오늘은 7월 28일에 트위치에서 진행된 AWS Game Master 웨비나를 보면서 게임 분야라서 좀 더 재밌게 실습을 진행해보았던 경험을 공유하려고 한다.
https://www.twitch.tv/videos/693088101
6월부터 네차례의 AWS Game Master 웨비나가 진행되었는데 드디어 시간이 맞아서 등록해볼 수 있었다. 나머지 다른 강의들도 영상으로 볼 수 있으니 다음에 하나씩 실습해보아야겠다 :)
이 실습에서는 무작위로 생성된 게임 데이터를 AWS에서 실시간으로 수집하고 처리한 다음 분석하는 서비스를 구축해볼것이며, 또한 기계 학습을 통해 플레이어의 비정상적인 행동을 식별 할 수 있을 것이다.
아키텍쳐

아키텍쳐는 다음과 같다.
유저가 맵에서 어디로 이동하는지 등의 좌표 정보나, 액션, 스킬 사용 정보가 있는 게임 서버인 EC2를 하나 만들고, 유저의 프로필(캐릭터, 레벨, 레벨업 시기 등)을 저장하는 DynamoDB를 하나 만들 것이다. 그 다음 DynamoDB에서 스트림을 이용해서 데이터를 수집하며 Lambda가 읽어서 Kinesis Firehose로 가져갈 것이다.
EC2에는 kinesis Agent를 올릴 것이며, Kinesis firehose를 이용해서 스트리밍 데이터를 실시간으로 캡쳐할 것이다. s3 스토리지에 두개의 데이터 저장하며, raw data를 바로 사용할 수 없으니 ETL을 이용하여 데이터를 변화시키고, 조인하여 하나의 파일을 만들 것이다.
전체적인 스키마 관리를 위해 glue를 사용해서 s3에 있는 데이터를 크롤링할 것이며, 더불어 DynamoDB의 데이터도 관리할 것이다. 데이터를 변화한 이후에도 크롤링하여 카탈로그 글루가 관리할 것이고 Athena를 이용해서 글루데이터 카탈로그를 이용해서 쿼리하며 Quicksight를 이용해서 최종 시각화까지 하는 데모를 실습해볼 것이다.
앞서 말했듯이, 사용되는 데이터의 유형은 총 두 가지이다.
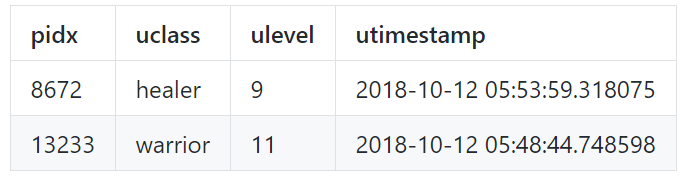

총 20043명의 사용자의 약 4 천만 개의 플레이 레코드를 포함하며, 이 게임의 가상 지도는 다음과 같다. 일반 사용자는 표시된 레드존에 액세스 할 수 없다.
먼저, 리전으로는 us-east-1을 선택했다. 그리고 나중에 생성할 EC2 인스턴스에 SSH로 연결하려면 키 쌍이 필요하기 때문에 Create Key Pair을 눌러 키를 만들었다.
.pem파일을 다운받고, 필요한 모든 데이터를 저장하기 위해 S3버킷을 생성했다. raw data를 저장하기 위한 raw bucket(gaming-raw)과 분석 데이터를 저장하기 위한 분석 버킷(gaming analytics)을 생성했다.

그 다음으로 AWS CloudFormation 스택을 생성했다. 실습에서 활용할 EC2, DynamoDB, Lambda 및 IAM role은 CloudFormation 스택을 통해 생성된다. 단순히 리소스를 프로비저닝하는 것 외에도 CloudFormation 스택은 Lambda 함수를 호출하여 DynamoDB를 초기화하는 로직을 실행한다.
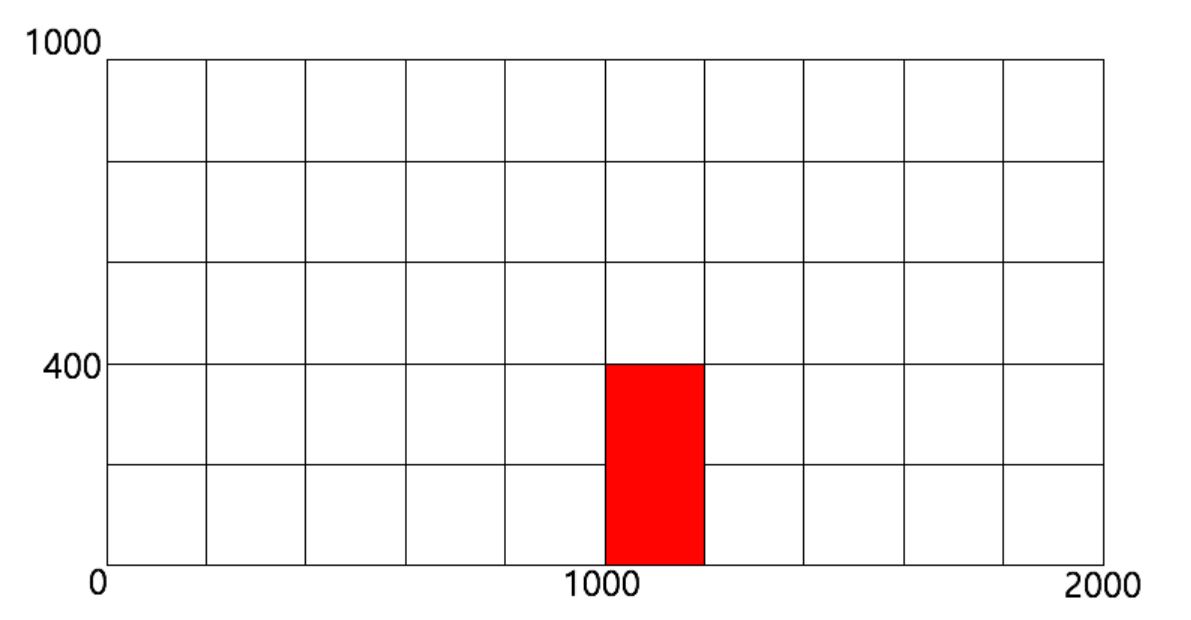
CloudFormation의 스택만들기를 눌러서 템플릿으로 Amazon S3 template URL을 선택했으며 https://s3.amazonaws.com/anhyobin-gaming/cloudformation.yaml URL을 입력해주었다.
스택 이름을 작성하고, KeyName 에서 이전에 생성한 EC2 Key Pairs를 선택하였다. 이 실습에서 사용된 AWS CloudFormation 템플릿은 Lambda 함수 DDBInitialize를 자동으로 호출한다.
DDBInitLambdaInvoke:
Type: Custom::DDBInitLambdaInvoke
Properties:
ServiceToken: !GetAtt DDBInitLambda.Arn계속하려면 리소스 생성 완료 응답을 CloudFormation 스택에 보내야한다. 따라서 DDBInitialize 함수에는 다음이 포함된다
def send_response(event, context, response_status, response_data):
response_body = json.dumps({
"Status": response_status,
"Reason": "See the details in CloudWatch Log Stream: " + context.log_stream_name,
"PhysicalResourceId": context.log_stream_name,
"StackId": event['StackId'],
"RequestId": event['RequestId'],
"LogicalResourceId": event['LogicalResourceId'],
"Data": response_data
})
headers = {
"Content-Type": "",
"Content-Length": str(len(response_body))
}
response = requests.put(event["ResponseURL"], headers = headers, data = response_body) Resources 탭을 통해 모든 리소스 생성이 완료된 것을 볼 수 있다. 그리고 Lambda 기능을 통해 DynamoDB가 제대로 생성 및 초기화되었는지 확인해 보았다. AWS Management Console에서 DynamoDB 서비스를 선택하여
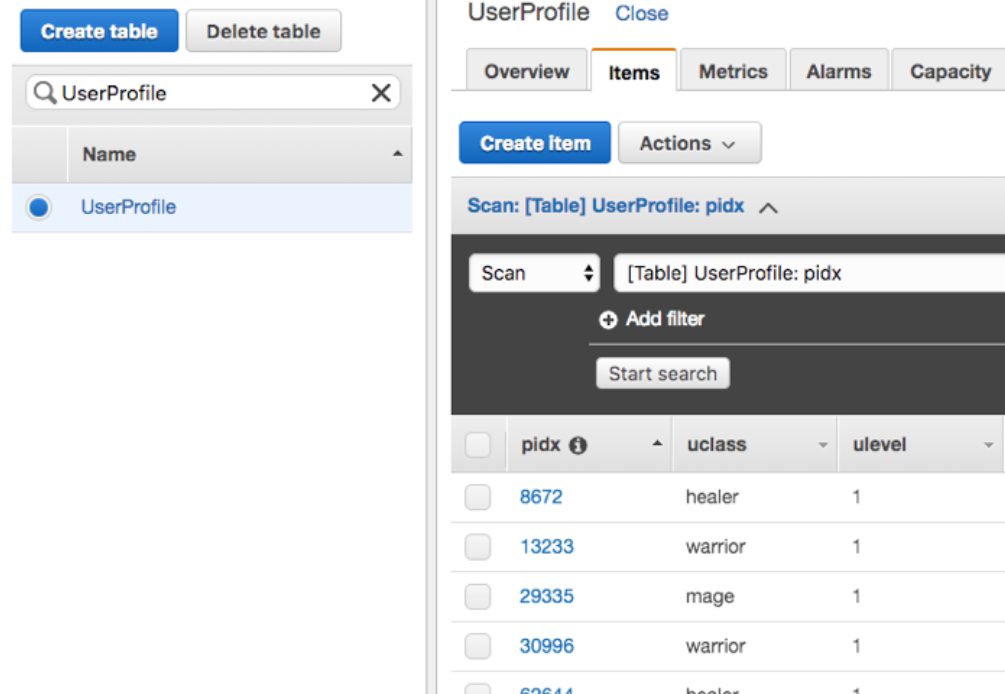
UserProfile 테이블이 생성되었는지 확인하였다.
DynamoDB 및 EC2 instnace에서 생성 된 데이터는 Kinesis Data Firehose를 통해 수집되기로 아키텍쳐를 짰으므로, Kinesis에서 Get started -> Create delivery stream을 눌러주고 Delivery stream name으로 stream-playlog를 입력해주었다.
대상으로 S3 버킷을 선택해주고, S3 bucket에 대해 이전에 생성한 raw data 버킷을 선택하였다. prefix에는 playlog/ 를 입력해 주었다.
세부 설정은 그대로 따라하였다.
IAM역할을 자동으로 구성해주었고, Kinesis Data Firehose 생성을 완료하였다.
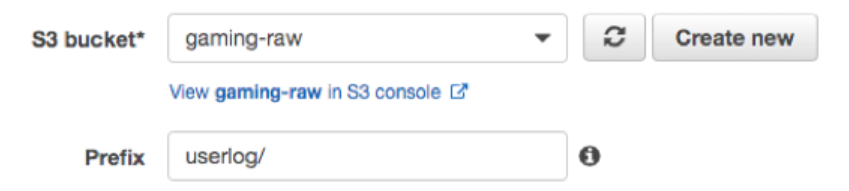
이 실습에서는 2 개의 Kinesis Data Firehose가 필요하기 때문에(아키텍쳐 참조) 위와 같은 방법으로 두 번째 Kinesis Data Firehose를 생성하였다. Delivery Stream Name으로는 stream-userprofile을 부여해주었다. 이번 prefix는 userlog/ 를 입력해주었다.
DynamoDB에는 UserProfile 데이터가 있다. 이것은 Kinesis 및 Lambda 함수를 사용하여 수행된다.
DynamoDB 서비스를 선택하여 들어가서 UserProfile 테이블을 선택하고 New and old images옵션을 선택하였다. 이를 통해 DynamoDB 테이블의 변경 사항을 캡처 할 수 있다.
Lambda 서비스를 선택하여 이벤트 트리거로 Lambda 함수에 DynamoDB 스트림을 추가하고 DynamoDB에서 변경 사항이 발생하면 데이터가 Kinesis로 수집되게 한다. 미리 생성 된 StreamUserLog 함수를 선택하고 세부 설정은 그대로 따라하였다.
EC2 서비스를 들어가서 CloudFormation을 통해 생성 된 PlayLogGenerator 인스턴스를 선택하였다. 인스턴스의 공용 IP를 확인한 후 SSH 클라이언트를 사용하여 인스턴스에 연결한다.
다음과 같이 파일이 있는지 확인하고,
$ ls
playlog_gen.py StreamLog UserList
$ ls -l / tmp / archived_playlog / 2018 / 10 / 09 / 01 /
합계 6493876
-rw-rw-r-- 1 ec2-user ec2-user 169079641 Oct 17 08:32 run-1538992116187-part-r-00000
-rw-rw-r-- 1 ec2-user ec2-user 169128956 Oct 17 08:32 run-1538992116187-part-r-00001
...
...
...4천만 개의 데이터 세트를 업로드하기 어렵기 때문에 AWS CLI 명령을 사용하여 / tmp / archived_playlog / 경로에서 S3 버킷으로 아카이브 된 로그 데이터를 업로드하면,
gaming-raw에서 40 개의 복사본이 복사 된 것을 볼 수 있다.
EC2 인스턴스로 돌아가서 Kinesis 에이전트 설정을 확인하고, 다음 명령을 실행하여 Kinesis 에이전트를 구현한다.
sudo service aws-kinesis-agent start 로그를 생성하였다. 백엔드에서 실행하려면 &를 포함해야한다.
$ python playlog_gen.py & /tmp/playlog/ 경로에 로그가 생성 된 것을 볼 수 있다.
/var/log/aws-kinesis-agent/aws-kinesis-agent.log를 통해 Kinesis 에이전트의 로그를 확인할 수 있다.
playlog에서 데이터가 YYYY / MM / DD / HH 구조 로 분할되고 거의 실시간으로 수집되는 것을 볼 수 있다.
AWS Management 콘솔의 DynamoDB 서비스로 이동 하여 UserProfile 테이블이 업데이트 된 것을 볼 수 있다.

As Lena continued to play, she found herself drawn into the strategic elements of the game. The roulette’s diverse betting options allowed her to experiment with different strategies and discover which ones worked best for her. To her https://mostbetkzn.kz/ amazement, a series of successful bets led her to trigger the game’s jackpot feature, resulting in a substantial payout. Lena’s initial skepticism was replaced by a genuine appreciation for online gambling, proving that sometimes stepping out of one’s comfort zone can lead to unexpected and rewarding experiences.