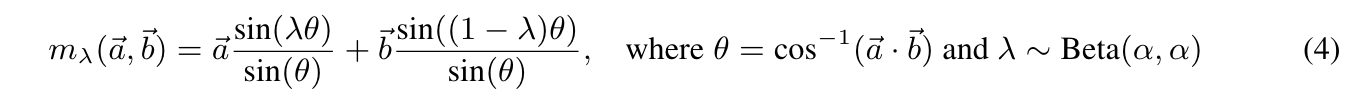Geodesic Multi-Modal Mixup for Robust Fine-Tuning (2023 NeurIPS) 입니다.
https://arxiv.org/abs/2203.03897
본 논문에서는 CLIP(multi-modal foundation model)이 지니고 있는 embedding space를 분석하고 문제점을 발견한 뒤, 이를 해결하는 fine-tuning 방법론을 제안하는 논문입니다.
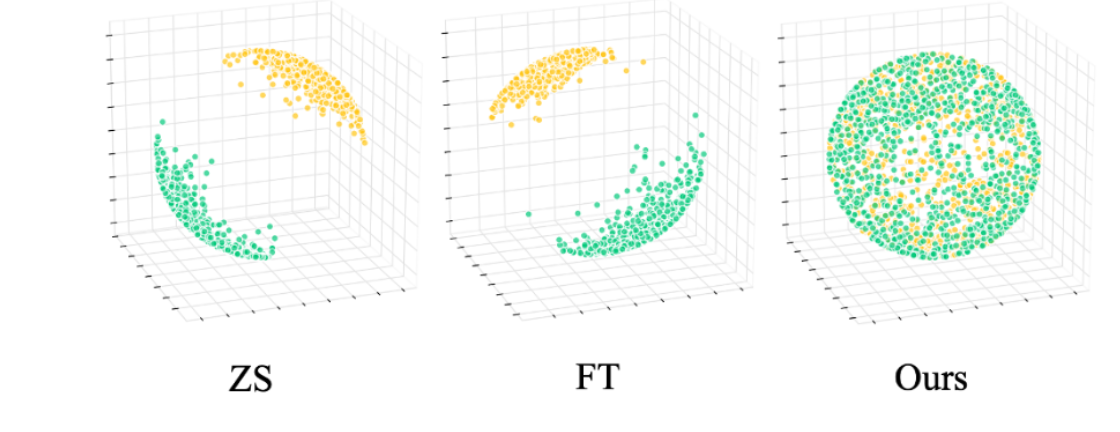
저자들은 CLIP의 objective가 image, text modality를 분리시키는 것을 발견합니다.
그림에서 초록색은 이미지, 노란색은 텍스트에 대한 데이터들의 임베딩을 hypersphere 상에 나타낸 것입니다. 이 때 원래 objective(contrastive loss for multi-modal)의 의도는 각각의 일치하는 image-text pair들이 함께 모여있는 것을 의도했지만, 실제로는 분리되어서 그렇게 되지 않는것을 발견했습니다.
이런 성질이 기존 Contrastive loss를 분석했던 연구(Wang et al. 2020)의 alignment-uniformity 관점에서는, embedding transferability (downstream task에 fine-tuning했을 시, 좋은 성능을 보이는 능력 (?))를 제한할 수 있다고 주장한다고 합니다. 따라서, 문제를 “How can we obtain a multi-modal representation dealing better with the uniformity-alignment for robust transfer?” 로 정의하고, 해결하는, 새로운 학습방법인 geodesic multi-modal Mixup (m^2-Mix)를 제안합니다.
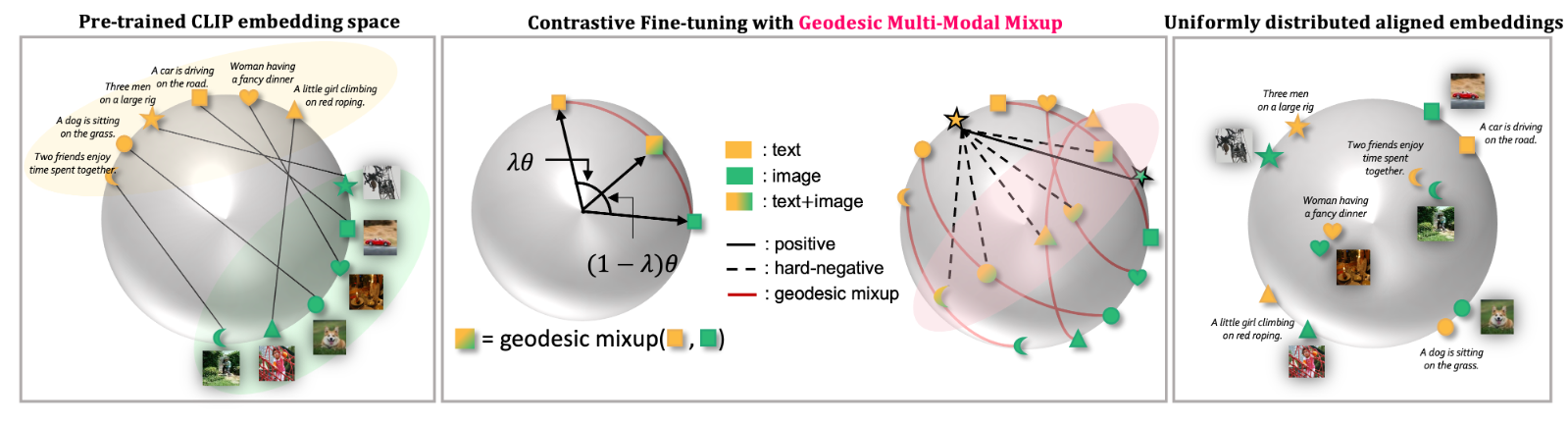
방법론은 간단한데, hard negative를 image와 text의 mixup을 통해 만들어냅니다.
- 데이터를 mixup할 때, 이들이 hypersphere상에 존재해야 하기 때문에 Geodesic Mixup (Eq. 4)이라는 것을 정의하고, 두 데이터 포인트를 interpolate한 mixed sample이 hypersphere상에 존재하도록 데이터를 만들어냅니다.
- (가운데 그림) 그리고 나서, contrastive loss의 denominator term에서 멀어지는 샘플을 기존 CLIP loss (Eq. 1)과 다르게, mixed up data로 바꿔줍니다.
- 의도하고자 하는 바는, Hard Negative sample로 인해, 원래 더 가까워야 되는 image와 text embedding과의 alignment보다 Hard Negative sample이 더 가까워 짐으로써, 일치하는 페어의 alignment를 강화시키도록 함
- 마지막으로, hard negative를 학습하면서 생길 수 있는 overconfidence이슈를 해결하고자 각 uni-modal 에서의 mixup을 한번 더 진행. (Vision Mix, Language Mix, Vision Language Mix).
- 최종 Loss는 위 네가지 loss가 합쳐지는 ..