Overview
사내에서 수강하는 AI 양성과정 교육을 들으면서 가볍게 넘어갔엇던 네트워크 모델들을 정리해보고자 한다. 시리즈의 순서는 큰 의미는 없고, 교수님이 가르쳐주시는 순서에 따르며 중요한 키워드나 이슈는 개인적으로 정리하는 만큼 필요한 것들 위주로 읽기를 추천한다. 또한 예제 소스코드는 깃허브에 올리기는 하겠으나 자세하게 하지는 않을 것이므로 생략하겠다.
Introduction
CNN 이 AlexNet 이후로 인기가 많아지고, 여러 챌린징한 문제들이 출제 및 해결되면서 Layer를 깊게 쌓을 수록 좋은 결과가 나오는 것이 유명해지기 시작했다. 하지만 너~무 깊은 Layer는 오히려 성능을 떨어트리는 문제를 발생시킨다. 이유는 gradient vanishing/exploding 문제 때문이다. 즉 편미분 과정에서 변수의 값이 0에 수렴하는 문제이다. backpropagation을 해도 앞에 위치한 Layer는 weight 변화가 미비해진다는 것이다. 이는 overfitting과는 다른 문제이다.
Overfitting : 학습데이터 기반으로 완벽하게 학습된 탓에 다른 테스트 케이스는 정답이 맞지 않는 경우를 의미
이를 극복하게 위해 나온 네트워크가 ResNet이다. Skip connection 을 이용해서 residual learning을 통해 Layer가 깊어짐에도 Gradient vanishing 문제가 해결된다.
ResNet
- 기존의 NN의 학습 목적은 input(x) 을 타겟(y) 으로 mapping 하는 함수 H(x) 를 찾는 것이다. 따라서
H(x) - y = Loss를 최소화 하는 방향으로 학습을 진행한다. - 이 때 이미지 classification과 같은 문제의 경우 x에 대한 타겟값 y 는 사실 x를 대변하는 것으로 y 와 x의 의미를 연결?(mapping) 해야한다는 아이디어가 핵심이다.
- 즉 일반적인 블랙박스 함수 y = H(x) 에 H를 찾아내려고 하는 것이 아닌, F(x) = H(x) - x 를 최소화 하는 방향으로 학습을 진행하는 것이 아이디어 이다.
일반적인 네트워크
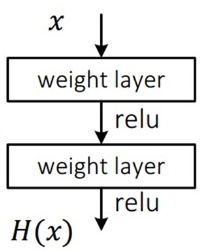
- 위 그림은 Input(x) 를 특정 함수에 넣어서 우리가 원하는 타겟 y 가 나오는 케이스이다.
ResNet
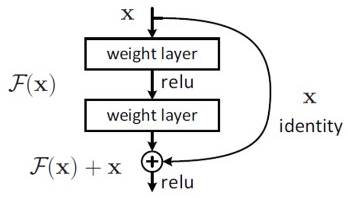
- 위 그림처럼 마지막에 x를 더해줌으로써 네트워크의 output이 0 이 되는 것에 집중할 수 있도록 학습하는 것이 키워드이다.
- 이를 Residual Learning이라고 한다.
- 만일 정답에 수렴한다면 H(x) 의 미분값은 1로 수렴한다는 것을 알 수 있다. 즉 기울기의 수렴값을 정해놓은 것이라고 이해하면 되고, 이를 통해서 Gradient Vanishing 문제를 해결할 수 있다.
BottleNeck 구조
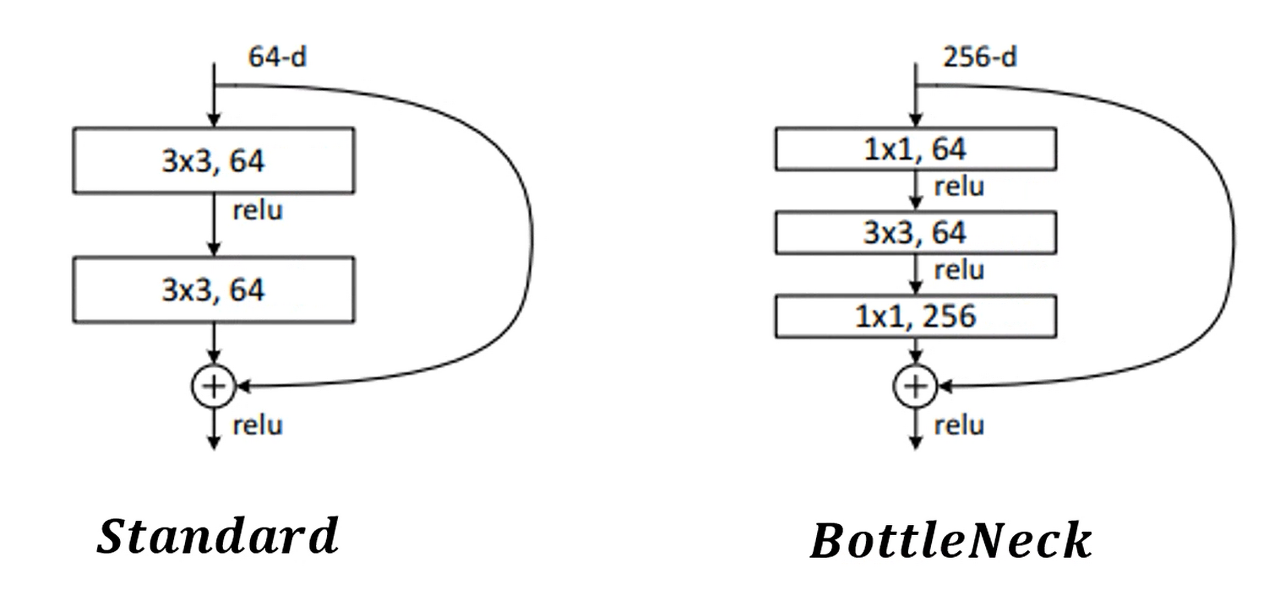
- 왼쪽은 위에서 언급한 Residual Learning 구조, 오른쪽은 BottleNeck 구조이다.
- BottleNeck의 핵심은 1x1 Convolution입니다.
- 예제를 통해서 파라미터 수를 계산해보면 아래와 같다.
- Input img (256, 320, 320) # channel x width x height
- Channel Compression : (64, 1, 1) 컨볼루션 (파라미터 수 = 1 1 256 * 64)
- Feature Extraction : (64, 3, 3) 컨볼루션 (파라미터 수 = 3 3 64 * 64)
- Channel Increase : (256, 1, 1) 컨볼루션 (파라미터 수 = 1 1 64 * 256)
Convolution Parameters = Kernel Size x Kernel Size x Input Channel x Output Channel
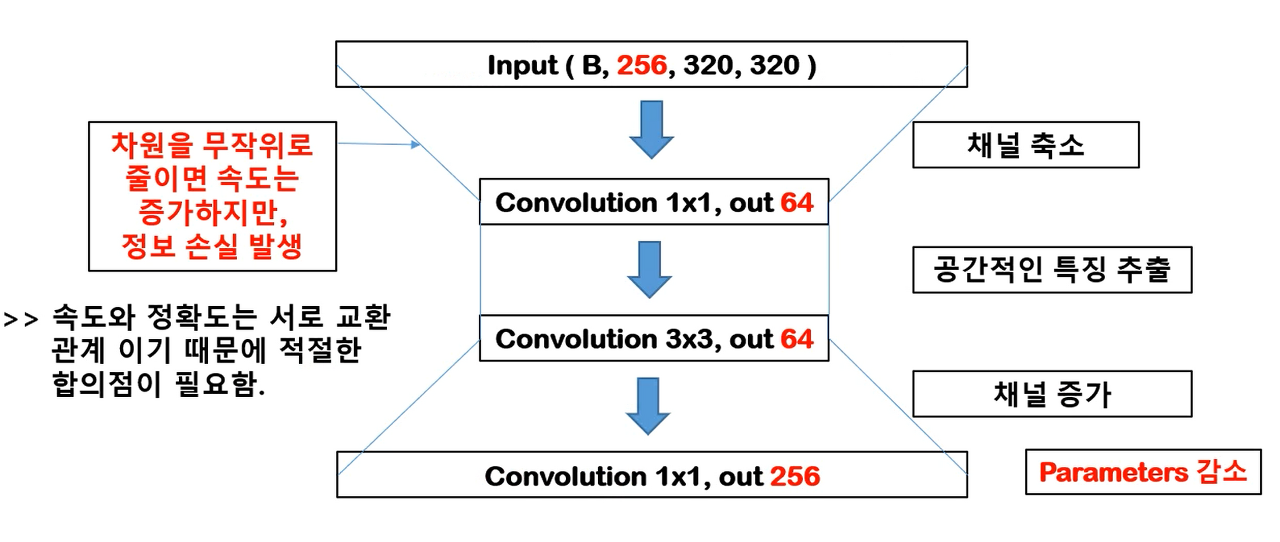
- 파라미터수가 일반적인 네트워크수에 비해 적은 것이 특징
- 위 구조를 보틀넥 구조라고 함
정리
- 이미지에서는 H(x) = x가 되도록 학습시킨다.
- 네트워크의 output F(x)는 0이 되도록 학습시킨다.
- F(x)+x=H(x)=x가 되도록 학습시키면 미분해도 F(x)+x의 미분값은 F'(x) + 1로 최소 1이상이다.
- 모든 layer에서의 gradient가 1+F'(x)이므로 gradient vanishing현상을 해결했다.
