Allocation of File Data in Disk
우리가 메모리를 어떻게 할당할 것인지 정하던 dynamic memory allocation처럼 file data도 디스크에 어떻게 할당할 것인지 정해야한다. 이를 대표하는 방법 세가지를 소개하겠다.
참고로 디스크는 동일한 크기의 Block 단위로 나눠서 관리한다. 마치 paging기법과 유사하다.
Contiguous Allocation(연속 할당)
이름이 같으니, 방식도 유사하다. 메모리 연속할당을 디스로 바꾼 것이다.
시작 위치와 길이를 정하고, 데이터를 디스크에 할당한다

단점
- 외부 단편화(external fragmentation)을 발생시킨다.
- 파일 크기의 수정에 용이하지 않다.
- 수정을 대비해서 공간을 크게 할당해놓으면 당연히 내부 단편화를 발생시킨다.
장점
- I/O 속도가 굉장히 빠르다.
- 한번의 seek(플래터 회전)으로 많은 데이터를 가져올 수 있다. 그렇기에 process의 swapping에 많이 사용한다.
- direct access(직접 접근)이 가능하다.(start와 length 정보가 있음)
Linked Allocation
이름답게 LinkedList처럼 파일을 구현해놨다. 데이터가 분산되어있으니, Noncontiguous allocation이라 해도 되겠지.
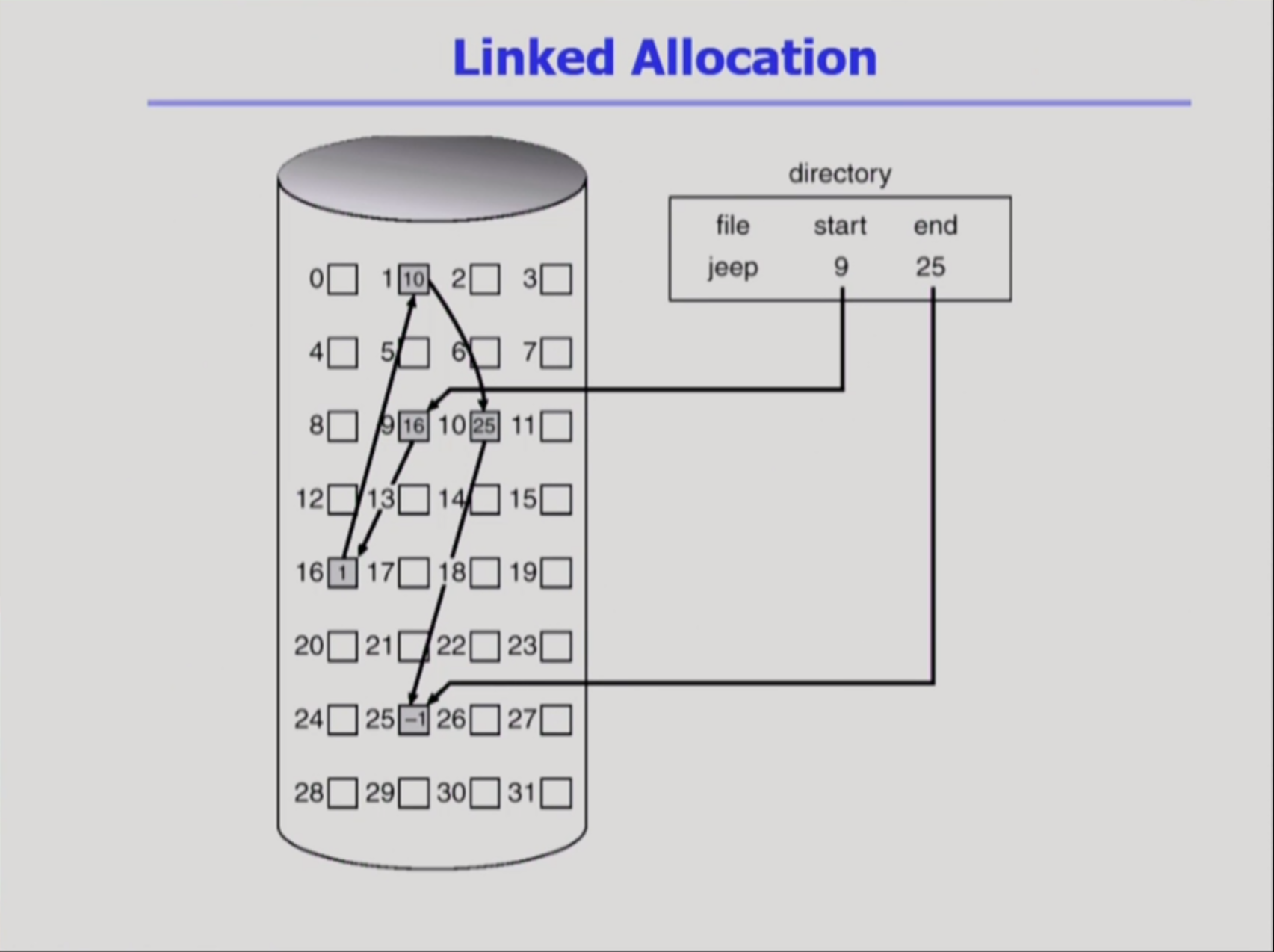
단점
- direct access불가능. 순차적으로 포인터를 갖고있기에, 당연히 불가능
- sector하나가 고장나면(bad sector), 이후의 데이터는 유실됨(포인터 때문)
- sector는 512bytes의 배수로 구성되는데, pointer(4bytes)도 보관해야해서 512짜리가 들어오면, 두 섹터나 차지하게 됨(공간낭비)
=> 이걸 해결한 방식이 FAT 방식이다. pointer를 위한 공간을 따로 마련한다.
포맷할때 주로 봤던 녀석이군.
장점
- 외부 단편화 발생x
장점보다 단점이 많구먼...?
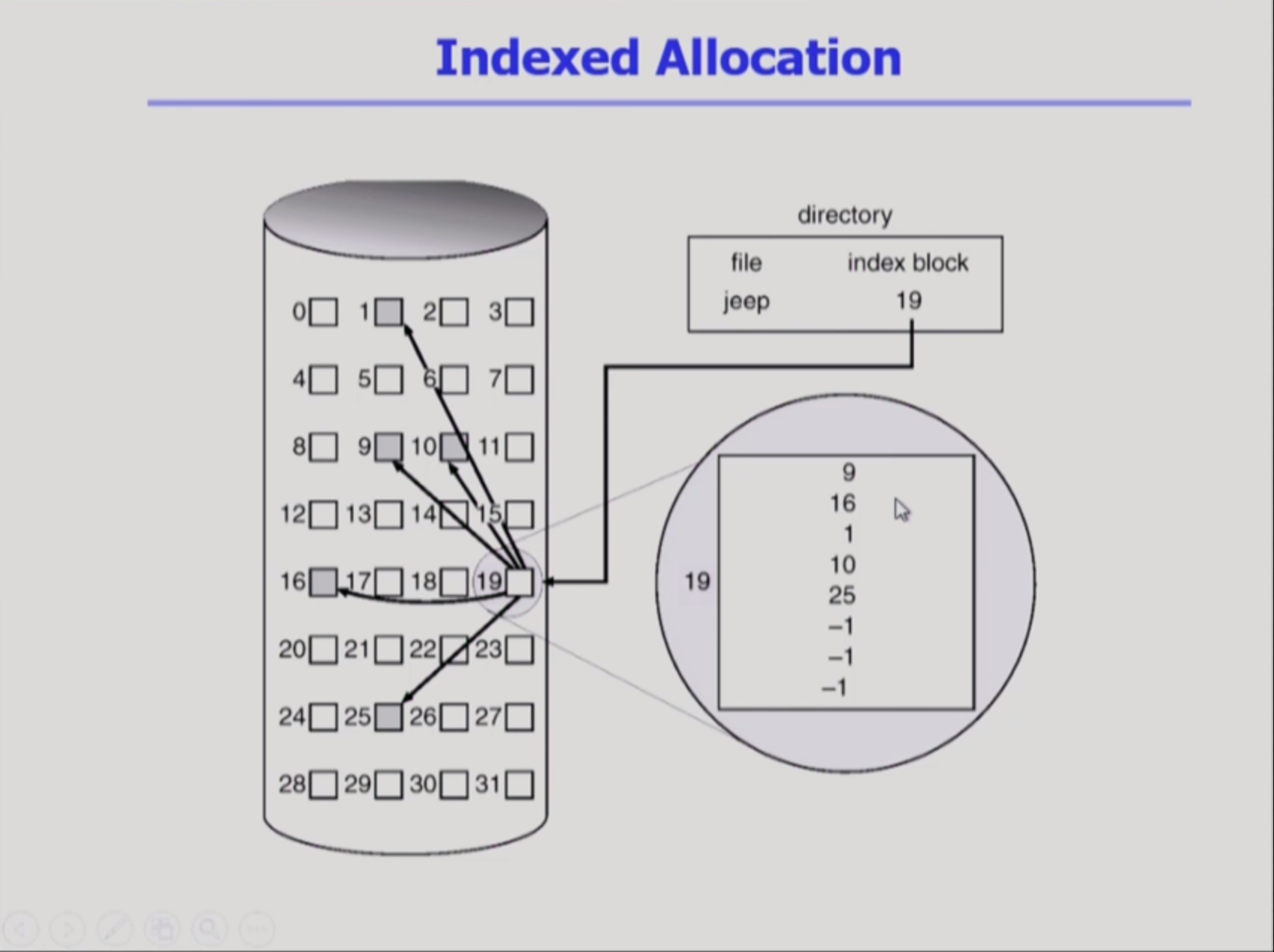
Indexed Allocation
이 녀석 역시 이름답게 한 sector에 array를 생성해 자신의 데이터가 어디 sector에 있는지 index를 표시해 놓는 것이다.
단점
- 파일 크기가 아무리 작아도, index 섹터 하나, 파일 섹터 하나가 필요하다. (공간낭비)
- 하나의 index sector로 굉장히 큰 파일을 표현할 수 없다.
=> **linkedScheme(마지막 인덱스가 또다른 index block을 가리킴)이나 multilevel-index(인덱스가 다른 인덱스를 가리킴)를 사용하면 된다.
장점
- direct access가 가능하다
- 단편화가 발생하지 않는다!(아주 좋은데?)
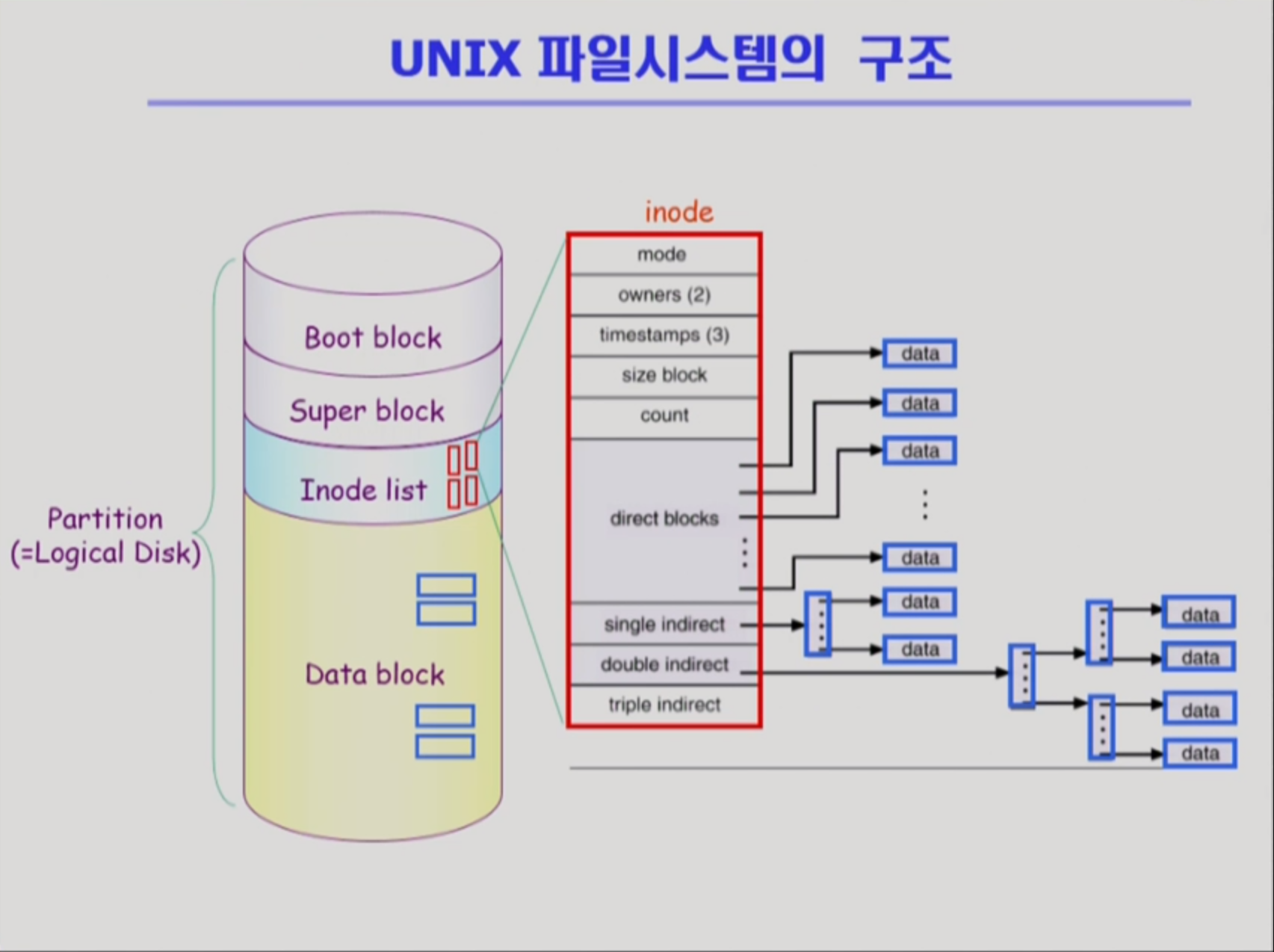
파일 시스템 구조
UNIX
directory file이 meatadata를 갖고 있다 설명하였지만, 모든 metadata를 갖고있는 건아니다. UNIX 시스템에선 I(index)node list라는 친구도 metadata(파일 이름을 제외한 모든 메타데이터)를 갖고있음.
파일 하나당 inode list를 하나씩 할당받는다.
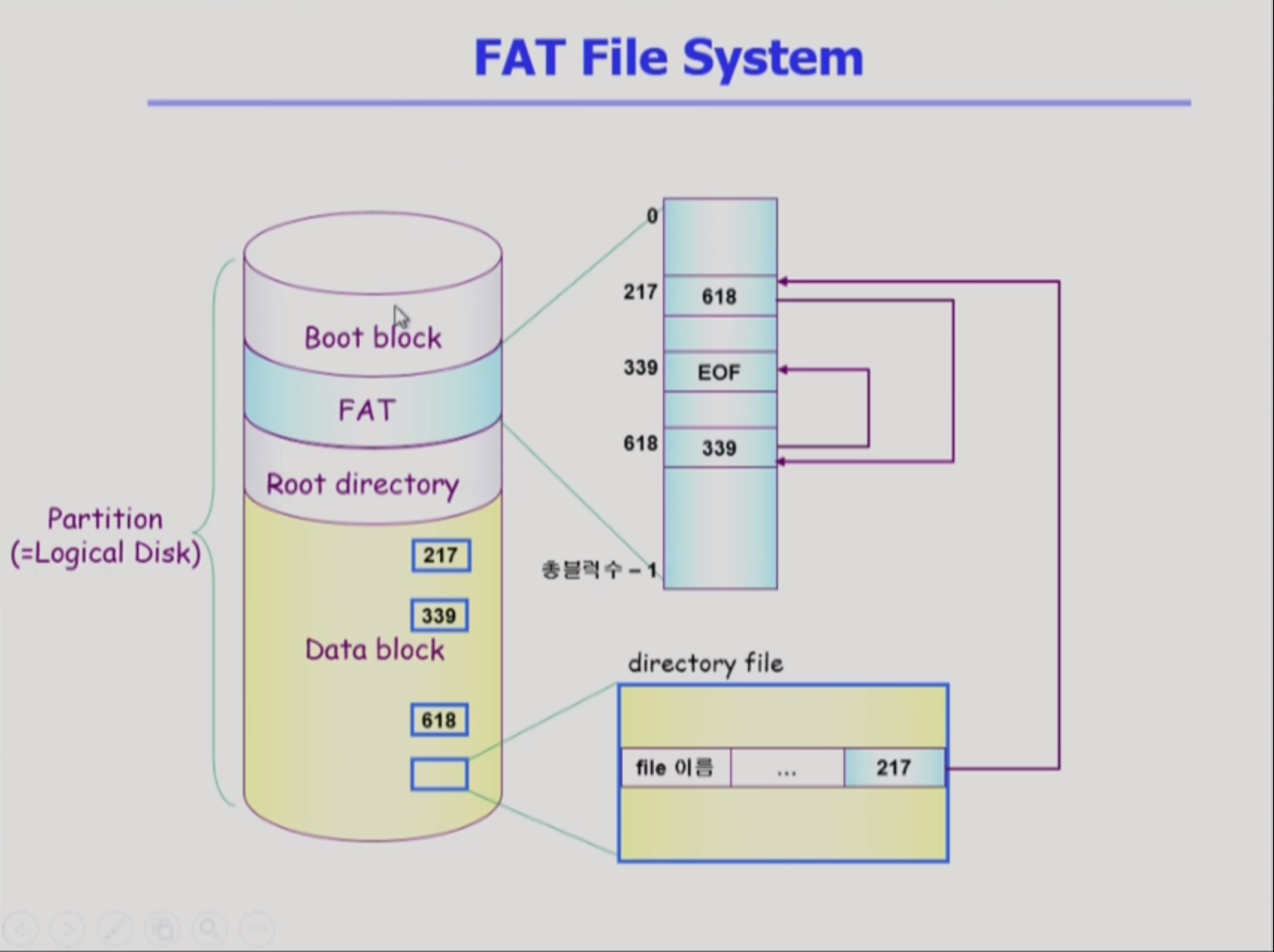
FAT
FAT 시스템은 FAT블럭이 파일의 번호만 갖고있음. 나머지 meatadata는 directory가 소유. Linked Allocation방식에서 설명했던 pointer를 따로 가진 공간이 FAT임
FAT은 Linked Allocation의 단점을 모조리 해결한 방식이다!
Free-Space(빈공간 관리)
디스크에 데이터가 꽉 차있는 경우도 있겠지만, 빈공간은 존재하기 마련이다. 지금까지 배운건 Data를 어떻게 할당하는지 였고, 이번엔 빈공간을 어떻게 관리하는지에 대해 알아보자.
Bit map(Bit vector)
부가적인 공간을 할당해서 block이 비어있는지는 0과 1로 관리한다.
예를들어 block이 256개라면, 표현해야 하는 경우의 수는 2^8. 따라서 8bit이 필요하다
이는 연속적인 n개의 빈공간을 찾는 데 효율적이다. (디스크의 seek가 필요없음)
...나머지

Directory 구현
구현 방식에는 여러가지가 있다.
- linear list : 걍 배열같은거. 구현 간단하고, 탐색할때 O(n)걸림
- hash table : 해쉬테이블. 탐색시간 O(1). 다만 collsion(충돌)발생 가능
=> collsion은 해쉬 함수를 거칠때, 중복된 키 값이 나올 수있다.
아래의 것들도 고려해야 함.
- directory 말고도 meatadata를 분산보관.
- long filename의 지원. 너무 길면 포인터를 둬서 빈공간에 저장함

VFS, NFS
파일 시스템은 파일을 관리하는 환경이다. 파일 시스템은 다를 수 있는데, 이를 하나하나 접근하긴 어려우니 OS단에서 통합지원을 해줌.
- VFS : 위에서 설명한 것
- NFS : VFS를 이용해 분산환경에서 파일시스템을 관리

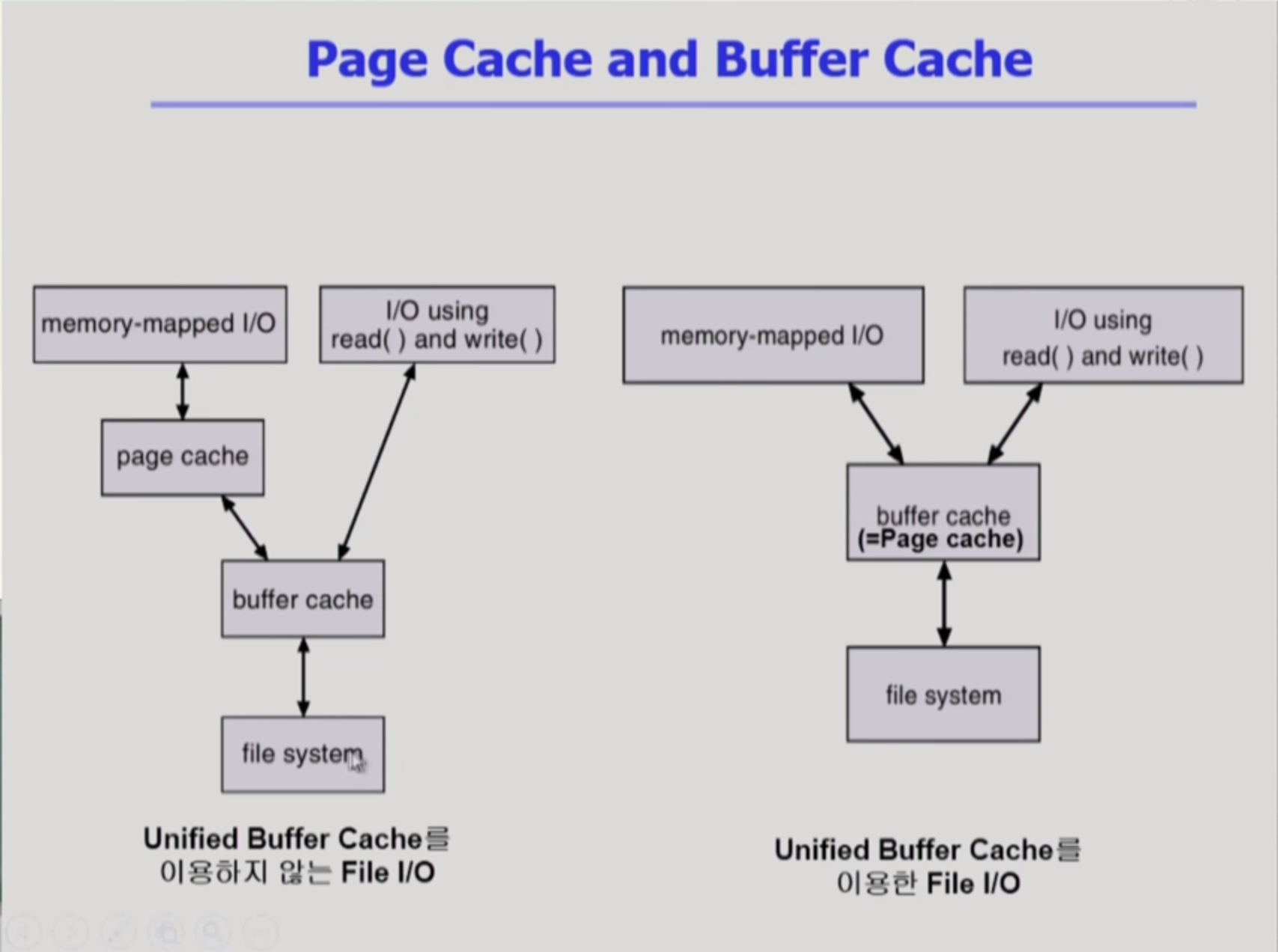
Page Cache, Buffer Cache
- page cache : page는 기본 4kb단위. 따라서 1kb만 쓰려해도, 4kb를 다 가져와야함. 그래서 메모리에 잠깐 적재해두는게 page cache. 접근도 빠르니
- buffer cache : 디스크 block정보를 캐싱하는것. 이 역시 locality를 활용해 캐싱함
- Memory Mapped I/o : file 일부를 page단위로 virtual memory에 매핑. I/O작업량이 줄어들어, 시스템콜 안써도됨 => 속도 향상

현재의 운영체제는 Buffer cache 와 page Cache를 통합했기에, buffer cache크기도 (page)4kb로 쓴닷
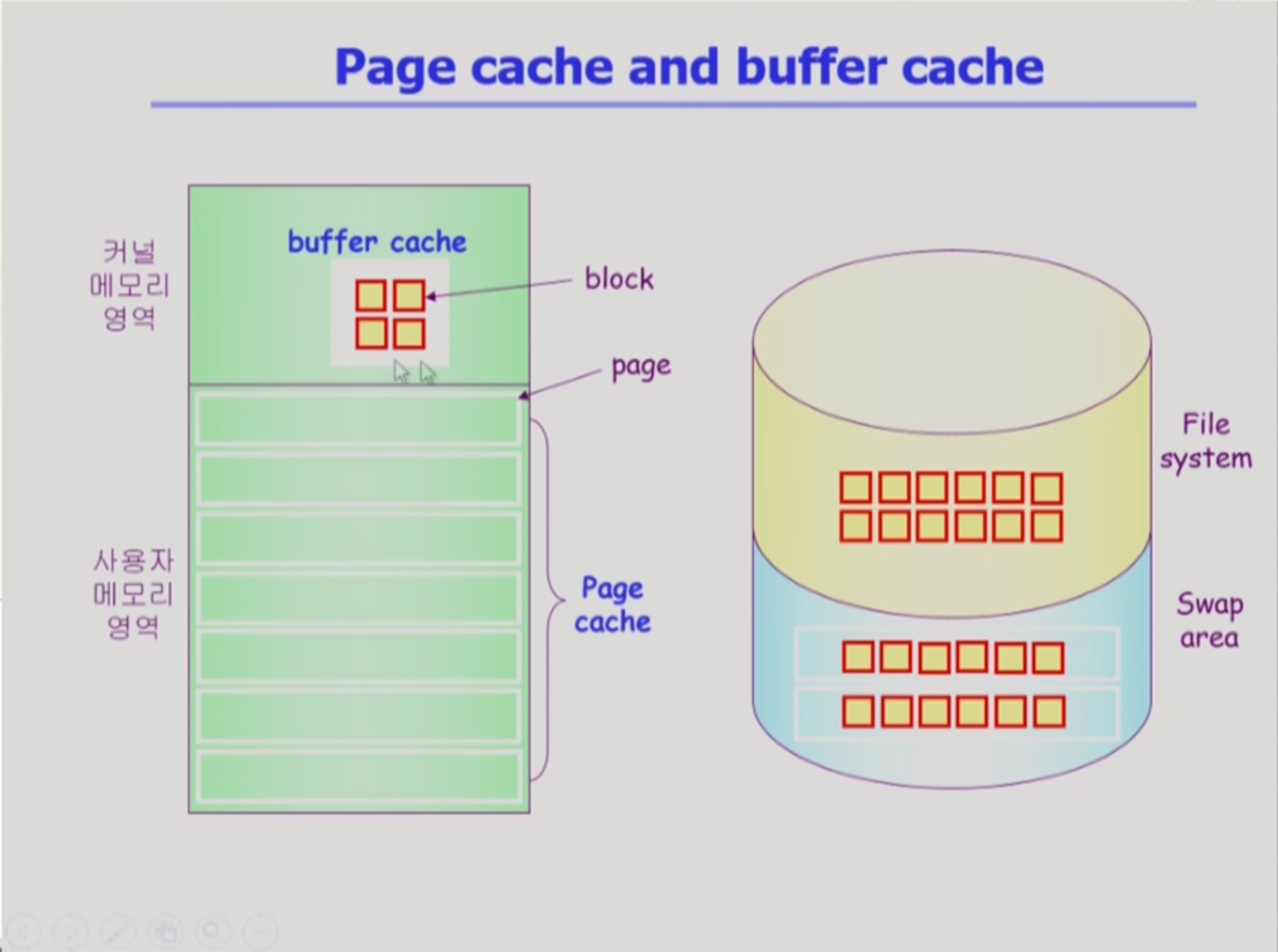
unified Buffer cache vs not
page cache와 buffer cache가 통합되었기에, 한번의 단계가 절약됨