

1. 미니프로젝트 6차
- 1 : Text 딥러닝
6차 미프의 첫번째 시간에는 "에이블스쿨 챗봇 만들기"를 주제로 이전에 배웠던 Text 딥러닝을 이용해보는 프로젝트를 진행했습니다.
(1) 데이터 전처리
에이블스쿨의 FAQ와 일상 질문을 섞어놓은 데이터를 가지고 intent의 분포를 살펴보고, 전체적인 문장 길이나 형태소를 분석해보았습니다.
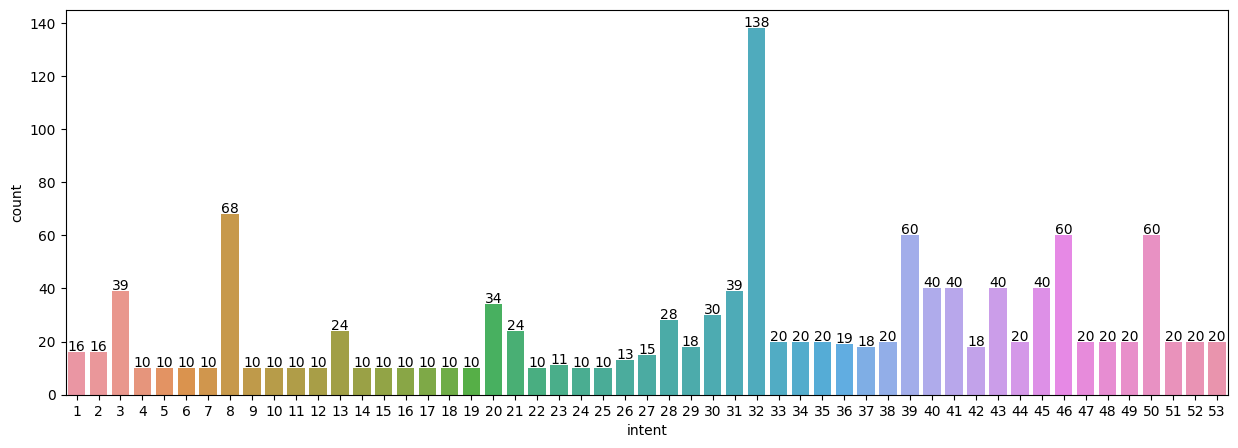
띄어쓰기나 '\n' 등과 같은 특수문자는 정규분포식으로 처리할 수 있었습니다.
import re
sentence = re.sub("[^가-힣0-9a-zA-Z\\s]", " ", sentence)
sentence = re.sub("\s+", " ", sentence)(2) 형태소 분석
형태소 분석에는 konlpy를 사용해보았습니다.
konlpy 내에는 mecab, Okt, komoran, Hannanum, Kkma 등 많은 토크나이저가 포함되어 있습니다.
from konlpy.tag import Okt, Komoran, Mecab, Hannanum, Kkma
tokenizer = Komoran()
tokenizer = Okt()
tokenizer = Mecab()
tokenizer = Hannanum()
tokenizer = Kkma()위와 같이 사용할 수 있습니다!
Okt를 활용해서 형태소를 분석하면 아래의 사진과 같이 형태소를 나눠 확인할 수 있습니다.

(3) 모델링
분석했던 문장 데이터들을 train과 test 데이터로 나누어 Word2Vec을 활용한 LightGBM 모델링을 시행했습니다.
학습데이터의 문장을 Word2Vec 모델을 사용하여 벡터화하면 아래와 같이 출력됩니다.

저는 모델링에 LightGBM모델과 RandomForest모델을 사용했는데 정확도는 각각 0.41, 0.4로 그렇게 큰 차이를 보이지는 않았습니다.
(4) 챗봇 생성
모델링 단계에서 학습한 모델을 가지고 함수를 만들어 챗봇을 생성해보았습니다.
학습 정확도가 낮은 편이라 대부분 올바르지 않은 응답을 했지만, 가끔 올바른 대답을 하는 경우를 발견하면 신기한 마음이 들었습니다!

- 2 : 이미지 딥러닝
6차 미프의 두번째 시간에는 "차량 공유업체의 차량 파손 여부 분류"를 주제로 프로젝트를 진행해보았습니다.
(1) 데이터 전처리
에이블스쿨에서 제공하는 데이터를 받아 정상 차량 사진과 파손 차량 사진을 각각 0과 1로 구분해주는 과정을 거쳤습니다. 이후 데이터를 train, val, test 데이터로 구분하고, 각각의 이미지를 조정한 후 array로 변환했어요!
resized_img = img.resize((280, 280))
img_array = img_to_array(resized_img)(2) 모델링
Conv2D, MaxPooling2D, Flatten, Dense 레이어들을 이용하여 파손 차량을 구분하는 모델을 설계해보았습니다.
model = keras.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(280, 280, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
...
위와 같은 형식으로 레이어들을 쌓아주고, Early Stopping도 적용해주었어요 :)
이후 평가 도구를 이용하여 평가를 진행하여 아래와 같이 결과를 확인할 수 있었습니다.
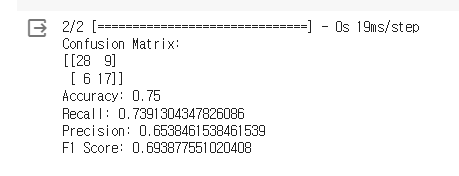
이외에도 Keras의 ImageDataGenerator을 이용해서 이미지 데이터의 수를 증가시키고, VGG16 모델을 사용해보는 등 다양한 모델을 적용하고 평가해보았습니다!
2. 에이블데이 1차
에이블데이에는 오전에 에이블러 전체가 AICE Associate 시험에 응시했습니다!
시험은 이제까지 배우고 활용해본 딥러닝 지식들을 활용해서 직접 코드를 작성하는 형식으로 진행되는데요! 생각이 나지 않고, 헷갈리는 부분이 있었더라도 인터넷 검색이 가능해서 잘 헤쳐나갈 수 있었습니다😆
점심시간을 가지고 KAIST 교수님께서 진행해주신 특강을 듣고, 코딩 마스터스 시상식과 빅프로젝트 사전 설명회를 가진 후에 각 반별 랜선 회식 시간을 가졌어요!
반별 랜석 회식 시간에는 서로가 첫인상을 적어두었던 패드를 기반으로 퀴즈를 진행하면서 한층 더 가까워지는 시간을 보냈습니다🎉
