2022.07.15 연구실 공부(PyTorch). 'PyTorch로 시작하는 딥 러닝 입문'< 이 글은 이 책의 내용을 요약 정리한 것임.>(내 저작물이 아니고 저 위 링크에 있는 것이 원본임)
09 단어의 표현 방법
Summary
- One-hot Encoding in NLP
- Word Embedding
- Word2Vec
- Glove
- nn.Embedding() in PyTorch
1. One-hot Encoding in NLP
- 단어 집합의 크기가 곧 벡터의 차원, 표현하고 싶은 단어의 인덱스는 1, 다른 인덱스에는 0으로 부여하는 단어의 벡터 표현 방식 -> One-hot Vector
(1) 각 단어에 고유한 인덱스를 부여 (정수 인코딩)
(2) 표현하고 싶은 단어의 인덱스의 위치에 1, 다른 단어의 인덱스의 위치에는 0 부여
1-1. One-hot Encoding in Korean
- koNLP를 통한 간단한 한국어 One-hot Encoding 예제
pip install konlpy- 예시 문장 : 나는 자연어 처리를 배운다
from konlpy.tag import Okt
okt = Okt()
token = okt.morphs("나는 자연어 처리를 배운다")
print(token)- Okt 형태소 분석기를 통해서 우선 문장에 대해서 토큰화를 수행 -> 각 토큰에 대해서 고유한 인덱스(index)를 부여
word2index = {}
for voca in token:
if voca not in word2index.keys():
word2index[voca] = len(word2index)
print(word2index)
{'나': 0, '는': 1, '자연어': 2, '처리': 3, '를': 4, '배운다': 5} - 토큰을 입력하면 해당 토큰에 대한 원-핫 벡터를 만들어내는 함수 정의
def one_hot_encoding(word, word2index):
one_hot_vector = [0]*(len(word2index))
index = word2index[word]
one_hot_vector[index] = 1
return one_hot_vectorprint(one_hot_encoding("자연어",word2index))[0, 0, 1, 0, 0, 0]- '자연어'라는 토큰을 입력 -> [0, 0, 1, 0, 0, 0]라는 벡터 출력 -> '자연어'에 해당하는 인덱스 2의 값은 1, 나머지는 0
1-2. Limitation of One-hot Encoding
- 단어가 늘어날 수록 벡터에 저장하기 위해 공간이 계속 증가 -> 차원 수가 큰 폭으로 증가
- 단어가 1000개인 Corpus에서 단어 하나를 표현하기 위해 999개는 전부 0이므로 공간적으로 매우 비효율적
- 단어의 유사도를 표현하지 못함 -> 늑대, 호랑이, 강아지, 고양이라는 4개의 단어에 대해서 원-핫 인코딩을 해서 각각, [1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]이라는 원-핫 벡터를 부여 -> 원-핫 벡터로는 강아지와 늑대가 유사하고, 호랑이와 고양이가 유사하다는 것을 표현할 수 없음
2. Word Embedding
2-1. Sparse Representation
- One-hot Vector : Sparse Representation의 하나, 해당 단어의 인덱스 값만 1이고 나머지는 전부 0이므로 대부분 0으로 표현 -> 공간적 낭비, 단어간 유사도도 구하기 어려움
2-2. Dense Representation
- 벡터의 차원을 단어 집합의 크기로 상정X(Sparse Representation) -> 사용자가 설정한 값 = 모든 단어의 벡터 표현의 차원(Dense Representation), 0과 1만 가진 값X(Sparse Representation) -> 실수값(Dense Representation)
- 이렇게 표현된 벡터를 Dense vector라 한다.
2-3. Word Embedding
- Word Embedding : 밀집 벡터(dense vector)의 형태로 표현하는 방법 -> 이 결과 나오는 벡터가 임베딩 벡터(embedding vector)
- Ex) LSA, Word2Vec, FastText, Glove
- PyTorch의 nn.embedding()는 단어를 랜덤한 값을 가지는 밀집 벡터로 변환하고 인공 신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습
| - | One-hot Vector | Embedding Vector |
|---|---|---|
| 차원 | 고차원(단어 집합의 크기) | 저차원 |
| 다른 표현 | 희소 벡터의 일종 | 밀집 벡터의 일종 |
| 표현 방법 | 수동 | 훈련 데이터로부터 학습함 |
| 값의 타입 | 1과 0 | 실수 |
3. Word2Vec
3-1. distributed representation
- Sparse Representation은 단어간 유사도를 표현할 수 없다는 단점이 있음 -> 단어의 '의미'를 다차원 공간에 벡터화하는 방법 -> 분산 표현(distributed representation) -> 임베딩 벡터(embedding vector) 혹은 밀집 벡터(dense vector)
- 분산 표현(distributed representation) 방법은 기본적으로 분포 가설(distributional hypothesis)이라는 가정 하에 만들어진 표현 방법(저차원에 단어의 의미를 여러 차원에다가 분산)
- 분포 가설(distributional hypothesis) : 비슷한 위치에서 등장하는 단어들은 비슷한 의미
를 갖는다는 가설 -> '귀엽다, 예쁘다, 애교'는 의미적으로 비슷 -> 벡터에서도 의미적으로 가까운 벡터 - 분산 표현을 통한 벡터들은 원-핫 벡터처럼 벡터의 차원이 단어 집합(vocabulary)의 크기일 필요가 없으므로, 벡터의 차원이 상대적으로 저차원으로 줄어듦
- 학습 방법 예시 : NNLM, RNNLM, Word2Vec
3-2. Continuous Bag of Words(CBOW)
- 예문 : The fat cat sat on the mat"
- {"The", "fat", "cat", "on", "the", "mat"}으로부터 sat을 예측
- Center word : 예측해야하는 단어, Context word : 예측에 사용되는 단어들
- Window : 중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지에 대한 크기(Window 크기가 n이면 주변 단어 개수는 2n)
- Ex) 윈도우 크기가 2이고, 예측하고자 하는 중심 단어가 sat이라고 한다면 앞의 두 단어인 fat와 cat, 그리고 뒤의 두 단어인 on, the를 참고
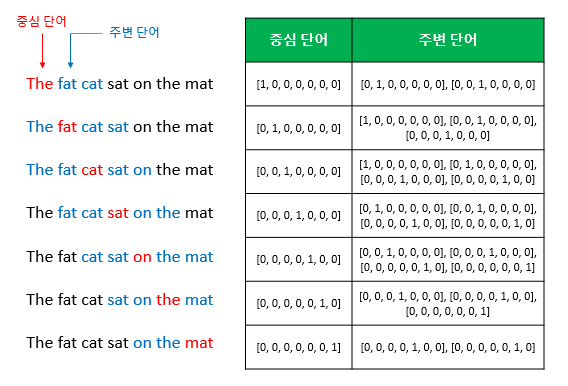
- 슬라이딩 윈도우(sliding window) : 윈도우를 계속 움직여서 주변 단어와 중심 단어 선택을 바꿔가며 학습을 위한 데이터 셋 생성하는 방법
- CBOW의 ANN 도식화
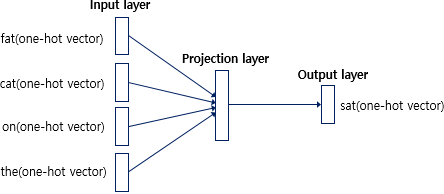
- 입력층(Input layer) : 윈도우 크기 범위 안에 있는 주변 단어들의 원-핫 벡터 입력
- 출력층(Output layer) : 예측하고자 하는 중간 단어의 원-핫 벡터가 필요
- Word2Vec은 딥러닝(Deep Learning)은 아니다! -> 은닉층의 개수가 충분히 쌓인 신경망을 학습하는 경우 딥러닝이지만 Word2Vec는 은닉층이 하나이므로 얕은신경망(Shallow Neural Network)이다.
- 은닉층(Hidden Layer) : 활성화 함수가 존재하지 않으며 룩업 테이블이라는 연산을 담당하는 층 -> 일반적인 은닉층과 구분하기 위해 투사층(Projection Layer)이라고 부르기도 함
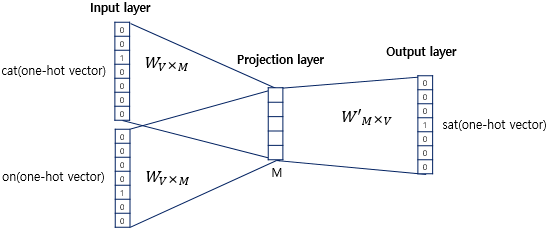
- CBOW에서 Projection Layer의 크기 M = 임베딩하고 난 벡터의 차원
- Input layer과 Projection Layer 사이의 가중치 W는 (V × M) Matrix
- Projection Layer에서 Output layer 사이의 가중치 W'는 (M × V) Matrix
- 위 두 행렬(W, W')는 전치(Transpose)한 것이 아니라 서로 다른 행렬
- CBOW는 주변 단어로 중심 단어를 더 정확히 맞추기 위해 계속해서 이 W와 W'를 학습
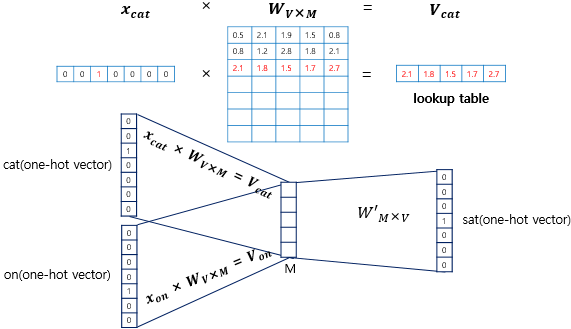
- 룩업 테이블(lookup table) : i번째 인덱스에 1이라는 값을 가지고 그 외의 0의 값을 가지는 입력 벡터와 가중치 W 행렬의 곱
- lookup table은 사실 W행렬의 i번째 행을 그대로 읽어오는 과정(lookup)과 동일
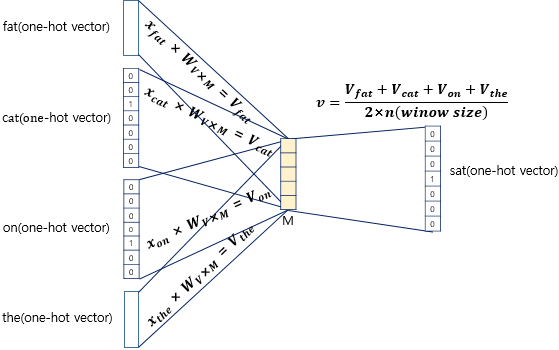
- 각 주변 단어의 원-핫 벡터에 대해서 가중치 W가 곱해서 생겨진 결과 벡터들은 투사층에서 만나 이 벡터들의 평균인 벡터 구하기 -> 윈도우 크기가 2라면, 입력 벡터의 총 개수는 2n -> 중간 단어를 예측하기 위해서는 총 4개가 입력 벡터로 사용(이때, 평균을 구하는 것은 CBOW의 특징으로 후에 나올 Skip-Gram방식은 평균을 구할 필요가 없음)
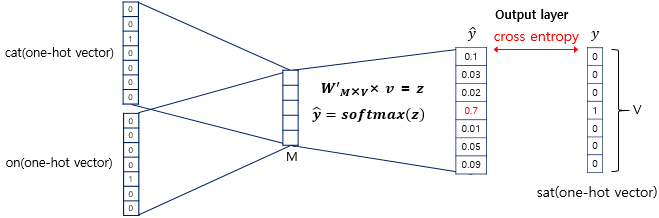
- 이렇게 구해진 평균 벡터는 두번째 가중치 행렬 W'와 곱 -> 곱셈의 결과로는 원-핫 벡터들과 차원이 V로 동일한 벡터 -> 소프트맥스(softmax) 함수 -> 출력값은 0과 1사이의 실수로, 각 원소의 총 합은 1이 되는 상태로 변환 -> 스코어 벡터(score vector)
- 스코어 벡터의 j번째 인덱스가 가진 0과 1사이의 값은 j번째 단어가 중심 단어일 확률 -> 중심 단어 원-핫 벡터의 값에 가깝도록 학습 -> 스코어 벡터(y-hat), 중심 단어(y)일 때, 두 벡터값의 오차를 줄이기 위해 CBOW는 손실 함수(loss function)로 cross-entropy 함수 사용
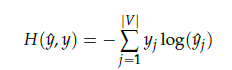
- cross-entropy 함수에 실제 중심 단어인 원-핫 벡터와 스코어 벡터를 입력값으로 표현한 경우
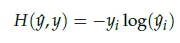
- 이 값을 최소화하는 방향으로 학습해야 한다!
3-3. Skip-gram
- 메커니즘 자체는 CBOW와 Skip-gram은 동일, CBOW에서는 주변 단어를 통해 중심 단어를 예측했다면, Skip-gram은 중심 단어에서 주변 단어를 예측
- Skip-gram의 ANN 도식화
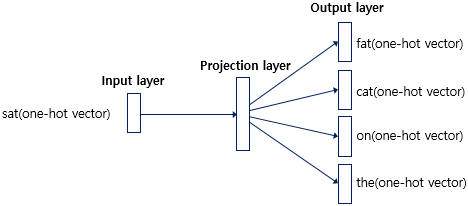
- 전반적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려짐
3-4. Negative Sampling
- 대체적으로 Word2Vec를 사용한다고 하면 SGNS(Skip-Gram with Negative Sampling)을 사용 -> Skip-gram을 사용하는데, 네거티브 샘플링(Negative Sampling)이란 방법까지 추가로 사용
- Word2Vec의 단점 : 속도(소프트맥스 함수는 단어 집합 크기의 벡터 내의 모든 값을 0과 1사이의 값이면서 모두 더하면 1이 되도록 바꾸는 작업을 수행 -> 이에 대한 오차를 구하고 모든 단어에 대한 임베딩을 조정 -> 단어 집합의 크기가 수백만에 달한다면 이 작업은 굉장히 무거운 작업)
- 전체 단어 집합이 아니라 일부 단어 집합에 대해서만 고려
- Ex) '강아지', '고양이', '애교'와 같은 주변 단어들 -> '돈가스', '컴퓨터', '회의실'과 같은 랜덤으로 선택된 주변 단어가 아닌 상관없는 단어들을 일부 -> Word2Vec은 주변 단어들을 긍정(positive)으로 두고 랜덤으로 샘플링 된 단어들을 부정(negative)으로 둔 다음에 이진 분류 문제를 수행 -> 연산량에 있어서 훨씬 효율적
4. Glove
- LSA는 카운트 한 행렬(전체적인 통계 정보)을 입력으로 받아 차원을 축소(Truncated SVD)하여 잠재된 의미를 끌어내는 방법론 -> 유추 작업(Analogy task)에는 성능 저하
- Word2Vec는 실제값과 예측값에 대한 오차를 손실 함수를 통해 줄여나가며 학습하는 예측 기반의 방법론 -> 코퍼스의 전체적인 통계 정보를 반영X
- GloVe는 이러한 기존 방법론들의 각각의 한계를 지적 -> LSA의 메커니즘이었던 카운트 기반의 방법과 Word2Vec의 메커니즘이었던 예측 기반의 방법론 두 가지를 모두 사용
4-1. Window based Co-occurrence Matrix
- 행과 열을 전체 단어 집합의 단어들로 구성, i 단어의 윈도우 크기(Window Size) 내에서 k 단어가 등장한 횟수를 i행 k열에 기재한 행렬
- 예문 : I like deep learning, I like NLP, I enjoy flying
| 카운트 | I | like | enjoy | deep | learning | NLP | flying |
|---|---|---|---|---|---|---|---|
| I | 0 | 2 | 1 | 0 | 0 | 0 | 0 |
| like | 2 | 0 | 0 | 1 | 0 | 1 | 0 |
| enjoy | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| deep | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| learning | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| NLP | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| flying | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
- 위 행렬은 행렬을 전치(Transpose)해도 동일한 행렬 -> i 단어의 윈도우 크기 내에서 k 단어가 등장한 빈도는 반대로 k 단어의 윈도우 크기 내에서 i 단어가 등장한 빈도와 동일하므로
4-2. Co-occurrence Probability
- Co-occurrence Probability : 동시 등장 행렬로부터 특정 단어 i의 전체 등장 횟수를 카운트, 특정 단어 i가 등장했을 때 어떤 단어 k가 등장한 횟수를 카운트 -> 조건부 확률
- P(k|i) : i를 중심 단어(Center Word), k를 주변 단어(Context Word)라 할때, (i행 k열의 값 / 중심 단어 i의 행의 모든 값을 더한 값)
| 동시 등장 확률과 크기 관계 비(ratio) | k=solid | k=gas | k=water | k=fasion |
|---|---|---|---|---|
| P(k l ice) | 0.00019 | 0.000066 | 0.003 | 0.000017 |
| P(k l steam) | 0.000022 | 0.00078 | 0.0022 | 0.000018 |
| P(k l ice) / P(k l steam) | 8.9 | 0.085 | 1.36 | 0.96 |
- 위 표를 통해 'ice가 등장했을 때 solid가 등장할 확률 = P(solid | ice)' 0.00019은 'steam이 등장했을 때 solid가 등장할 확률 = P(solid | steam)'인 0.000022보다 약 8.9배 크다는 사실을 알 수 있음
- solid는 '단단한'이라는 의미를 가졌으니까 '증기'라는 의미를 가지는 steam보다는 당연히 '얼음'이라는 의미를 가지는 ice라는 단어와 더 자주 등장
- k가 solid일 때, P(solid l ice) / P(solid l steam)를 계산한 값은 8.9 -> 이 값은 1보다는 매우 큰 값(P(solid | ice)의 값은 크고, P(solid | steam)의 값은 작기 때문)
- k를 solid가 아니라 gas로 바꾸면, gas는 ice보다는 steam과 더 자주 등장 -> P(gas l ice) / P(gas l steam)를 계산한 값은 1보다 훨씬 작은 값인 0.085
- k가 water인 경우에는 solid와 steam 두 단어 모두와 동시 등장하는 경우가 많으므로 1에 가까운 값
- k가 fasion인 경우에는 solid와 steam 두 단어 모두와 동시 등장하는 경우가 적으므로 1에 가까운 값
| 동시 등장 확률과 크기 관계 비(ratio) | k=solid | k=gas | k=water | k=fasion |
|---|---|---|---|---|
| P(k l ice) | 큰 값 | 작은 값 | 큰 값 | 작은 값 |
| P(k l steam) | 작은 값 | 큰 값 | 큰 값 | 작은 값 |
| P(k l ice) / P(k l steam) | 큰 값 | 작은 값 | 1에 가까움 | 1에 가까움 |
4-3. Loss function
- 용어 정리

- GloVe의 아이디어 : '임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률이 되도록 만드는 것'
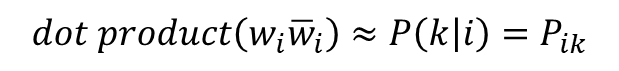
- 더 정확히는 아래와 같음(log)
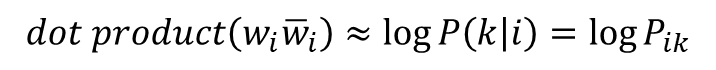
- 이 손실함수는 단어 간의 관계를 잘 표현하는 함수여야 하므로 앞에 배운 개념인 P_ik/P_jk를 식에 사용
- 초기 식
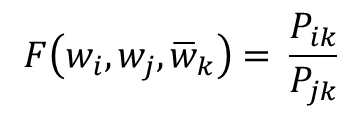
- 함수 F는 두 단어 사이의 동시 등장 확률의 크기 관계 비(ratio) 정보를 벡터 공간에 인코딩하는 것이 목적 -> w_i - w_j를 F의 입력으로 사용하는 것을 GloVe 연구진들은 제안
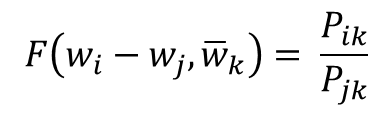
- 우변은 스칼라값이고 좌변은 벡터값 -> F의 두 입력에 내적(Dot product)을 수행
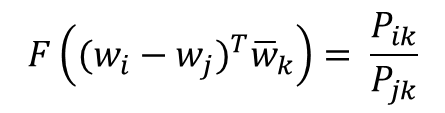
- 정리 : 선형 공간(Linear space)에서 단어의 의미 관계를 표현하기 위해 뺄셈과 내적을 택함
- 중심 단어 w와 주변 단어 w_bar라는 선택 기준은 실제로는 무작위 선택 -> 이 둘의 관계는 자유롭게 교환될 수 있도록 해야함 -> GloVe 연구진은 함수 가 실수의 덥셈과 양수의 곱셈에 대해서 준동형(Homomorphism)을 만족하도록 함 -> 아래 식으로 표현 가능
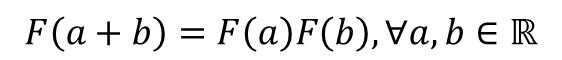
- GloVe 식에 따르면, 함수 F는 결과값으로 스칼라 값(P_ik/P_jk)이 나와야 함
- 준동형식에서 a와 b가 각각 벡터값이라면 함수 F의 결과값으로는 스칼라 값이 나올 수 없지만, a와 b가 각각 사실 두 벡터의 내적값이라고 하면 결과값으로 스칼라 값이 나올 수 있음
- 위의 준동형식을 아래와 같이 바꿀 수 있음(v1, v2, v3, v4는 각각 벡터값, V는 벡터)
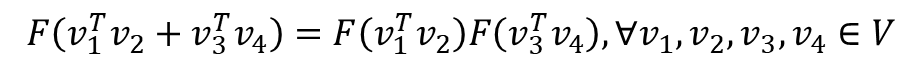
- GloVe 식에 바로 적용을 위해 준동형 식을 이를 뺄셈에 대한 준동형식으로 변경 -> 곱셈도 나눗셈으로 바뀜
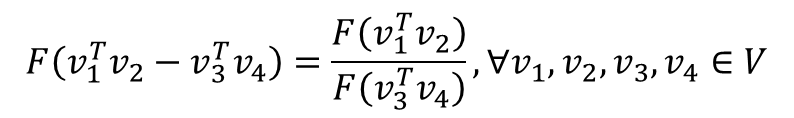
- 이 준동형 식을 GloVe 식에 적용
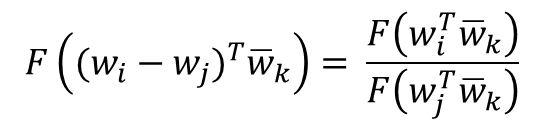
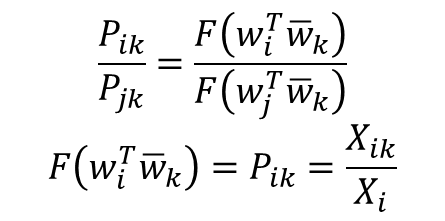
- 좌변을 풀어쓰면 다음과 같은데 이는 뺄셈에 대한 준동형식의 형태와 정확히 일치
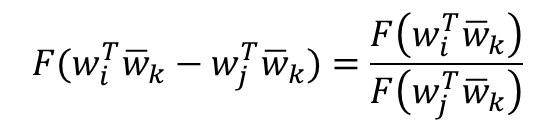
- 이를 정확하게 만족시키는 함수가 있는데 바로 지수 함수(Exponential function)
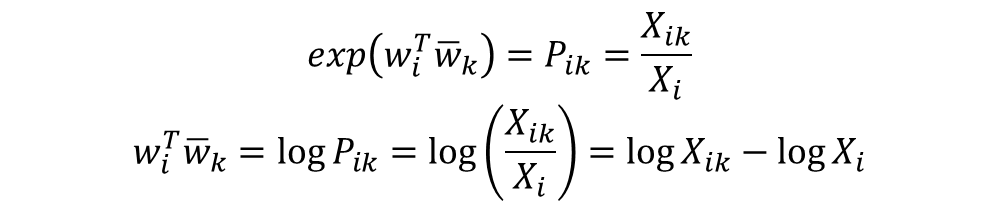
- 중심 단어 w와 주변 단어 w_bar는 두 값의 위치를 서로 바꾸어도 식이 성립해야 함 -> 이게 성립하려면 log(X_i)항이 걸림돌 -> log(X_i)항을 w_i에 대한 편향 b_i라는 상수항으로 대체
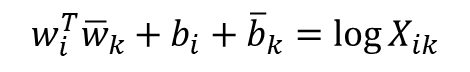
- 우변의 값과의 차이를 최소화는 방향으로 좌변의 4개의 항은 학습을 통해 값이 바뀌는 변수들이 됨 -> 손실 함수는 다음과 같이 일반화
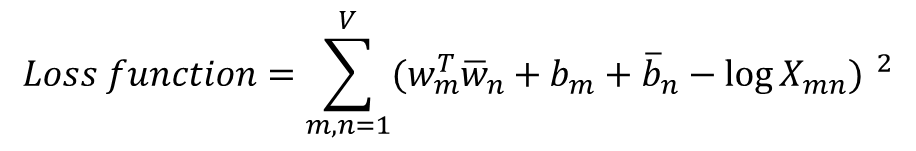
- V는 단어 집합의 크기, X_ik값이 0이 될 수 있음 -> log(1+X_ik)로 변경
- 동시 등장 행렬 X가 DTM처럼 희소 행렬(Sparse Matrix)일 가능성이 다분하다는 점이 문제 -> 동시 등장 행렬에서 동시 등장 빈도의 값 X_ik이 굉장히 낮은 경우에는 정보에 거의 도움이 되지 않는다고 판단
- GloVe 연구팀은 X_ik의 값에 영향을 받는 가중치 함수(Weighting function) f(X_ik)를 손실 함수에 도입
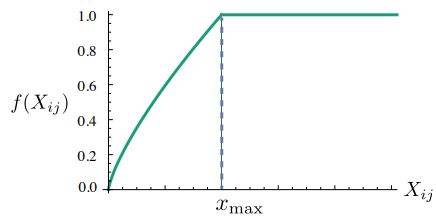
- X_ik의 값이 작으면 상대적으로 함수의 값은 작도록 하고, 값이 크면 함수의 값은 상대적으로 크도록 함 -> X_ik이 지나치게 높으면 함수의 최대값(함수의 최대값이 고정됨) -> 이 함수의 값을 손실 함수에 곱해주면 가중치의 역할
- 이 함수 f(x)의 식은 다음과 같이 정의
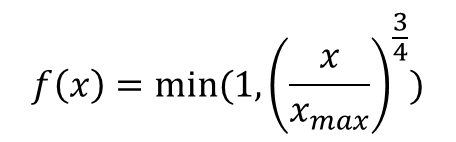
- f(x)까지 적용한 일반화된 손실 함수는 다음과 같다
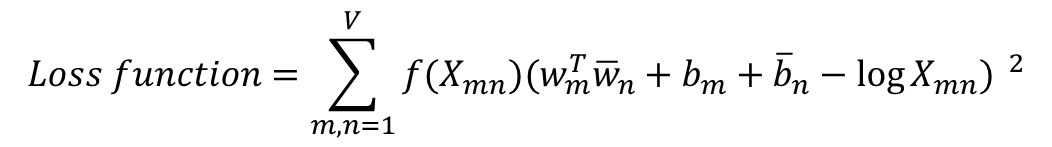
5. nn.Embedding() in PyTorch
5-1. 임베딩 층은 룩업 테이블이다
- 입력 시퀀스의 각 단어들은 모두 정수 인코딩되어야 함
어떤 단어 → 단어에 부여된 고유한 정수값 → 임베딩 층 통과 → 밀집 벡터
- 임베딩 층은 입력 정수에 대해 밀집 벡터(dense vector)로 맵핑하고 이 밀집 벡터는 인공 신경망의 학습 과정에서 가중치가 학습되는 것과 같은 방식으로 훈련
- 훈련 과정에서 단어는 모델이 풀고자하는 작업에 맞는 값으로 업데이트 -> 밀집 벡터를 임베딩 벡터라 부른다
- 정수를 밀집 벡터 또는 임베딩 벡터로 맵핑한다는 것 : 특정 단어와 맵핑되는 정수를 인덱스로 가지는 테이블로부터 임베딩 벡터 값을 가져오는 룩업 테이블, 모든 단어는 고유한 임베딩 벡터를 가짐
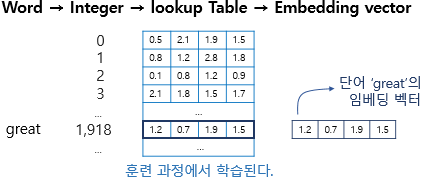
- 위의 그림은 단어 great이 정수 인코딩 된 후 테이블로부터 해당 인덱스에 위치한 임베딩 벡터를 꺼내오는 모습
- 임베딩 벡터의 차원이 4, 단어 great은 정수 인코딩 과정에서 1,918의 정수로 인코딩, 단어 집합의 크기만큼의 행을 가지는 테이블에서 인덱스 1,918번에 위치한 행을 단어 great의 임베딩 벡터로 사용, 임베딩 벡터는 모델의 입력, 역전파 과정에서 단어 great의 임베딩 벡터값이 학습
- PyTorch는 단어를 정수 인덱스로만 바꾼채로 임베딩 층의 입력으로 사용해도 룩업 테이블 된 결과인 임베딩 벡터를 리턴
train_data = 'you need to know how to code'
# 중복을 제거한 단어들의 집합인 단어 집합 생성.
word_set = set(train_data.split())
# 단어 집합의 각 단어에 고유한 정수 맵핑.
vocab = {word: i+2 for i, word in enumerate(word_set)}
vocab['<unk>'] = 0
vocab['<pad>'] = 1
print(vocab){'code': 2, 'you': 3, 'know': 4, 'to': 5, 'need': 6, 'how': 7, '<unk>': 0, '<pad>': 1}- 단어 집합의 크기를 행으로 가지는 임베딩 테이블을 구현(임베딩 벡터의 차원은 3)
# 단어 집합의 크기만큼의 행을 가지는 테이블 생성.
embedding_table = torch.FloatTensor([
[ 0.0, 0.0, 0.0],
[ 0.0, 0.0, 0.0],
[ 0.2, 0.9, 0.3],
[ 0.1, 0.5, 0.7],
[ 0.2, 0.1, 0.8],
[ 0.4, 0.1, 0.1],
[ 0.1, 0.8, 0.9],
[ 0.6, 0.1, 0.1]])- 임의의 문장 'you need to run'에 대해서 룩업 테이블을 통해 임베딩 벡터들 가져오기
sample = 'you need to run'.split()
idxes = []
# 각 단어를 정수로 변환
for word in sample:
try:
idxes.append(vocab[word])
# 단어 집합에 없는 단어일 경우 <unk>로 대체된다.
except KeyError:
idxes.append(vocab['<unk>'])
idxes = torch.LongTensor(idxes)
# 각 정수를 인덱스로 임베딩 테이블에서 값을 가져온다.
lookup_result = embedding_table[idxes, :]
print(lookup_result)tensor([[0.1000, 0.5000, 0.7000],
[0.1000, 0.8000, 0.9000],
[0.4000, 0.1000, 0.1000],
[0.0000, 0.0000, 0.0000]])5-2. 임베딩 층 사용하기
- nn.Embedding()을 사용하여 학습가능한 임베딩 테이블을 만들기
import torch.nn as nn
embedding_layer = nn.Embedding(num_embeddings=len(vocab),
embedding_dim=3,
padding_idx=1)- num_embeddings : 임베딩을 할 단어들의 개수. 다시 말해 단어 집합의 크기
- embedding_dim : 임베딩 할 벡터의 차원. 사용자가 정해주는 하이퍼파라미터
- padding_idx : 선택적으로 사용하는 인자. 패딩을 위한 토큰의 인덱스를 알려줌
print(embedding_layer.weight)Parameter containing:
tensor([[-0.1778, -1.9974, -1.2478],
[ 0.0000, 0.0000, 0.0000],
[ 1.0921, 0.0416, -0.7896],
[ 0.0960, -0.6029, 0.3721],
[ 0.2780, -0.4300, -1.9770],
[ 0.0727, 0.5782, -3.2617],
[-0.0173, -0.7092, 0.9121],
[-0.4817, -1.1222, 2.2774]], requires_grad=True)출처 : 'PyTorch로 시작하는 딥 러닝 입문' <이 책의 내용을 요약 정리한 것임.>

매일 매일 새로워지는 나 자신을 꿈꾸며