오늘 소개드릴 논문은
JEM++: Improved Techniques for Training JEM
https://arxiv.org/abs/2109.09032
로 ICCV 2021에 발표된 논문입니다.
제목에서도 알 수 있듯이, 저번에 소개드렸던 JEM (Joint Energy-based Model)의 새로운 training procedure를 추가함으로써 JEM의 accuracy, training stability, and speed를 모두 향상시킨 방법론을 소개하는 논문입니다.
어떤 테크닉을 썼는지 살펴보면 다음과 같습니다.
- Proximal SGLD
- Proximal-YOPO-SGLD (PYLD)
- Initializing SGLD chain from a distribution estimated from training data
JEM 방법론은 지난번에 소개드렸듯이 기존의 discriminative model인 CNN architecture를 joint energy based model로 재해석 함으로써 좋은 discriminative 능력은 유지하면서 GAN-based apporach 생성모델의 퀄리티와 견줄 수 있는 생성모델을 지닐 수 있는 Energy-based model training 방식을 소개합니다.
이전 연구에서 SGLD 방식의 sampling 방법이 stability와 computational time 사이의 trade off가 있음을 보이는 것을 알 수 있습니다. 일반적으로 SGLD chain의 step-size가 커지면 커질 수록 converge한 이상적인 sampling 안정성을 가질 수 있지만, 이 경우 large step-size를 가져야 하기 때문에 시간이 많이 소요됩니다.
- Proxmial SGLD
JEM++는 EBM training에서 SGLD의 instability의 원인을 극단적으로 model parameter update에 부정적인 영향을 가진 값을 가지는 샘플을 생성한다는 것이라고 얘기하며 Proximal SGLD방식을 도입해 문제를 해결하고자 했습니다.
Proximal SGLD방법을 직관적으로 설명하면, gradient의 instability(model에게 안좋은 영향을 주는 매우 큰 gradient값이 존재)를 해결하기 위해, gradient의 범위에 직접적인 제한을 줌으로써 문제를 해결합니다. (Proximal point method로 불리는 optimization에 기반하여 해당 방법론을 제안. 여기서 제가 이해한 것은 에너지 함수의 그레디언트로 이동하는 범위를 이전 스텝 주변으로 한정함으로써 너무 벗어난 지역에서 다음 스텝이 시작되지 않도록 제약을 걸어주는 것으로 이해함.) SGLD의 각 iteration에서 이전 스텝에 대한 샘플의 Energy function에 대한 입력의 gradient를 [-e, e]의 범위만큼 clamp하는 operation을 진행함으로써 기존 SGD 방식보다 robust convergence behavior를 가질 수 있다고 합니다.
- Proximal-YOPO-SGLD (PYLD) (figure 1)
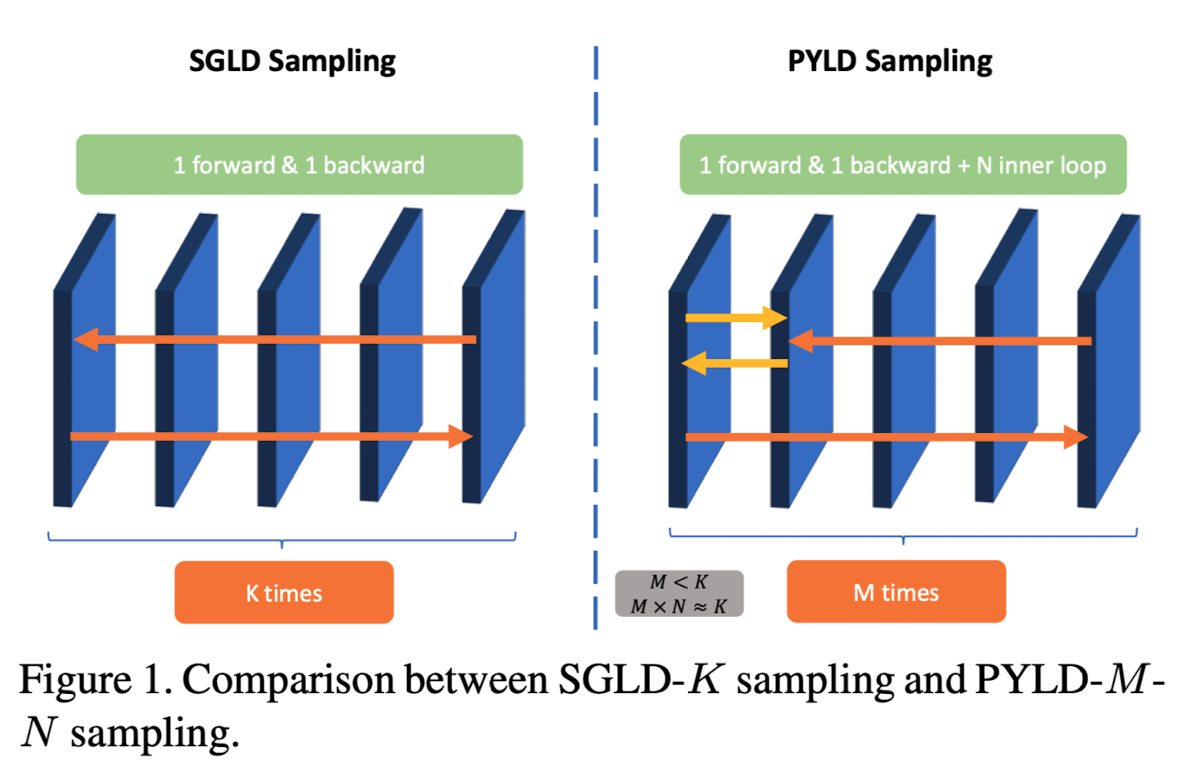
YOPO(You-Propogate-Only-Once)라고 불리는 PGD에서 multi-step adversarial training을 accelerate하는 방식을 착안한 Proximal SGLD를 제안합니다. (YOPO의 key 아이디어는 adversarial perturbation은 네트워크에서 첫번째 layer의 weight와 연관되어있습니다.)
Proximal SGLD는 K (iter step)번의 full forward와 backward propagation이 모델 파라미터를 업데이트 하기 위해 필요하게 됩니다. EBM의 훈련을 안정화 하기 위해서는 큰 K를 필요로 할 것이고, 이것은 많은 시간을 소요하게 됩니다. 이러한 문제를 극복하기 위해서, forward와 backward의 total number을 줄이기 위해 YOPO framework를 사용하는데, 제가 이해한 것은, 첫번째 레이어에 대해서만 forward backword를 inner loop만큼 수행하는 것으로 이해했습니다. 각 레이어에 대한 gradient chain을 생각해보면, 첫번째 레이어(f_0)의 입력에 대한 그레디언트와 나머지 레이어(g())들의 첫번째 레이어에 대한 그레디언트의 곱으로 표현이 될텐데, 이 때, 나머지 레이어들을 constant로 생각하고 inner loop (N번 첫번째 레이어에 대한 gradient로 sample을 업데이트)를 진행하면서 outer loop (M번 전체 forward backward)를 진행하게 되는데, 이 때, M을 줄이고 N을 늘려줌으로써 비슷한 성능을 유지하면서 적은 computation cost를 달성했다고 합니다.
- Initializing SGLD chain from a distribution estimated from training data
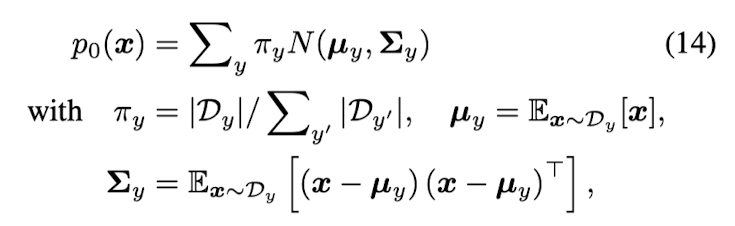

initial sampling distribution을 categorical center distribution으로 설정하는 것이 random noise로 initial sample을 설정하는 것보다 훨씬 converge가 빠르며, real data manifold에 더 가깝게 샘플이 생성될 수 있습니다. 이를 통해 training stability를 상승시켰다고 합니다.