Redis Keys의 서비스지연 현상
1️⃣ 싱글스레드 처리
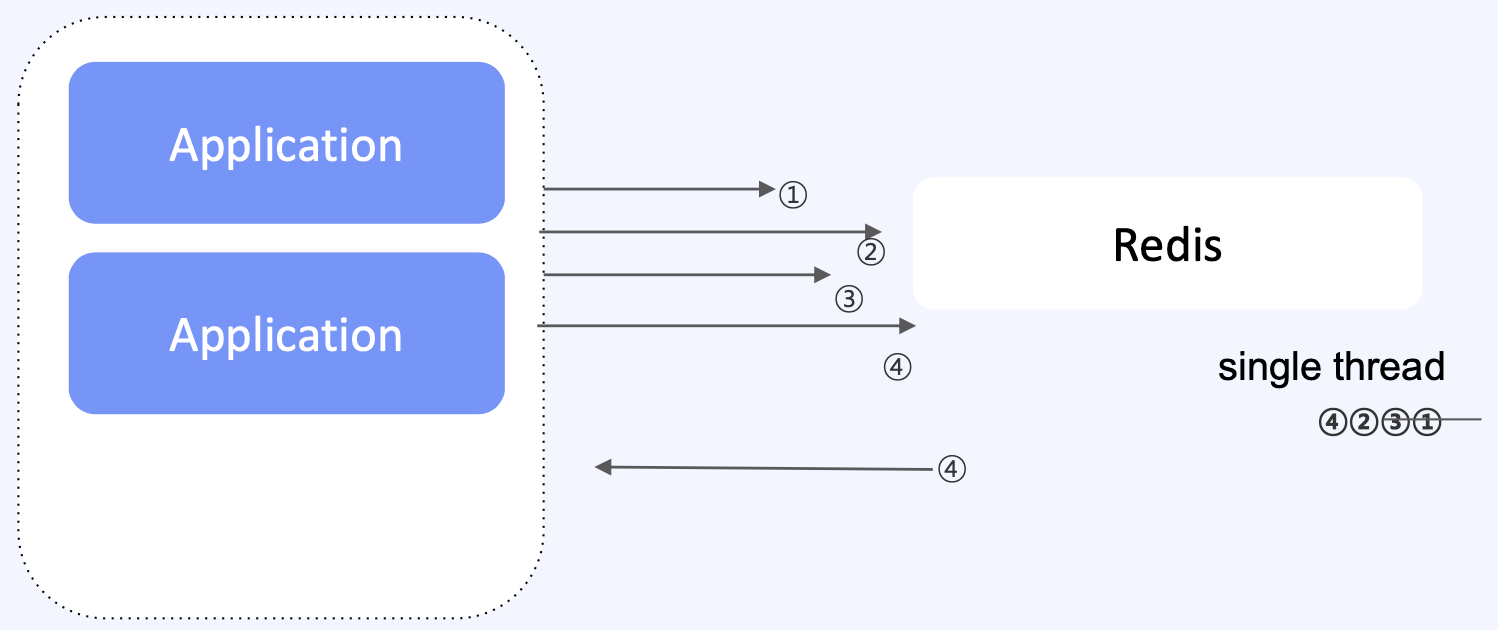
Redis는 싱글스레드를 기반으로 작업이 처리된다.
즉, 클라이언트로부터 전달받은 명령어를 순차적으로 수행하는데,
이때 하나의 명령어가 수행시간이 오래걸리면 줄지어있는 다른 명령어가 모두 대기하게 된다. (지연시간 발생)
👉🏻 in-memory database의 장점이 사라지는 것!
2️⃣ 명령어에 따라 다른 시간복잡도
Redis 대부분의 명령어는 O(1)이지만, O(n)으로 처리되는 것을 특히 주의해야 한다.
📌 KEYS → O(n)
- 즉시 모든 key를 검색하는 명령어
- 100만개의 key를 조회하려면, 1개씩 100만번 조회를 해야하므로 시간복잡도가 O(n)이 됨
- key 개수가 많으면 많을수록 성능저하(시간지연) 및 블로킹 현상이 발생하므로 프로덕션 환경에서는 사용을 지양함
- Value 입장에서는
linsert,hkeys,hgetall,smembers가 O(n)
📌 SCAN → O(n)
- 점진적으로 데이터를 반환하는 비동기적(Non-blocking) key 검색 방식
- 다른 작업과 병렬로 실행 가능
- 한번에 모든 key를 가져오지 않고, 커서(Cursor) 기반으로 순차적(반복) 검색을 함
- ①
COUNT값 만큼씩 데이터를 가져옴 - ②
SCAN 0에서 반환된 커서를 사용해 다음SCAN을 호출하면, 전체 데이터를 순차적으로 가져올 수 있음 - ③ 커서가 0이 되면 모든 key 검색완료
- ①
MATCH(필터링)로 특정 패턴의 key만 검색가능- 프로덕션 환경에서는
KEYS의 대안으로SCAN을 사용
3️⃣ Java 실습 코드
import redis.clients.jedis.Jedis;
import redis.clients.jedis.ScanParams;
import redis.clients.jedis.ScanResult;
public class RedisScanExample {
public static void main(String[] args) {
try (Jedis jedis = new Jedis("127.0.0.1", 6379)) {
String cursor = "0"; // 초기 커서는 0
ScanParams params = new ScanParams().match("user:*").count(10);
do {
ScanResult<String> scanResult = jedis.scan(cursor, params);
cursor = scanResult.getCursor(); // 다음 스캔을 위한 커서 업데이트
scanResult.getResult().forEach(System.out::println);
} while (!cursor.equals("0")); // 커서가 0이면 종료
}
}
}4️⃣ Docker 기반 Redis Bash 실습
# Redis Bash 실행
docker exec -it <docker 컨테이너 ID> /bin/bash
# 대량 Key - value 생성
for i in {0000000..9999999}; do echo set key$i $i>> redis-strings.txt; done
# echo -> 출력, key$i $i -> key value 같은 값
# 파일 실행
cat redis-strings.txt
# redis-cli pipeline으로 실행 (대량 배치 작업에 용이)
cat redis-strings.txt | redis-cli --pipe
# KEYS -> O(n)
KEYS *
# SCAN -> O(1)
> scan 0 match * count 100
1) 9633792 (cursor 값)
2) 1) "key3628497"
2) "key6700864"
. . .
> scan 9633792(cursor 값) match * count 100
🐰 I'm Sunyeon-Jeong, mallang