데이터베이스의 기본 개념
겉핥기 식으로 알고있던 DB가 아닌, 전공 수준의 지식을 한번 배워보자!
데이터 베이스의 필요성
데이터 베이스가 왜 필요할까? 에 답하려면, 먼저 데이터란 무엇인가? 에 답할 수 있어야 한다.
데이터와 정보
- 데이터(data) : 현실세계에서 관찰한 측정값 또는 사실.
- 정보(information) : 의사 결정에 유용하게 활용할 수 있도록 데이터를 처리한 결과물.
아하! 그러니까, 데이터는 날것이고 정보는 데이터가 정제된 결과물이다.
예를들어 백엔드에서 보내준 일련의 데이터를 정제하여 필요한 정보만 뽑아내서 사용한다.
위처럼 데이터에서 정보를 추출하는 과정을 정보처리(information processing)라고 한다.
또한, 데이터는 자연발생하지 않는다. 즉 수집과 저장을 하여야 데이터가 비로소 생긴다.
이를 행해주는 곳이 바로 정보 시스템(information system)이라고 한다.
그래서, 데이터베이스(DB)가 뭘까?
컴퓨터 과학 관련 지식은 항상 한자가 많아서 의미가 바로 와닿지 않는다...🤔

그냥 쉽게 예를 들어보자!

책이 데이터라면, 도서관은 데이터 베이스라고 볼 수 있다.
= 여러 사용자(도서관 이용자)들이 공유하여 사용할 수 있도록 통합해서 저장한 데이터의 집합.
이때 도서관에서는 책을 그냥 보관하지 않는다. 도서에 임의의 번호를 붙이거나, 초성 순으로 책을 배열하여 사용자가 찾기 쉽게 만들어준다.
이처럼 데이터 베이스는 단순히 보관하는 용도에서 그치지 않는다.
데이터베이스의 핵심 개념 4가지
- 데이터 통합(intergrated data) : 데이터는 최소 중복과 통제가능한 중복만 허용하는 데이터.
- 저장 데이터(stored data):: 컴퓨터가 접근할 수 있는 매체에 저장되는 데이터. 주로 컴퓨터를 이용하기 때문이다.
- 공유 데이터(shared data) : 특정 조직의 사용자가 함께 소유하고 이용할 수 있는 공용데이터 이용할 수 있는 공용데이터
- 운영 데이터(operational data) : 조직의 주요 기능을 수행하기 위해 지속적으로 유지해야하는 데이터.
데이터베이스의 특징
데이터베이스는 이러한 특징을 가진다.
- 실시간 접근(real-time accessibility) : 사용자의 데이터 요청에 실시간 응답.
- 연속적 변화(continuous evolution) : 데이터의 연속적인 삽입-삭제-수정을 통해 데이터의 정확성을 유지.
- 동시 공유(concureent sharing) : 서로 다른 데이터의 동시사용뿐 아니라 같은 데이터의 동시 사용도 지원.
해당 특징으로 인하여, 동시성 문제가 발생하게 되는거구나? - 내용 기반 참조(content reference) : 데이터가 저장된 주소, 위치가 아닌 내용으로 참조.
=> 예) 인덱스, 몇 번째 줄등이 아닌 성인 남성 연봉 5000만원 이상인 사람을 검색
데이터베이스 관리시스템
현재는 데이터를 관리하기위해 데이터베이스 관리 시스템(Data Base Management System)를 사용하는게 기본이다.
허나 DBMS 등장 이전에는, 재밌는 방식으로 데이터베이스를 관리하였다.
과연 어떻게 했을까? 설마 메모장같은 텍스트로 이루어진 파일로 대충 저장해서 사용했던걸까?
파일 시스템(file system)
파일시스템이란, 데이터를 파일로 관리하기 위하여 파일을 생성-삭제-수정-검색하는 기능을 제공하는 소프트웨어를 뜻한다.
예를들어 A프로그램은 A파일을 사용하고, B프로그램은 B파일을 사용하여 데이터를 관리했었다.
흠 와닿지가 않는다. 조금 더 자세히 들여다보자.
예를들어, 고객의 정보(이름, 전화번호, 주소)를 관리해야한다.
//customers.txt
홍길동, 010-1234-5678, 서울시 강남구
이영희, 010-9876-5432, 서울시 서초구
김철수, 010-2222-3333, 서울시 송파구이 파일을 읽고 고객 정보를 찾으려면, 위 파일의 규격대(쉼표로 구분하던가 아무튼...)로 읽어오는 파일시스템이 필요하다.
예를들어 이영희라는 고객의 전화번호를 수정하려면 파일을 처음부터 끝까지 읽고 직접 수정후 파일을 다시 저장해야한다.
이는 프로그램 개발에 대한 번거로움 뿐만 아니라, 데이터 중복, 데이터의 무결성, 동시성 문제등 다양한 오류를 야기할 수 있다.
암만봐도 문제점이 많다. 이는 현재 DBMS가 널리퍼져 DBMS사용에 익숙해서 그런것 일 수도 있다.
아무튼 DBMS가 왜 필요한지 알았다!
데이터베이스 관리시스템의 주요 기능
- 정의 기능 : 데이터베이스 구조를 정의하거나 수정할 수 있다.
- 조작 기능 : 데이터를 삽입-삭제-수정-검색 하는 연산을 할 수 있다.
- 제어 기능 : 데이터를 항상 정확하고 안전하게 유지할 수 있다.
위 부분은 사용자의 몫이 커보이는데, 시스템단위로 어떻게 도와주는걸까?🙄
이러한 주요기능덕분에 파일 시스템에서 겪던 문제를 해결할수 있게되었다.
데이터 중복, 데이터의 독립성, 동시성 문제, 보안, 무결성 등. 또한 표준화할 수 있게되어 개발 비용이 줄어든다는 장점도 있다.
무릇 모든 선택이 그렇듯 장점만 있는 건 아니다.
단순하게 저장하는 파일시스템에 비해 비용(구매비용, 유지비)이 많이 든다.
또한 백업과 회복 방법이 복잡하고, 중앙집중 관리로 인하여 취약점이 존재한다.
그래도 파일 시스템보다는 훨씬 낫구먼
데이터베이스 관리 시스템의 역사
데이터베이스 관리 시스템이 나온지 몇십년도 넘어서, 세대로 구분한다.
파일 시스템을 1세대로 묶는 경우도 있는데, 그냥 강의에 나온대로 적어보겠습니다!
1세대) 계층형 DBMS
회사
├─ 부서1
│ ├─ 직원1
│ └─ 직원2
└─ 부서2
├─ 직원3
└─ 직원4
위처럼 계층형태인 트리 구조로 데이터를 관리한다. 각 부모는 여러자식을 가질 수 있지만, 자식은 오직 하나의 부모만을 가질 수 있다.
따라서 하나의 관계만 허용된다. 이때문에 관리하기는 쉽지만 복잡한 데이터를 표현하기에는 어려움이 있다.
1세대) 네트워크형 DBMS
A ──> B ──> C
│ ^
└───────────┘위처럼 그래프 구조로 데이터를 관리한다. 자식이 여러 부모를 가질수 있다. 이를 통해 복잡한 데이터를 다룰 수 있다. 허나 복잡한 구조로 인하여 관리가 어려워질 수 도 있다.
2세대) 관계 DBMS
데이터베이스를 테이블형태로 구성한다. 즉, 표형태로 구성한다.
table은 책상인데, 왜 표라고할까?
이렇게 데이터를 표로 구성한다.
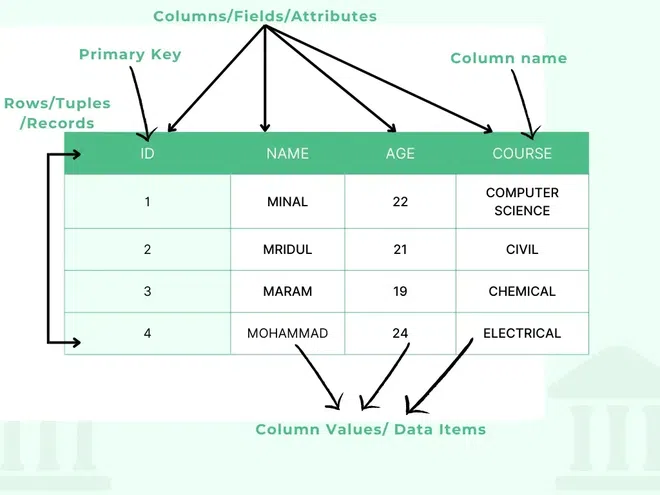
어디서 많이 봤는데, MySQL인가?
3세대) 객체지향 DBMS
객체지향이 여기서도 튀어나와...? 잘 모르는데, 얼른 공부해야겠다.
아무튼 객체를 이용해서 데이터베이스를 구성하는게 객체지향 DBMS다.
다만 2세대보다 난해해서 보통 2세대 관계형 dbms를 자주사용한다.
모든 내용은
http://www.kocw.net/home/enrolment/enrolmentView.do?cid=9c591659f017851e&lid=a46fe8f556042e45
에서 발췌하였습니다
