Overview
- 비전에서 다루는 문제들은 5가지 종류가 있다고 한다.
- Classification : Single object에 대해서 object의 클래스를 분류하는 문제
- Classification + Localization : Single object에 대해서 object의 위치를 bounding box로 찾고 (Localization) + 클래스를 분류하는 문제이다. (Classification)
- Object Detection : Multiple objects에서 각각의 object에 대해 Classification + Localization을 수행하는 것
- Image Segmentation : Object Detection과 유사하지만, 다른점은 object의 위치를
bounding box가 아닌 실제 edge로 찾는 것 - Visual Relationship : 관계를 나타내는 그래프를 제한하는 방법으로 객체와 술어를 분류하거나 종단 간의 네트워크를 학습하여 관계를 직접 예측한다.
- R-CNN은 여기서 Object Detection과 관련되어 있다
- Object Detection에서는 대부분 2가지 방법이 있다
- 1-stage detector
- 2-stage detector
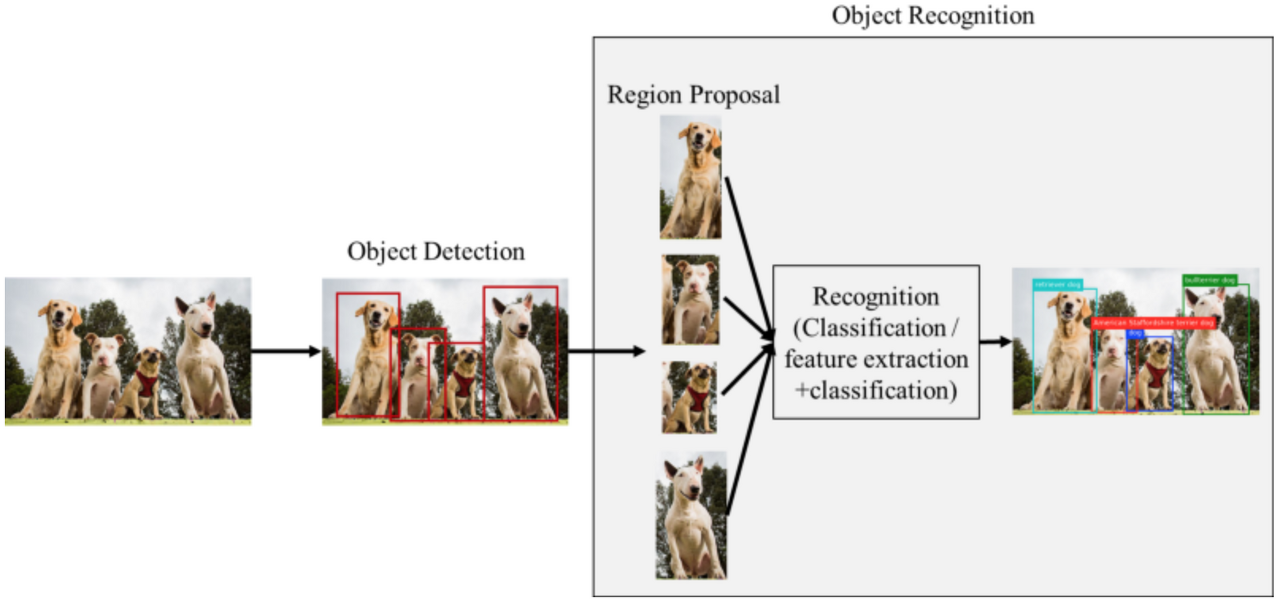
- 위 그림은 2-stage detector의 예시이다.
- Selective Search || Region Propersal Network 와 같은 단계를 통해 먼저 OBJECT 가 있을 법한 영역을 뽑아내는 것이 특징이다.
- 이미지에서 색감, 질감 .. 등 특성을 뽑아내서 여기에는 무슨 물체가 있구나! 하고 감지하는 알고리즘이다
- 위 단계를 RoI(Region of Interest) 라고 한다.
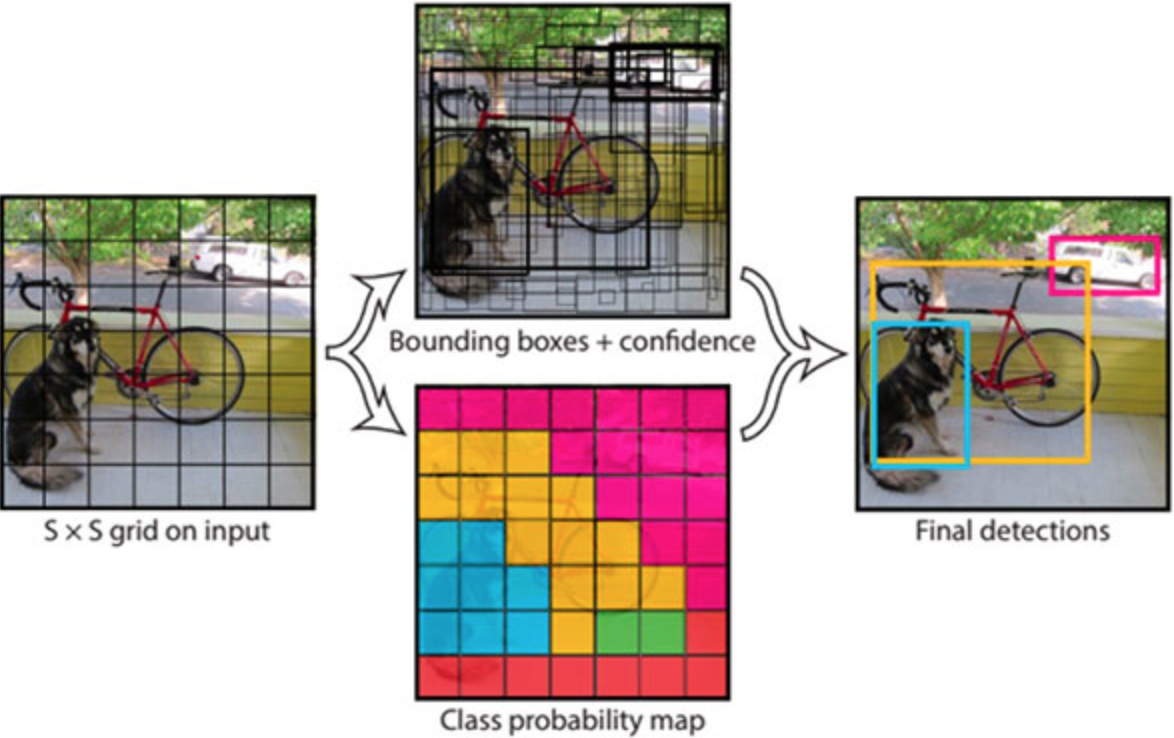
- RoI를 검출한 다음 단계는 CNN을 이용해서 Classification 작업이 들어간다.
- Box Regression 을 진행하기도 한다.
- 의심되는 특정 OBJECT 를 담고 있는 RoI에서 수행하는 만큼 일반 이미지를 전체 넣어버리는 거보다 성능이 당연히 좋다.
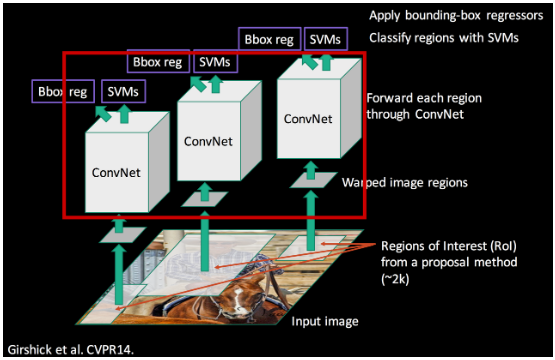
R-CNN
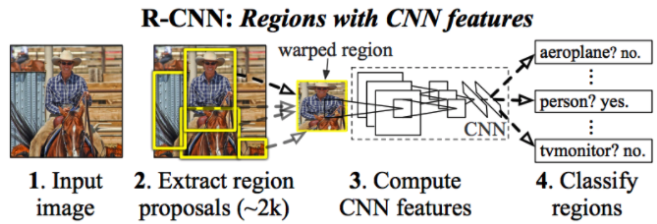
- r-cnn은 Image Classification을 위한 CNN과 Localization 을 위한 Regional Proposal 알고리즘을 연결한 모델이다. 수행 과정은 아래와 같다.
- Image를 입력받는다.
- Selective search알고리즘에 의해 regional proposal output 약 2000개를 추출한다.
추출한 regional proposal output을 모두 동일 input size로 만들어주기 위해 warp해준다.- 2000개의 warped image를 각각 CNN 모델에 넣는다.
- 각각의 Convolution 결과에 대해 classification을 진행하여 결과를 얻는다.
- 3가지 단계로 나누어보면 아래와 같다.
- Regional Proposal : Localization
- CNN : Feature vector Extract
- SVM : Classification (supervised learning)
Regional Proposal
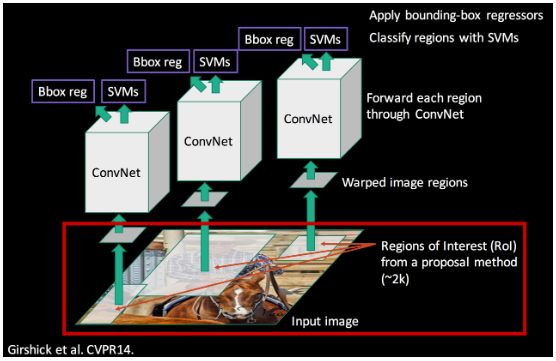
- 가장 먼저
물체가 있을 법한 영역을 찾는다. - Sliding Window 방식의 경우 비효율적이다라는 것을 잊지말자(윈도우 커널 사이즈도 달라야되고..)
- Selective Search 기법을 활용하면 훨씬 빠르다
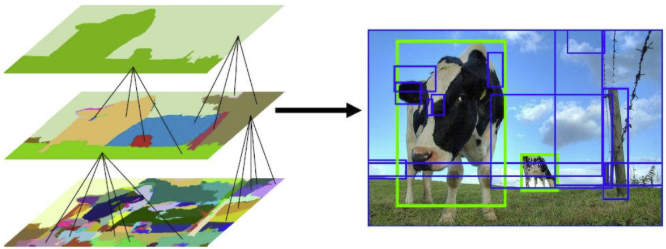
- 색상, 질감, 영역크기 등.. 을 이용해 non-object-based segmentation을 수행한다.
- Bottom-up 방식으로 small segmented areas들을 합쳐서 더 큰 segmented areas들을 만든다.
- (2)작업을 반복하여 최종적으로 2000개의 region proposal을 생성한다.
- 다음 단계인 CNN 에 Input 으로 활용하기 위해 같은 사이즈로 warp 시켜주도록 하자
CNN
- Warp 작업을 통해 region proposal 모두 224 x 224 크기로 되면 cnn 모델에 넣는다.
- AlexNet, ResNet 등을 활용하면 된다.
SVM
- CNN 모델로부터 feature extraction이 성공하면, Linear SVM을 통해 classification을 진행한다. softmax보다 svm이 성능이 좋기 때문에 사용했다고 한다.
Bounding Box Regression

- Selective search로 만든 Bounding Box(RoI) 는 정확히 물체를 감싸는 형태가 아닌 경우가 많다.
- 물체를 정확히 감쌀 수 있는 회귀 모델이 있어서 사용한다고 한다.

정리
- 다음과 같은 단계 순서대로 진행한다.
- R-CNN은 selective search를 통해 region proposal을 먼저 뽑아낸 후 CNN 모델에 들어간다.
- CNN모델에 들어가 feature vector를 뽑고 각각의 class마다 SVM로 classification을 수행한다.
- localization error를 줄이기 위해 CNN feature를 이용하여 bounding box regression model을 수정한다.
- 단점은 아래와 같다.
- 여기서 selective search로 2000개의 region proposal을 뽑고 각 영역마다 CNN을 수행하기 때문에 CNN연산 * 2000 만큼의 시간이 걸려 수행시간이 매우 느리다.
- CNN, SVM, Bounding Box Regression 총 세가지의 모델이 multi-stage pipelines으로 한 번에 학습되지 않는다. 각 region proposal 에 대해 ConvNet forward pass를 실행할때 연산을 공유하지 않기에 end-to-end 로 학습할 수 없다.
참조

Mechanical & Computer Science