이 있는 모든 정보를 함께 넣어서 코드를 패키징한다.
mlflow models
- 모델이 어떤 형태로 개발되었던 상관없이, (python이든 r이든 등등 상관없이)
항상 통일된 형태로 배포에 사용할 수 있도록 포맷화 시켜준다.
mlflow model registry
- 실험했던 모델을 저장하고 관리하는 저장소
5. mlflow tracking 구조
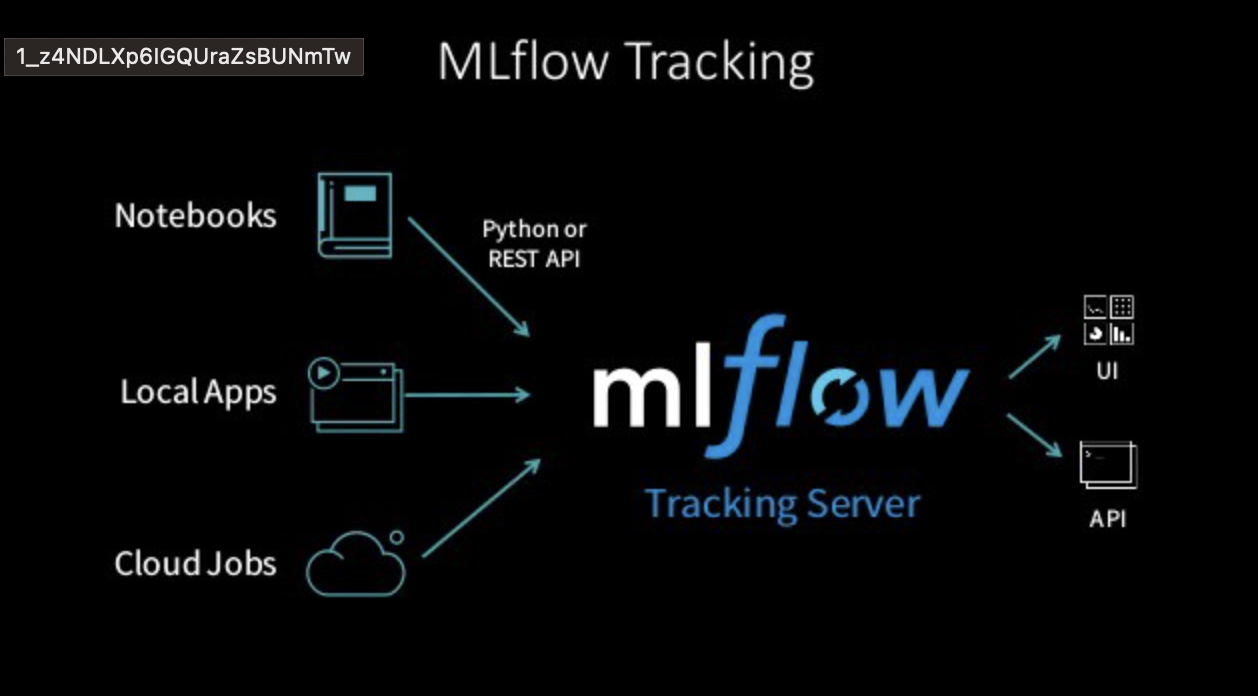
트래킹 서버는 로컬 파일 시스템이나 sqlite, postgresql 등을 백엔드로 사용해서 클라이언트가 저장해달라고 요청한 모델 혹은 모델 관련 메타 정보들을 모두 백엔드 스토리지에 기록한다.
추후 클라이언트가 정보 요청을 하면,
db를 확인해서 정보를 return한다.
모델과 관련된 데이터나 큰 데이터들은 아티팩트 스토어를 별도로 지정해서,
S3과 같은 스토리지에 저장을 할 수 있다.
