데이터베이스 시스템
이전 챕터에서는 데이터베이스 관리 시스템(DBMS)에 대해 배웠다.
이번 챕터에서는 데이터베이스를 총망라하는 데이터베이스 시스템에 대해 배워보겠다.
데이터베이스 시스템(DBS)란?
데이터베이스에 데이터를 저장하고, 이를 관리하여 조직에 필요한 정보를 생성해주는 시스템이다.
즉 사용자가 어떠한 데이터 언어를 이용해서 데이터베이스에 접근할때, 데이터베이스 관리 시스템을 이용한다.
이러한 데이터베이스, 하드웨어, 사용자, 애플리케이션 등을 포함한 전체 시스템을 데이터베이스 시스템이라고 한다.
데이터베이스의 구조
데이터베이스의 구조는 크게 두가지로 나뉜다.
- 스키마(schema) : 데이터베이스에 저장되는 데이터 구조와 제약 조건을 정의한 것.
예를들어 고객정보를 데이터베이스에 저장할때 유효성 검사를 진행하는 것도 역시 스키마에 부합한지 판단하는 것이다. - 인스턴스(instance) : 스키마에 따라 데이터베이스에 실제로 저장된 값을 의미한다.
즉 스키마는 틀이고, 인스턴스가 실제로 저장된 데이터를 의미한다.
이러한 데이터베이스의 구조를 미국 표준화 기관에서 3단계로 나누었다.
- 외부단계(external level) : 개별 사용자 관점
- 개념 단계(conceptual level) : 조직 전체의 관점
- 내부 단계(internal level) : 물리적인 저장 장치의 관점
각 단계별로 다른 추상화를 제공해야한다. 내부 => 외부로 갈수록 추상화 레벨이 높아진다.
이 또한 바로 와닿지 않는다. 예를 들어 직원 관리 시스템이 존재한다고 가정해보자.
외부 단계
HR팀은 인사정보를 볼 수 있지만, 급여 정보는 볼 수 없다. 반대로 회계팀은 급여정보를 볼 수 있으나 인사정보는 볼 수 없다.
즉, 개별 사용자 관점에서 데이터베이스를 어떻게 구조화 할지 생각한다.
이때 사용자에게 필요한 데이터베이스를 정의한 것을 외부 스키마(external schema)라고 한다.
다양한 사용자들이 존재하기에 외부스키마는 다수존재할 수 있다.
개념 단계
이번엔 조직 전체 관점에서 살펴보자. 직원테이블과 부서테이블을 정의하고 이들이 어떻게 연결되는지를 설정해야한다.
이때 적용된 구조는 조직 전체(모든 사용자)에게 공통적으로 적용된다.
이때 조직 과관점에서 데이터베이스의 구조를 정의한 것을 개념 스키마(conceptual schema)라고 한다.
조직은 하나기에, 개념스키마는 오직 하나만 존재한다.
내부 단계
물리적인 저장 장치의 관점에서 살펴보자. 위에서 정의된 데이터를 어떤 디스크에 저장하고 어떻게 저장할 지 생각한다.
또한 접근 방식에 따라 데이터의인덱스를 설정할 수 있다.
이때 데이터베이스가 저장 장치에 실제로 저장되는 방법을 정의한 것을 내부 스키마(internal schema)라고 한다.
내부스키마 또한 오직 하나만 존재한다.
이렇게 3단계구조로 데이터베이스를 나누고, 스키마또한 단계별로 유지하는 이유는 결국 데이터의 독립성을 실현하기 위해서다.
=> 코딩할때 서로 종속성을 최대한 걷어내서 변경이 존재할 시 side effect를 최대한 줄이는 방법과 유사한듯하다
데이터 사전(data dictionary)
데이터베이스에 대한 전반적인 정보를 제공한다. 구조를 정하기 위한 스키마, 제약조건, 권한 등을 포함한다.
데이터 언어
사용자와 데이터베이스 관리 시스템간의 통신 수단이다.
사용 목적에따라 정의어, 조작어, 제어어로 구분한다.
- 데이터 정의어(DDL) : 스키마를 정의-수정-삭제하기위해 사용
- 데이터 조작어(DML) : 데이터의 삽입-삭제-수정-검색등을 위해 사용
절차적 데이터 조작어, 비절차적 데이터 조작어로 구분되기도 한다.
=> 절차적 데이터 조작어는 데이터를 얻기위해 어떻게처리해야하는지도 기술하고, 비절차적 데이터 조작어는 어떤데이터를 원하는지만 설명하면 된다. 즉, 선언적 데이터 조작어라고 볼 수 있다. - 데이터 제어어(DCL) : 내부적으로 필요한 규칙이나 기법을 정의하기 위해 사용
대표적인 데이터 언어로는 SQL이 있다!
데이터베이스 관리 시스템의 구성
데이터베이스 관리시스템은 크게 두가지로 구성된다.
- 질의 처리기(query processor) : 사용자의 데이터 처리요구를 해석하여 처리한다.
=> 쿼리요청이 들어왔을때 해석하고 처리해준다. - 저장 데이터 관리자(stored data manager) : 디스크에 저장된 사용자 데이터베이스와 데이터 사전을 관리하고 접근하는 역할을 담당한다.
=> 실제로 DB에 저장하는 과정을 진행한다.
데이터 모델링
데이터베이스의 구조를 설계할땐 스키마를 이용한다.
이를 이용하여 어떻게 설계하는지 한 번 알아보자!
데이터베이스 설계
데이터베이스의 목적은 결국 데이터를 저장하여 사용자에게 정보를 제공하기 위함이다.
따라서 사용자의 다양한 요구를 고려하여 데이터베이스를 설계해야한다.
이때 설계 과정을 5단계로 나눔으로써 설계 도중 오류 발견시, 이전단계로 돌아가 설계를 변경할 수 있게 한다.
1) 요구 사항 분석
데이터베이스의 용도를 파악하여 요구 사항 명세서를 작성한다.
2) 개념적 설계
DBMS에 독립적인 개념적 구조를 설계하여 개념적 스키마(E-R 다이어그램)를 작성한다.
3) 논리적 설계
DBMS에 적합한 논리적 구조를 설계하여 논리적 스키마(릴레이션 스키마)를 작성한다.
4) 물리적 설계
DBMS로 구현 가능한 물리적 구조를 설계하여 물리적 스키마를 작성한다.
5) 구현
SQL문을 작성한 후 이를 DBMS에서 실행하여 데이터베이스를 생성한다.
모든 과정이 중요하지만, 특히 1~3단계 설계가 핵심이므로 잘 숙지해두자.
데이터 모델링이란?
데이터모델링이란 현실 세계에 존재하는 데이터를 컴퓨터 세계의 데이터베이스로 옮기는 변환과정이다.
즉, 현실세계의 무언가를 추상화하여 데이터로 옮긴다.

예를들어 위 인물을 추상화하여 데이터로 나타내보자.
group : asepa
age : 23
nickname : winter
...etc.이렇게 작성된 특징들을 데이터베이스에 저장한다. 이를 데이터 모델링이라고 한다.
=> 마치 객체지향에서 객체를 정의할 때와 유사하다.
데이터 모델
데이터모델링으로 만들어진 결과다. 데이터모델은 크게 두가지로 나뉜다.
- 개념적 데이터 모델
사람의 머리로 이해할 수 있도록 현실세계를 개념적 모델링하여 데이터베이스의 개념적 구조로 표현한다. - 논리적 데이터 모델
개념적 구조를 논리적 모델링하여 데이터베이스의 논리적 구조로 표현한다.
바로 윗 목차에서 예시로 든 인물의 추상화는 개념적 데이터 모델에 가깝다.
이를 논리적 데이터 모델로 한번 변환해보자. 이때 테이블, 속성, 관계등을 구체적으로 정의해야한다.
Person Table
-------------
| id | group | age | nickname |
|------|--------|------|----------|
| 1 | aespa | 23 | winter |결국 개념적 데이터 모델은 Entity에서 특징을 뽑아냄을 의미하고, 논리적 데이터 모델은 이 특징들을 데이터베이스에 어떻게 저장할 것인지를 정하는 방법이다.
개체-관계 모델(E-R model; Entity-Relationship model)
개체(Entity)와 개체간 관계를 이용해 현실세계를 개념적 구조로 표현하는 모델이다.
이를 그림으로 표현한 것이 E-R 다이어그램이다.
E-R 다이어그램이란?
개념적 설계를 진행할때 개념적 스키마(E-R 다이어그램)을 작성한다고 하였다.
E-R 다이어그램(Entity-Relation Diagram)이란, 개체와 관계의 모델이다.
도형과 선분을 이용해서 개체-관계를 다이어그램으로 표현한다. 잠시 후 실습을 통해 알아보자.
E-R다이어그램(ERD)를 알아보자
E-R다이어그램은 개체와 관계의 모델을 다이어 그램으로 표현한다고 하였다.
여기서 말하는 개체와 관계는 정확히 무얼 의미하는걸까?
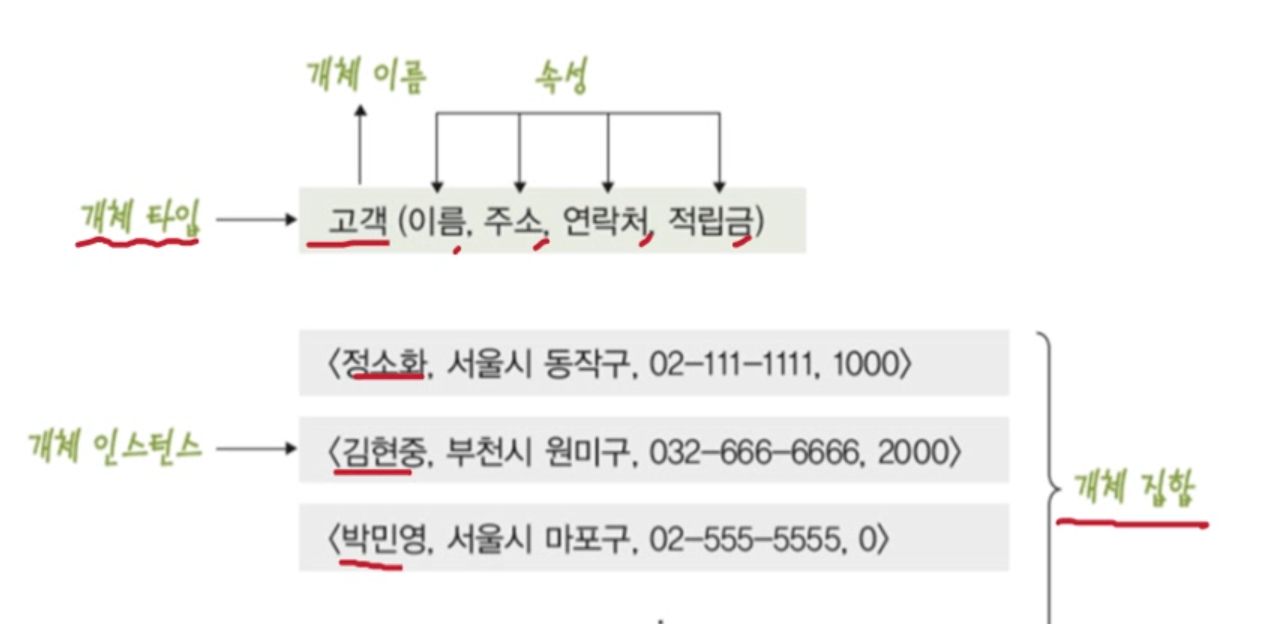
개체(Entity)
현실세계에서 구별되는 모든 것, 저장할 가치가 있는 중요 데이터를 가지고 있는 사람, 사물 개념, 사건, 다른 개체와 구별되는 이름을 갖고있으며 각 개체만의 고유한 특성이나 상태(속성)을 갖고있다.
예시로 도서관에 필요한 개체는 책, 사용자다.
만약 예시가 학교라면 학생, 선생님, 과목등 이다.
이러한 개체들은 파일 구조의 레코드와 대응된다.
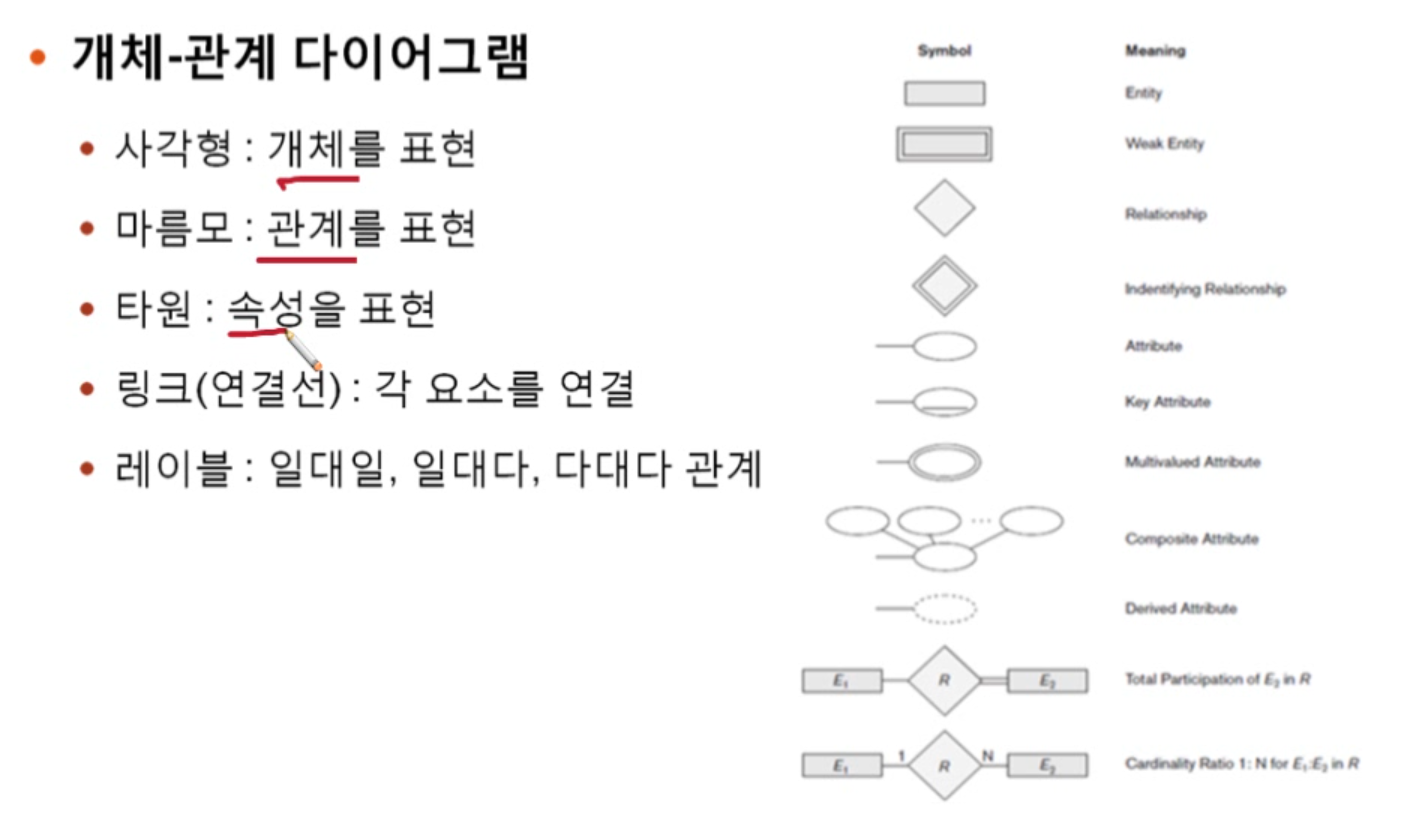
이를 E-R 다이어그램으로 표현 시 사각형으로 표현한다.

개체의 분류
- 개체 타입 : 개체를 고유의 이름과 속성들로 정의한 것.
- 개체 인스턴스 : 개체를 구성하는 속성이 실제 값을 가짐으로써 실체화된 개체.
- 개체 집합 : 특정 개체 타입에 대한 개체 인스턴스들을 모아놓은 것.
속성(attribute)
개체, 관계가 가지고 있는 고유의 특성을 의미한다. 특히 의미있는 데이터의 가장 작은 논리적 단위다.
E-R다이어그램으로 표현시 타원으로 나타낸다.
속성의 분류
- 속성 값의 개수 : 고객의 이름은 단일 값 속성이지만, 전화번호는 다중 값 속성일 수 있다.
- 의미 분해 가능성 : 고객의 이름은 성, 이름으로 분리가능하기에 복합 속성이지만, 아이디는 단일 값이기에 단일 속성이다.
- 유도 속성 : 다른 속성에 의해 가지게된 속성을 뜻한다. 주민등록번호를 통해 나이를 알게된다면, 유도속성이다.
- 널 속성(null) : 널 값이 허용되는 속성. 예를들어 고객 등급.
- 키 속성(key) : 각 개체 인스턴스를 식별하는데 사용된다.(고유함) 예를들면 고객 아이디
관계(relationship)
개체와 개체가 맺고있는 의미있는 연관성을 뜻한다. 예를들어 고객과 책개체간의 관계는 구매로 나타낼 수 있다.
E-R 다이어그램으로 표현시 마름모꼴로 나타낸다.
관계의 유형
관계의 유형은 개체 타입 수기준으로 분류도 가능하다.
- 이항 관계 : 개체 타입 두 개가 맺는 관계
- 삼항 관계 : 개체 타입 세 개가 맺는 관계
- 순환 관계 : 개체 타입 하나가 자기자신과 맺는 관계
또한 매핑 카디널리티(mapping cardinality)기준으로도 분류가 가능하다.
! cardinality: 특정 데이터 집합의 유니크한 값의 개수
- 1:1 관계
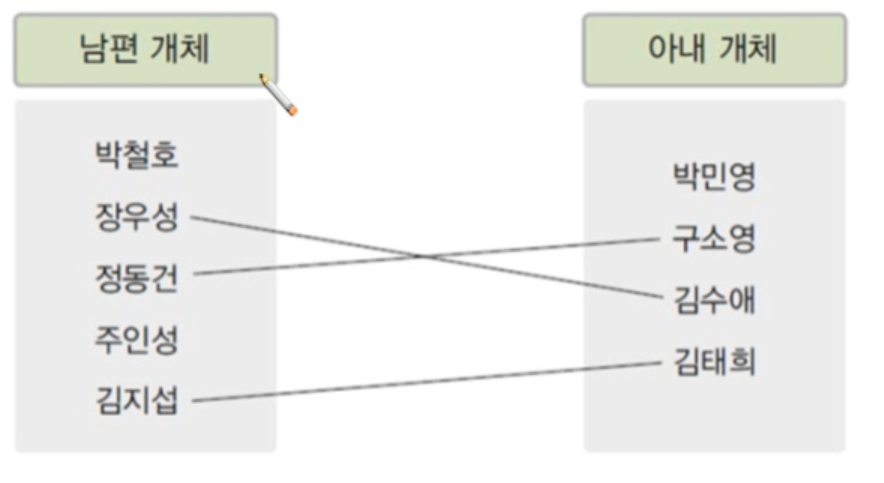
예를들자면 대한민국은 일부일처제다. 따라서 1:1관계가 성립된다. - 1:n 관계
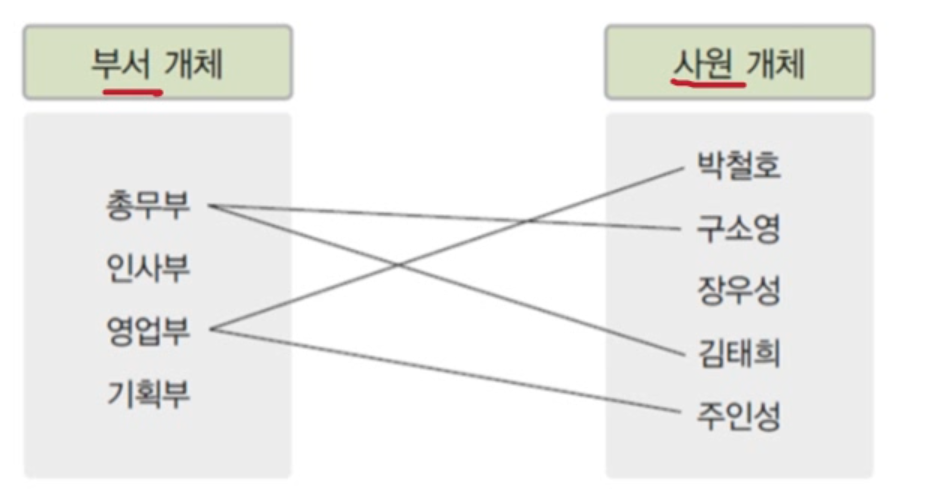
하나의 부서에는 여러 사원이 포함될 수 있다. 이는 1:n 관계다. - n:m 관계
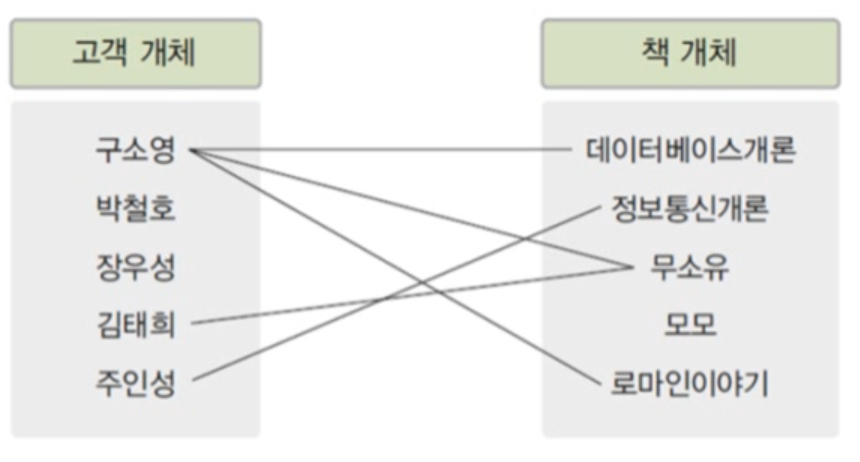
한 고객이 여러 책을 구매할 수 도있고, 여러 고객이 한 책을 구매할 수도 있다. 이는 n:m관계다.
여기서 말하는 매핑 카디널리티란, 관계를 맺는 두 개체 집합에서 각 개체 인스턴스가 연관성을 맺고있는 상대개체 집합의 인스턴스 개수다.
관계의 참여 특성
- 필수적 참여(전체참여) : 모든 개체 인스턴스가 관계에 반드시 참여해야하는 것을 의미한다.
=> 모든 고객은 회원가입시 아이디를 가지게 된다. - 선택적 참여(부분참여) : 개체 인스턴스중 일부만 관게에 참여해도 된다.
=> 어떤 고객은 책을 구매하지만, 어떤 고객은 책을 구매하지 않는다.
관계의 종속성
- 약한 개체(weak entity): 다른개체의 존재여부에 의존적인 개체
=> 책이 존재해야 가격도 존재한다. - 오너 개체(owner entity) : 다른 개체의 존재여부를 결정하는 개체
=> 가격의 존재여부를 결정하는 책
오너 개체와 약한 개체는 일반적으로 1:n의 관계를 갖게된다. 또한 약한개체는 오너개체에 필수적으로 참여하며 약한 개체는 오너 개체의 키를 포함하여 키를 구성하는 특징이 있다.
=> 책이 있으면 가격도 있고 장르등 도 있다. 이때 키를 구성할땐 어떤 책인지 구분해야하므로 책의 키를 포함하여 자신의 키를 구성한다.
ERD 그리는 법 요약
ERD 해석해보기
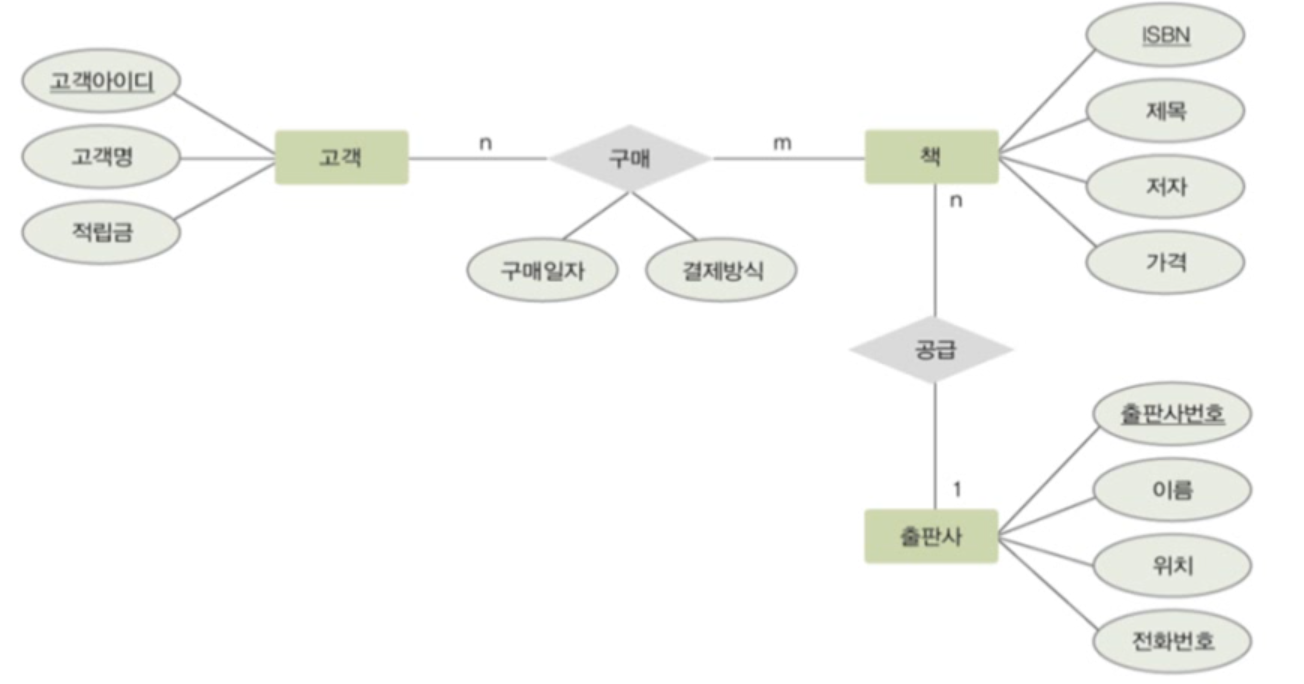
이 파트는 다음 학습시간에 진행해보도록 하겠습니다
사견을 제외한 모든 내용은
http://www.kocw.net/home/enrolment/enrolmentView.do?cid=9c591659f017851e&lid=3f649d95955b9199
에서 발췌하였습니다.
