
Subquery 🧸
- where절에서의 서브쿼리
이전에 배웠던 조인으로 만든 쿼리
select u.user_id, u.name, u.email from users u
inner join orders o on u.user_id=o.user_id
where o.payment_method='kakaopay'아래와 같이 서브쿼리를 이용해서도 같은 결과물을 볼 수 있다.
select user_id, name, email from users u
where user_id in(
select user_id from orders
where payment_method='kakaopay'
)- select에서의 서브쿼리
유저별 좋아요 갯수와 좋아요의 평균을 보고 싶은데 서브쿼리 없이는 user_id의 모든 코멘트에 대한 좋아요 갯수를 볼 수가 없다. 하나의 user_id에 코멘트가 여러개 있을 수도 있는데 모든 user_id가 한번씩만 나온다.
select user_id, likes, avg(likes) from checkins c
group by user_id checkin_id로 group by를 하면 유저 아이디당 좋아요 목록을 다 볼 수는 있지만 avg함수에 분모로 들어가는 게 groupby에서 쓴 checkin_id필드라서 user_id당평균은 볼 수 없다.
(checkin_id/comment비율은 1임)
select checkin_id ,user_id, likes, avg(likes) from checkins c
group by checkin_id
order by user_id 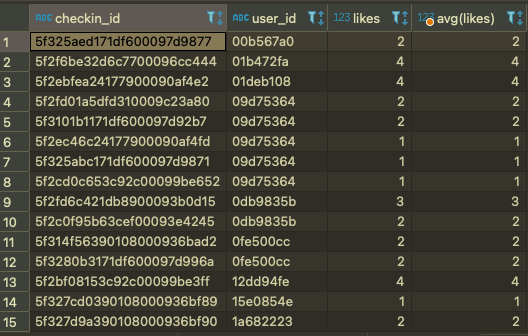
서브쿼리를 이용해서 모든 코멘트들당 like의 갯수와 user_id당 평균을 나타낼 수 있다.
select checkin_id ,user_id ,likes,
(select avg(likes) from checkins
where user_id=c.user_id )as avg_likes
from checkins c
order by user_id 
- from에서의 서브쿼리⭐⭐⭐
포인트를 많이 받은 사람들이 코멘트에 좋아요도 많이 달렸을까?
1. user_id 당 포인트를 구한다
select user_id, point from point_users pu
group by user_id - user_id 당 받은 좋아요 평균을 구한다
select user_id, round(avg(likes),1) as avg_likes from checkins c
group by user_id 3.두 테이블을 합친다 (원래 있던 테이블이 아니기때문에 from에 서브쿼리로 넣어주면 ok/ 새로 생성된? 이 테이블의 이름은 서브쿼리문 바로 뒤에 붙여준다(a))
그리고 꼭! 서브쿼리 바깥에 있는 필드들은 출처를 밝혀줘야한다!!
select pu.user_id, pu.point from point_users pu
inner join (select user_id, round(avg(likes),1) as avg_likes from checkins c
group by user_id ) a on pu.user_id =a.user_id예제>
- 포인트가 평균보다 많은 유저 아이디 구하기
select pu.user_id, pu.point from point_users pu
where point> (select avg(point) from point_users)
group by pu.user_id 처음에 실수한 부분은 서브 쿼리에 group by user_id 를 넣은 건데, 이렇게 되면 전체 평균이 아니라 유저아이디 당 평균이 나오고 그렇게 되면 서브쿼리가 한줄 이상이 돼서 오류가 난다.
당연하지만 아래처럼 포인트 말고 다른 칼럼(필드)이 있으면 오류가 난다
select pu.user_id, pu.point from point_users pu
where point> (select avg(point), point_user_id from point_users)
group by pu.user_id 2.이씨성을 가진 유저들의 평균 포인트보다 더 많은 포인트를 가지고 있는 유저 데이터를 추출하기 (이씨성을 가진 유저들의 평균 포인트보다 더 포인트가 많은 유저데이터를)
select pu.user_id, pu.point from point_users pu
where point>(
select avg(pu2.point) from users u
inner join point_users pu2 on u.user_id =pu2.user_id
where u.name like '이%'
)
group by pu.user_id 또는
select * from point_users pu
where point > (
select avg(point) from point_users pu2
where pu2.user_id in (select * from users where name like '이%')
)❗pu나 pu2나 똑같은 테이블이라 굳이 별칭이 따로 있을 필요는 없는듯하다
❗서브 쿼리 안에 있는 서브쿼리에서 select * ➡ user_id로 바꿔줘야한다.
user_id끼리 비교하는 거라서 한쪽이 전체가 되어버리면 안 되는 듯하다.
수정 ➡
select pu.user_id, pu.point from point_users pu
where point > (
select avg(point) from point_users pu2
where user_id in (select user_id from users where name like '이%')
)- checkins 테이블에 course_id별 평균 like수 테이블을 붙여보기
내가한거(from에서 사용)
select c.user_id , c.course_id , c.likes, a.avg_likes from checkins c
inner join (select course_id, round(avg(likes),1) as avg_likes from checkins
group by course_id ) a on c.course_id = a.course_id
정답안(select에서 사용) ⭐⭐⭐⭐
select c.checkin_id,
c.course_id,
c.user_id,
c.likes,
(
select avg(likes) from checkins
where course_id = c.course_id
)
from checkins c 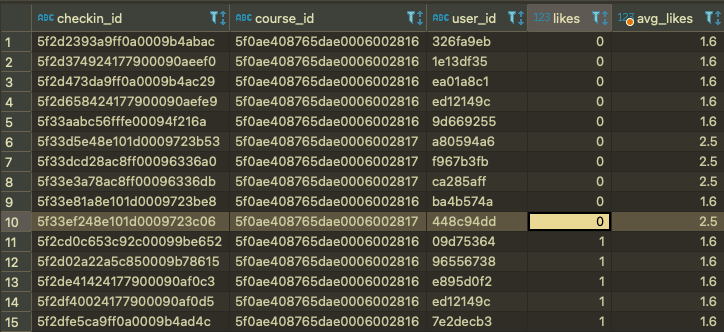
❓select에서 쓸땐 같은 테이블의 결과값만 쓸 수 있는건가??
- 위의 테이블에서 course_id를 title로 변경하기
select c.checkin_id,
c1.title,
c.user_id,
c.likes,
(
select round(avg(likes),1) from checkins
where course_id = c.course_id
) as avg_likes
from checkins c
inner join courses c1 on c.course_id =c1.course_id tip! select ... ,c.* c가 별칭인 테이블에서 모두 보여준다
- 1)course_id 별 체크인 갯수에 course_id별 총 인원 수 구하기
(from 절에서 서브쿼리 사용)
-내가 쓴 답안
select c.course_id,count(distinct(c.user_id))as cnt_checkins ,a.cnt as cnt_total from checkins c
inner join (select course_id, count(user_id) as cnt from orders o group by course_id) a on c.course_id =a.course_id
group by c.course_id왜인지 이거 하는데 완전히 까먹고 이상한 짓 하고 있었음.. 우영우때매 맘이 급해져서..
-정답안.. 뭔가 확실히 깔끔..
select a.course_id, b.cnt_checkins, a.cnt_total from
(
select course_id, count(*) as cnt_total from orders
group by course_id
) a
inner join (
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_id
) b
on a.course_id = b.course_id각각의 테이블을 하나의 새로운 테이블로.. 치고 .. 그룹바이도 안에서 다 해서 나와서 밖에서 해줄 필요가 없나보다.. 역쉬나 다름 ^^ㅜ
operand는 피연산함수
2)과목별 비율과 course_id 대신 title 사용하기
select a.course_title ,count(distinct(c.user_id))as cnt_checkins ,a.cnt as cnt_total, count(distinct(c.user_id))/a.cnt as ratio
from checkins c
inner join (select course_id, course_title, count(user_id) as cnt from orders o group by course_id)
a on c.course_id =a.course_id
group by c.course_id답안에서는 courses 테이블이랑 조인을 한번 더 해서 title을 이용해줌
select c.title,
a.cnt_checkins,
b.cnt_total,
(a.cnt_checkins/b.cnt_total) as ratio
from
(
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_id
) a
inner join
(
select course_id, count(*) as cnt_total from orders
group by course_id
) b on a.course_id = b.course_id
inner join courses c on a.course_id = c.course_idwith절
쿼리 맨위! 에 table을 정의해주고 해당 테이블이 필요한 곳에 테이블 이름을 사용해주면됨 훨씬 보기가 깔끔하다
with table1 as (select course_id, course_title, count(user_id) as cnt from orders o group by course_id)
select a.course_title ,count(distinct(c.user_id))as cnt_checkins ,a.cnt as cnt_total, count(distinct(c.user_id))/a.cnt as ratio from checkins c
inner join table1 a on c.course_id =a.course_id
group by c.course_id문자열 쪼개기
- substring_index(필드명, 쪼개는 기준, 1앞에꺼 또는 -1뒤에꺼)
select user_id, substring_index(email,'@',1) from users u - substring(필드명, 시작점, 시작점부터 몇자)
select order_no ,substring(created_at,1,10) from orders o 원하는 값 출력하기
- case
case when~이런 조건일 때 then~ 이렇게 하고
(when~then 여러번 가능)
else~ 아니면 이렇게 끝 end
select pu.user_id, pu.point,
case when pu.point> 10000 then '잘하고 있어요'
else '조금만 더 힘내세요'end
from point_users pu ❗case도 필드명이니까 다른 필드 옆에 사용할 때는 , 꼭!! 쓰기
- case when을 사용해서 통계내기
케이스문을 with로 테이블로 만들어서 통계내는데 사용할 수 있다.
with table1 as(
select case when point> 10000 then '1만이상'
when point> 5000 then '5천이상'
else '5천미만'end as level
from point_users pu)
select a.level, count(*) as cnt from table1 a
group by a.level❗위드 쿼리랑 테이블 사용하는 select 문 떨어져있으면 당연히 실행한됨
블럭해서 실행해주든지 아니면 붙여써야함
QUIZ 🔥
- 평균을 구해서 평균보다 높으면/낮으면 특정 문자 출력
select point_user_id , point,
case when point>=(select avg(point) from point_users ) then '잘하고 있군'
else '열심히 합시다'end as msg
from point_users pu 2.이메일 도메인별 갯수 세기
내가한거 서브쿼리 없음select SUBSTRING_INDEX(email,'@',-1) as domain, count(*) as cnt from users u
group by domain서브쿼리 있는 정답select domain, count(*) as cnt from
(
select SUBSTRING_INDEX(email,'@',-1) as domain
from users u
) a
group by domain카운트를 서브쿼리 안에서 해버리고 그 안에 그룹바이가 없으면 row 가 한줄밖에 안나옴 그룹바이를 안해주면 대표로 하나밖에 안나온다는 거슬 꼭 기억해랏
3.생략
4.
with table1 as
(select enrolled_id, count(*) as cnt from enrolleds_detail ed
where done=1
group by enrolled_id ),
table2 as(
select enrolled_id, count(*) as cnt2 from enrolleds_detail ed
group by enrolled_id
)
select a.enrolled_id, a.cnt as done_cnt, b.cnt2 as total_cnt , a.cnt/b.cnt2 as ratio from table1 a
inner join table2 b on a.enrolled_id=b.enrolled_id삽삽삽가능😎
근데... 엄청 쉽게도 가능한거였음
done=1또는 0이므로 done을 모두 합한게 done=1인 것의 갯수를 세면 되는 일이었음... 경악😱
select enrolled_id,
sum(done) as done_cnt,
count(*) as tot_cnt,
round(sum(done)/count(*),1) as ratio
from enrolleds_detail ed
group by enrolled_id4주차 숙제 🗒
