DB 설계하기
설계라고 하기도 뭐한데, 한번 해보자!
현재 노션 클론에 존재하는 DB관련 기능은 다음과 같다.
- 유저는 게시글을 작성할 수 있다. 생성된 게시글은 부모 게시글 하위에 추가된다. 만약 부모 글이 존재하지 않으면, 최상단(root)에 생성된다.
- 유저는 기존 글을 삭제할 수 있다. 삭제된 게시글의 자식 게시글은 삭제된 게시글의 계층으로 올라온다.
- 게시글은 제목, 내용, 작성 시각, 업데이트시각을 가진다.
- 게시글은 수정이 가능하다.
이러한 내용을 바탕으로 테이블을 작성해보자.
Post 테이블
- post_id 아이디(primary key)
- parent_id 부모 게시글 아이디(foreigner key, null이 올 수도 있음)
- title 제목
- content 내용
- created_at 작성시각
- updated_at 업데이트 시각
처음 생각한 테이블은 이렇다. 부모 게시글을 외래키로 참조하고, 나머지 속성은 고만고만함.
이렇게 두고 하면 되겠거니 했는데...
현재 테이블의 문제점
기존 데이터구조를 살펴보자.
id:number,
title:string,
documents:array,
createAt:string,
updatedAt:string내가 짠 테이블과 사뭇 다르다. 특히 documents에는 하위 게시글들의 데이터가 모조리 들어가있다.
이는 노션 클론의 핵심 기능인 트리 구조때문이다.
만약 parent_id를 이용해서 트리구조를 만드려면, 재귀적으로 쿼리를 진행해야한다. 따라서 한 번 쿼리할때마다 소요되는 시간이 늘어난다.
기존 데이터구조는 모든 하위 게시글을 저장하기에 쿼리할때마다 소요되는 시간이 아주 적다. 그러나 용량의 손해를 많이 본다.
즉, 시간복잡도와 공간복잡도의 trade-off라고 할 수 있다.
이처럼 관계형 데이터베이스에서는 계층적 구조를 표현하기가 어렵다고 한다. 하지만 표현하지 못하는 건 아니다.
관계형 데이터베이스에서 트리구조 표현하기
- Adjacency List : 첫번째로 떠올린
parent_id처럼 부모의 키를 갖는 방식. 그래프의 인접리스트 방식과 유사하다. - Closure table : 모든 엔티티간의 관계를 갖고있다. 아래에서 설명!
클로져테이블은 총 두개의 테이블을 가진다.
기존 테이블(parent_id 제외)과 노드간의 계층구조를 나타내는 테이블 두개.
| 부모id | 자식id | 깊이(계층깊이) |
|---|---|---|
| 1 | 1 | 0 |
| 1 | 2 | 1 |
| 1 | 3 | 2 |
| 1 | 4 | 2 |
| 1 | 5 | 1 |
| 2 | 2 | 0 |
| 2 | 3 | 1 |
이렇게 각 노드의 계층구조를 알고있으면, 특정 게시글의 부모,자식 게시글에 접근하기가 수월해진다.
관계형 데이터베이스에서 트리구조를 이렇게 표현했는데, NoSQL에서는 어떻게 표현할까?
NoSQL에서 트리구조 표현하기
NoSQL에도 여러 방식이 있다. 개중 관계형 데이터베이스의 방식과 똑 닮은 방식들도 존재한다.
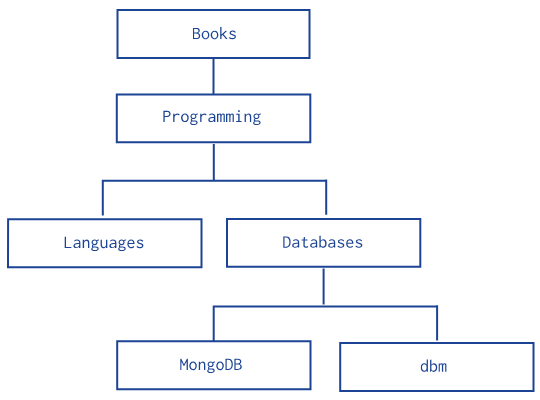
위와같은 데이터구조가 존재한다고 가정해보자.
db.categories.insertMany( [
{ _id: "MongoDB", parent: "Databases" },
{ _id: "dbm", parent: "Databases" },
{ _id: "Databases", parent: "Programming" },
{ _id: "Languages", parent: "Programming" },
{ _id: "Programming", parent: "Books" },
{ _id: "Books", parent: null }
] )위처럼 parent의 참조를 추가하면 상위참조
db.categories.insertMany( [
{ _id: "MongoDB", children: [] },
{ _id: "dbm", children: [] },
{ _id: "Databases", children: [ "MongoDB", "dbm" ] },
{ _id: "Languages", children: [] },
{ _id: "Programming", children: [ "Databases", "Languages" ] },
{ _id: "Books", children: [ "Programming" ] }
] )위처럼 children의 참조를 추가하면 하위참조
db.categories.insertMany( [
{ _id: "MongoDB", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" },
{ _id: "dbm", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" },
{ _id: "Databases", ancestors: [ "Books", "Programming" ], parent: "Programming" },
{ _id: "Languages", ancestors: [ "Books", "Programming" ], parent: "Programming" },
{ _id: "Programming", ancestors: [ "Books" ], parent: "Books" },
{ _id: "Books", ancestors: [ ], parent: null }
] )이렇게 ancestors, parent참조를 추가하면 조상배열과 상위참조
db.categories.insertMany( [
{ _id: "Books", path: null },
{ _id: "Programming", path: ",Books," },
{ _id: "Databases", path: ",Books,Programming," },
{ _id: "Languages", path: ",Books,Programming," },
{ _id: "MongoDB", path: ",Books,Programming,Databases," },
{ _id: "dbm", path: ",Books,Programming,Databases," }
] )자세한 경로를 나타내면 Materialized Paths(구체화된 경로)
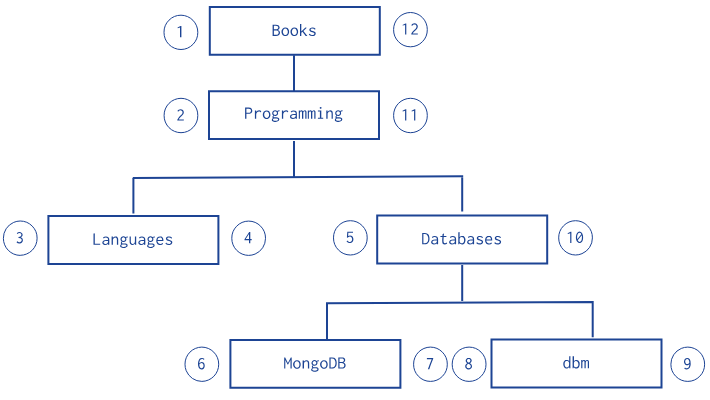
db.categories.insertMany( [
{ _id: "Books", parent: 0, left: 1, right: 12 },
{ _id: "Programming", parent: "Books", left: 2, right: 11 },
{ _id: "Languages", parent: "Programming", left: 3, right: 4 },
{ _id: "Databases", parent: "Programming", left: 5, right: 10 },
{ _id: "MongoDB", parent: "Databases", left: 6, right: 7 },
{ _id: "dbm", parent: "Databases", left: 8, right: 9 }
] )위처럼 트리를 왕복순회시 정지포인트로 식별하면, 중첩 세트
각 구조마다 trade-off가 항상 존재하기에, 적절한 구조를 사용하는 게 좋다.
NoSQL 트리구조 코드와 이미지 출처는 : https://www.mongodb.com/ko-kr/docs/manual/applications/data-models-tree-structures/
결론은...
현재 클라이언트 코드에서 documents를 받으므로, NoSQL을 이용하여 하위참조구조를 사용할 것이다. 단, parent에 대한 id 참조는 고민할 필요가 있따.
왜냐면 경로탐색의 용이성 때문이다. 현재 클라이언트에서 아래 사진과같은 BreadCrumb구조를 나타내려면, 재귀적인 접근이 필요하다.
const getSelectedDocumentPath = (documents, currentId) => {
const temp = [];
const getPath = (document, parent) => {
if (currentId === document.id) {
temp.push(...parent);
return;
}
if (document?.documents?.length) {
document.documents.forEach((doc) => getPath(doc, [...parent, document]));
}
};
documents.forEach((doc) => getPath(doc, []));
return temp;
};이는 굉장히 비효율적이다. parent_id만 있다면, 클라이언트측에서 O(1)의 접근으로 가능하다.
서버측에서도 한 번 생각해보자.
{
"id": 1,
"title": "Root Folder",
"parentId": null,
"documents": [
{
"id": 2,
"title": "Sub Folder 1",
"parentId": 1,
"documents": [
{
"id":4,
"title":"hi",
"parentId":2,
"documents":[],
},
],
},
{
"id": 3,
"title": "Sub Folder 2",
"parentId": 1,
"documents": []
}
]
}위와 같은 데이터 구조가 있다고 가정했을때, id가 2인 문서를 삭제해보자.
const documentToDelete = db.documents.findOne({ _id: req.body.id }); // 대충 req.body.id에 삭제될 문서의 아이디가 들어온다고 가정
const parentIdOfDeletedDocument = documentToDelete.parentId;
db.documents.updateMany(
{ parentId: req.body.id }, //삭제될 문서를 부모로 갖고있는 자식문서들을 찾는다.
{ $set: { parentId: parentIdOfDeletedDocument } } // 자식 문서들의 parentId를 삭제될 문서의 parentId로 변경
);
db.documents.deleteOne({ _id: req.body.id }); //삭제해부럿updateMany()는 인덱스가 있다면 키-밸류접근으로 O(1)에 접근가능하겠지만, 자식문서를 docuemnts에 넣어둠으로 사실상 전체를 탐색해야 원하는 결과를 얻을수 있을 것이다.
그렇다면 정규화는? 정규화를 진행하면 공간복잡도가 증가하고, 데이터를 반환받을때 여러번 쿼리를 거쳐야할 것이다.
=> 간단함을 위하여 현재 데이터 구조 그대로 사용하겠다.
아직 DB에 대해 자세히 알지못해 확실한 결론을 내리기가 어렵다. 그래도 할 수 있는만큼 각 구조의 장단점을 보고 선택하는 게 중요하지 않을까 싶다!
