7월 28일 트위치에서 진행한 AWS Game Master 웨비나를 보며 실습을 한 것으로 1편에서 이어진다.
오늘은 AWS Glue 데이터 카탈로그를 생성하는 것부터 정리해보겠다. 이번편의 실습내용은 웨비나를 보면서 따라하는 건데도 중간에 어려움이 있었다 GCP를 만지다가 AWS를 만지니 낯설다ㅠ_ㅠ.
이전 프로세스에서는 서버에서 생성한 로그와 DynamoDB에서 S3로 업데이트된 사용자 정보를 거의 실시간으로 수집했다. 이제는 데이터 분석을 시작할 것이다. 가장 먼저 할 일은 Glue 데이터 카탈로그를 만드는 것이다. Glue data catalog는 테이블 정의와 데이터셋의 위치 내용을 포함하며 Glue Crawler를 사용하여 이를 채운다.
Glue 서비스를 선택하고, 크롤러를 추가하였다. Crawler name은 gamelog-raw를 사용하였고, 데이터 저장소로 S3를 선택하였다. Include path에는 파일 버튼을 눌러서 gaming-raw 버킷을 선택하였다.
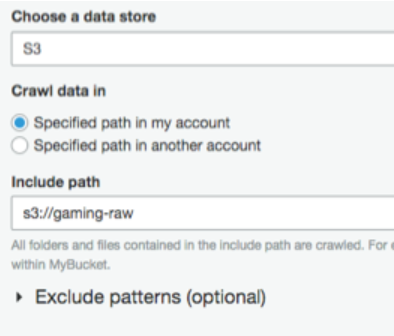
Choose an existing IAM role옵션을 선택하였고 IAM role은 GlueETLRole을 선택하였다. Frequency 는 Hourly 항목을 선택하였다.
메타 데이터를 저장하는 데이터베이스가 필요하기 때문에 gamelogdb의 데이터베이스를 생성하였다.
생성된 크롤러를 선택하고 크롤러실행 버튼을 클릭하였다. 두개의 테이블이 추가된 것을 볼 수 있다.

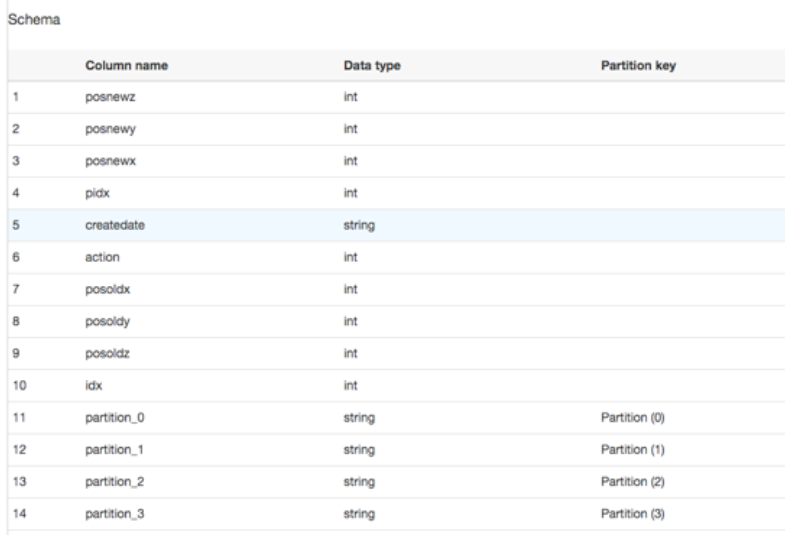
데이터 카탈로그를 확인한다. Tables메뉴를 선택하면 2 개의 테이블이 추가되고, 각각을 클릭하면 해당 테이블 정보를 볼 수 있다. 데이터 저장소에 테이블 정보가 포함되어 있고 파티션이 자동으로 인식된다는 것을 알 수 있습니다.
DynamoDB의 테이블 정보는 Glue Data Catalog를 통해 관리 할 수 있다. 따라서 이전과 비슷한 방법으로 Glue Crawler를 만든다. DynamoDB 테이블의 경우 스키마 변경이 없으므로 Frequency를 Run on demand로 선택한다.
DynamoDB의 데이터는 동일한 데이터 카탈로그 데이터베이스에 저장할 수도 있다. 이전에 생성 한 gamelogdb 를 선택하여 Glue Crawler 생성을 완료한다.

크롤러 생성이 완료되면 크롤러 실행버튼을 클릭하여 실행하고, 총 3 개의 테이블을 볼 수 있다.

앞서 만든 Glue 데이터 카탈로그에 대해 ETL 작업을 수행해보겠다.
글루 서비스의 왼쪽 ETL 아래 Jobs 버튼을 클릭하고, Glue 작업생성을 시작한다.
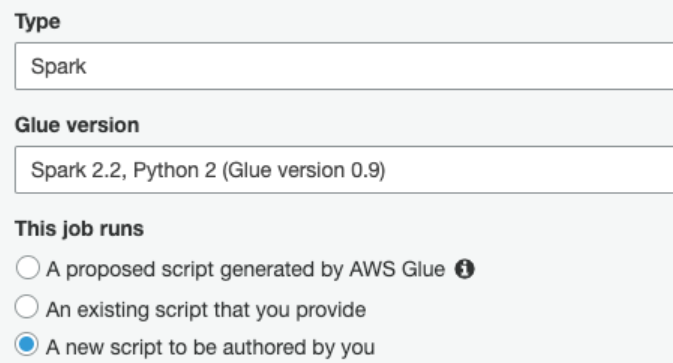
위와 같이 설정하고, Advanced properties 메뉴를 눌러서 Job metrics를 Enable로 설정해준다. 이는 ETL 작업이 수행 될 때 CloudWatch를 통해 모니터링을 할 수 있게 해준다.
스크립팅 페이지에서 모든 콘텐츠를 삭제 한 다음 아래 Python 스크립트를 복사하여 붙여 넣는다.
import sys
import datetime
from awsglue.transforms import *
from awsglue.dynamicframe import DynamicFrame
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
s3Bucket = "s3://gamelog-raw"
s3Folder ="/gamelog/"
# Set source data with playlog in S3, userprofile in DynamoDB
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "gamelogdb", table_name = "playlog")
datasource1 = glueContext.create_dynamic_frame.from_catalog(database = "gamelogdb", table_name = "userprofile")
df1 = datasource0.toDF()
df1.createOrReplaceTempView("playlogView")
df2 = datasource1.toDF()
df2.createOrReplaceTempView("userprofileView")
# Query to join playlog and userprofile
sql_select_athena = 'SELECT playlogView.partition_0, playlogView.partition_1, playlogView.partition_2, playlogView.partition_3, playlogView.posnewz, playlogView.posnewy, playlogView.posnewx, playlogView.posoldz, playlogView.posoldy, playlogView.posoldx, playlogView.action, playlogView.idx, playlogView.pidx, playlogView.createdate, userprofileView.pidx, userprofileView.uclass, userprofileView.ulevel FROM playlogView, userprofileView WHERE playlogView.pidx = userprofileView.pidx ORDER BY playlogView.createdate'
sql_select_ml = 'SELECT playlogView.posnewx, playlogView.posnewy FROM (SELECT * FROM playlogView ORDER BY playlogView.pidx, playlogView.createdate)'
exec_sql_athena = spark.sql(sql_select_athena)
exec_sql_dyf_athena = DynamicFrame.fromDF(exec_sql_athena, glueContext, "exec_sql_dyf_athena")
exec_sql_ml = spark.sql(sql_select_ml)
exec_sql_dyf_ml = DynamicFrame.fromDF(exec_sql_ml, glueContext, "exec_sql_dyf_ml")
# Set target as S3 into two types, json and csv
datasink1 = glueContext.write_dynamic_frame.from_options(frame = exec_sql_dyf_athena, connection_type = "s3", connection_options = {"path": s3Bucket + s3Folder + "gamelog_athena", "partitionKeys" : ["partition_0", "partition_1", "partition_2", "partition_3"]}, format = "json", transformation_ctx = "datasink1")
datasink2 = glueContext.write_dynamic_frame.from_options(frame = exec_sql_dyf_ml, connection_type = "s3", connection_options = {"path": s3Bucket + s3Folder + "gamelog_sagemaker"}, format = "csv", transformation_ctx = "datasink2")
job.commit()datasource0과 datasource1 모두 Glue 데이터 카탈로그의 데이터인 2 개의 데이터 소스를 활용 하고 있음을 알 수 있다.
Athena를 통한 쿼리에는 모든 데이터 세트가 필요하므로 sql_select_athena 문으로 데이터 변환 작업을 수행 한다.
Athena를 통한 쿼리에는 모든 데이터 셋이 필요하므로 sql_select_athena 문으로 데이터 변환 작업을 수행 한다. 아래문장은 S3 및 DynamoDB의 PlayLog와 UserProfile 데이터를 조인한다.
WHERE playlogView . pidx = userprofileView . pidxSageMaker에는 모델 학습을 위해 x 및 y 좌표의 2 차원 데이터가 필요하다. 그러나 각 사용자의 동작 패턴을 표시하려면 pidx별로 정렬해야하므로 이를 고려한 sql_select_ml은 아래이다.
SELECT playlogView.posnewx, playlogView.posnewy FROM (SELECT * FROM playlogView ORDER BY playlogView.pidx, playlogView.createdate)작업을 실행하고 S3 서비스를 선택하여 ETL 스크립트에서 지정한 분석 버킷으로 이동하여 ETL 작업이 성공적으로 실행되고 변환된 데이터가 저장되었는지 확인한다. gamelog 폴더 아래에 gamelog_athena 및 gamelog_sagemaker라는 2 개의 폴더가 생성되며 변환된 데이터가 저장되는 것을 볼 수 있다.
raw data를 수집하고 분석하기 위한 변환을 완료했다. 이제 마지막으로 새로 추가된 데이터를 Glue 데이터 카탈로그에 추가해야한다.
Glue 서비스를 선택하여 이전과 같은 방식으로 Glue Crawler를 생성한다. 크롤러 이름으로는 gamelog-analytics를 부여하였다. Database는 이전과 같이 gamelogdb를 선택하였다.
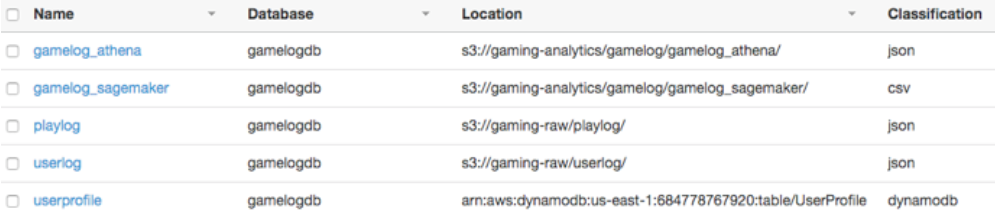
실행이 완료되면 2 개의 테이블이 추가되어 총 5개의 테이블이 있는 것을 볼 수 있다.
이제 분석에 필요한 데이터를 처리하고 저장했으므로, Athena를 사용하여 표준 SQL을 사용하여 S3에 저장된 데이터를 분석한다. Athena는 Glue 데이터 카탈로그와 즉시 통합되므로 별도의 스키마 정의없이 직접 대화 형 쿼리를 사용하여 데이터를 분석 할 수 있다.
데이터베이스에서 이전에 생성한 Glue 데이터 카탈로그에 저장된 gamelogdb를 선택하면 DynamoDB 테이블을 제외하고 S3에 저장된 4 개의 테이블이 나타난다.
이제 아래의 SQL 쿼리를 통해 데이터를 분석해보았다.
SELECT * FROM gamelog_athena WHERE CAST (partition_2 AS BIGINT ) = 9 limit 100 ;- 어떤 클래스 플레이어가 가장 많이 선택했는지 알아보기
SELECT COUNT(DISTINCT pidx) AS users, uclass FROM gamelog_athena GROUP BY uclass;- userlog 테이블의 데이터를 통해 가장 높은 레벨의 사용자 알아보기
SELECT * FROM userlog WHERE ulevel IN ( SELECT MAX (ulevel) FROM userlog);- 특정 지역에서 플레이 한 플레이어 수 알아보기
SELECT COUNT(DISTINCT pidx) AS hotzone FROM gamelog_athena WHERE posnewx BETWEEN 300 AND 500 AND posnewy BETWEEN 400 AND 700;다음은 Amazon SageMaker를 통해 머신러닝 모델 트레이닝과 비정상 동작을 식별해보았다. 이 단계에서는 SageMaker의 기본 제공 알고리즘인 RCF (Random Cut Forest)를 사용하여 데이터 세트 이상을 감지한다. 이 단계에서부터 어려웠다..
AWS Management Console에서 SageMaker 서비스를 선택한다. Notebook instance name으로 gamelog-ml-notebook를 지정하고 인스턴스 유형은 ml.m4.2xlarge을 선택한다. create IAM role 화면에서 gaming-analytics버킷을 지정한다.
잠시 후 생성한 노트북 인스턴스가 InService 상태로 변경된다. 오른쪽의 New 버튼을 클릭하고 conda_python3을 선택한다.
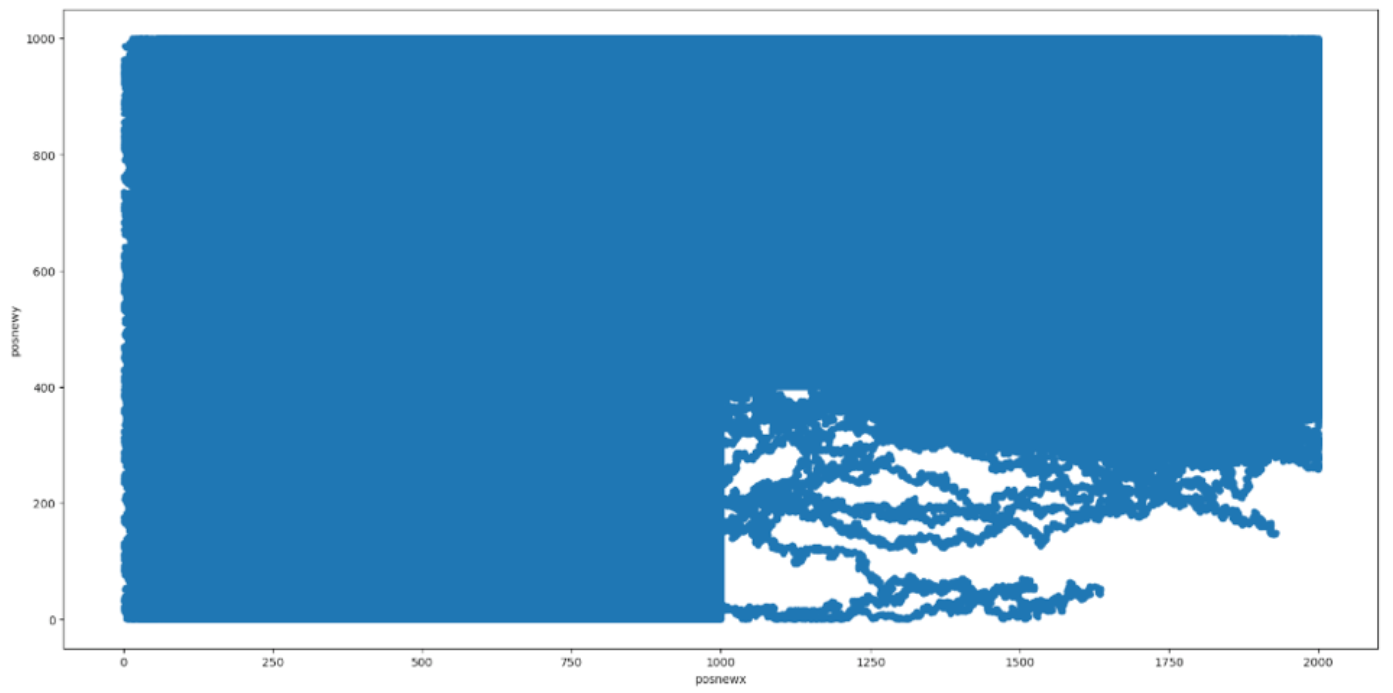
그래프를 보면 의심스러운 점을 찾을 수 있다. x 좌표는 1000 ~ 1200이고 y 좌표는 0 ~ 400이다.
다음 셀에서 이제 모델 학습을 위해 데이터를 RecordIO prodobuf 형식으로 인코딩한다. 이 단계는 단순히 원본 데이터를 CSV 형식으로 변환하고 결과를 S3 버킷에 저장한다.
실습에서 사용되는 데이터는 x 및 y 좌표가있는 2차원 데이터이므로 2 차원으로 재정의한다.
실습에서 제시된 코드들의 실행이 완료되면 학습 완료 출력을 확인할 수 있다. 모델 학습이 완료되었다.
실제 데이터 세트를 추론 해본다. 전체 데이터 세트를 추론하는 것이 좋지만이 실습에는 2ml.c5.2xlarge 인스턴스 만 추론에 사용된다는 제한이 있다. 따라서 무작위로 추출 된 약 180,000 개의 데이터를 기반으로 추론을 수행한다.

이 실습에서는 평균값에서 1.5 표준 편차 범위를 초과하는 모든 이상 값 점수을 비정상 값으로 간주한다.
results = rcf_inference.predict(predict_data.as_matrix().reshape(-1,2))
scores = [datum['score'] for datum in results['scores']]
predict_data['score'] = pandas.Series(scores, index=predict_data.index)
score_mean = predict_data.score.mean()
score_std = predict_data.score.std()
score_cutoff = score_mean + 1.5 * score_std
anomalies = predict_data[predict_data['score'] > score_cutoff]
anomalies.plot.scatter(
x = 'posnewx',
y = 'posnewy'
)다음 결과는 모델에 따라 비정상적인 동작을 보이는 이동 패턴을 보여준다.

2회차에 걸쳐 진행한 실습의 큰 흐름은 다음과 같다.
1. Amazon EC2 키 페어 생성
2. Amazon S3 버킷 생성
3. AWS CloudFormation 스택 생성
4. Amazon Kinesis Data Firehose 생성
5. Amazon DynamoDB 구성
6. Amazon Kinesis 에이전트를 통해 Amazon EC2 인스턴스 설정 및 데이터 수집
7. AWS Glue 데이터 카탈로그 생성
8. AWS Glue ETL 작업 실행
9. Amazon Athena를 사용한 데이터 분석
