problem
- 검색엔진을 위해서 데이터 파이프라인을 구축해야할 필요성 존재
- 데이터베이스 종류가 매번 다름
- Elastic Search, Neo4j 등 다양한 데이터베이스에 활용하기 위해서 많은 어플리케이션 개발이 필요할 것으로 보임
Solution
기초 용어
CDC (Change Data Capture)
로그를 읽어 변경을 반영하는 방법
ETL (Extract + Transform + Load)
아키텍처 구성
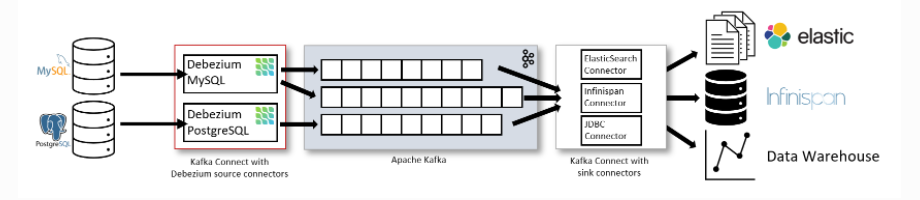
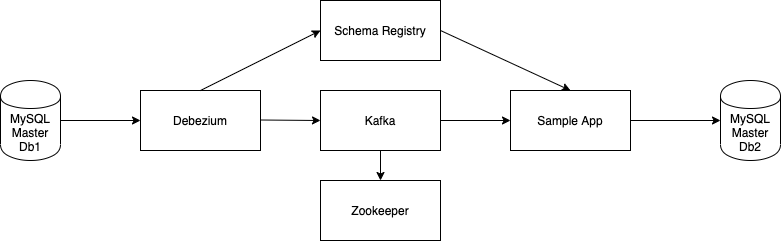
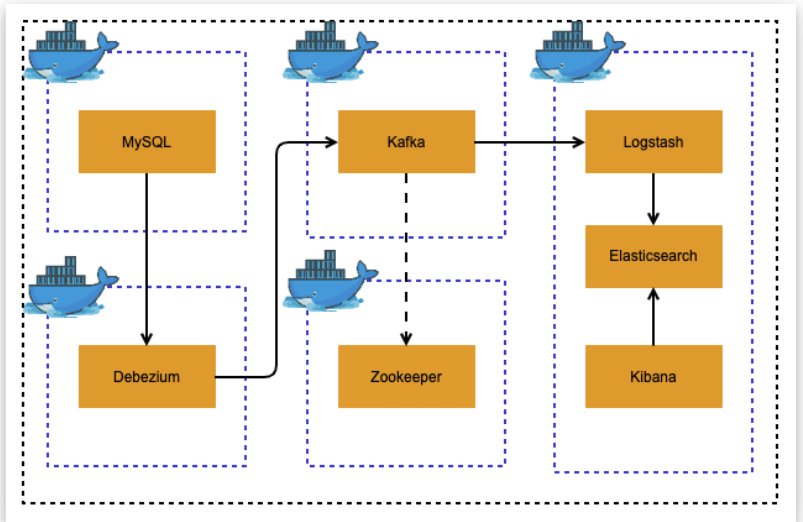
-
원본 DB
-
Connector (Debezium)
- 원본 데이터 베이스에 리플리케이션 클라이언트로 붙어서 사용
- 데이터 변경을 캡처하고, 변경 메시지를 카프카에 프로듀싱 하는 역할
- MS-SQL, MySQL, Postgre... 등 여러 데이터베이스와 연동 가능
-
Schema Registry
직렬화, 역직렬화 규격을 사용
-
kafka cluster
단일 혹은 여러 브로커로 구성된 클러스터
-
ZooKeeper
- 분산 코디네이션 시스템으로, 카프카 클러스터의 정보를 관리, 리더 선출, 잠금, 동기화를 위해 사용
-
Connector
- 카프카 토픽에서 읽어낸 메시지를 처리하여 읽어내는 애플리케이션
- 주로 데이터를 변형하거나 가공하여 대상 데이터베이스에 적용하는 로직을 수행
-
최종 DB
CDC 사용 장점
- DBMS의 Transaction log를 통해 변경데이터를 분석하기때문에 데이터 변경사항이 100% 보장
- 쿼리를 통한 데이터 추출이 아니기때문에 DBMS에 부하가 적음
- 쿼리를 통한 ‘폴링’방식의 데이터 추출시 최종 데이터 변경 내용만 조회 되기 때문에 모든 데이터 변경 내용을 캡쳐하기 어려울수 있음. CDC는 기록되어있는 트랜잭션 로그를 통해 중간에 발생한 모든 변경로그를 조회 할 수 있음
- 삭제된 데이터도 캡쳐가 가능
- 실시간 처리가 가능
- CDC를 사용할수있는 여러 오픈소스가 많으나, Kafka와 가장 친화적인 오픈소스로 Debezium이 최고
- 레드햇에서 지원
- 데이터 덤프 + CDC 기능 가능
- PostgreSQL, MongoDB, MySQL, Oracle, Amazon RDS, SQL Server, Cassandra를 지원
- 아파치 라이센스
참고

Mechanical & Computer Science