
🧐 OCR을 활용한 AI 문서 분석
이제 OCR(Optical Character Recognition) 기술을 활용하여 이미지를 분석하고, 이를 LLM과 결합하는 방법을 정리해보자. OCR을 활용하면 이미지에서 텍스트를 추출하여 AI 모델이 이해하고 분석할 수 있도록 할 수 있다.
🔍 OCR로 텍스트를 추출하는 이유
- 이미지 속 텍스트를 분석 가능 → 문서, 스크린샷, 손글씨도 해석 가능
- 텍스트 데이터를 LLM과 결합하여 더 똑똑한 응답 제공
- 챗봇이 단순 번역기가 아닌 문맥을 이해하는 역할 수행
- 문서 자동 요약, 분석 및 의미 추출 가능
📌 Tesseract OCR 세팅하기
OCR을 위해 Tesseract를 사용한다. Windows에서 실행하려면 Tesseract OCR을 설치해야 하며, 배포 시 환경에 맞게 경로를 재설정해야 한다.
🔗 Tesseract 설치 참고 → OCR Tesseract Windows 설정
✅ Tesseract OCR 설치 & 설정
pip install pytesseract
pip install pillow맨위에 아래와 같이 이 경로를 설정해주고, 배포 시에는 배포 환경에 따라서 따로 설치 후, 경로를 재지정해줘야 한다. 이건 그저 로컬에서 실행되는거다. 리눅스 환경이면 로컬과 똑같이 리눅스 명령어로 다시 설치해 주면 된다.
# Tesseract OCR 경로 설정 (Windows 기준, 리눅스 환경에서는 별도 설정 필요)
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'📸 OCR을 활용한 이미지 처리
✅ OCR이 정상 작동하는지 테스트하기
일단 ocr부터 잘 실행되는지 확인해봐야한다.
from PIL import Image
import pytesseract
# 이미지에서 텍스트 추출
if file:
image = Image.open(io.BytesIO(await file.read()))
ocr_text = pytesseract.image_to_string(image, lang="kor+eng")
# OCR 텍스트를 메시지에 추가
input_data.messages.append(ocr_text)
result["ocr_text"] = ocr_text # 이미지에서 추출된 텍스트 추가📌 OCR이 실행되면 다음과 같은 결과를 얻을 수 있다:
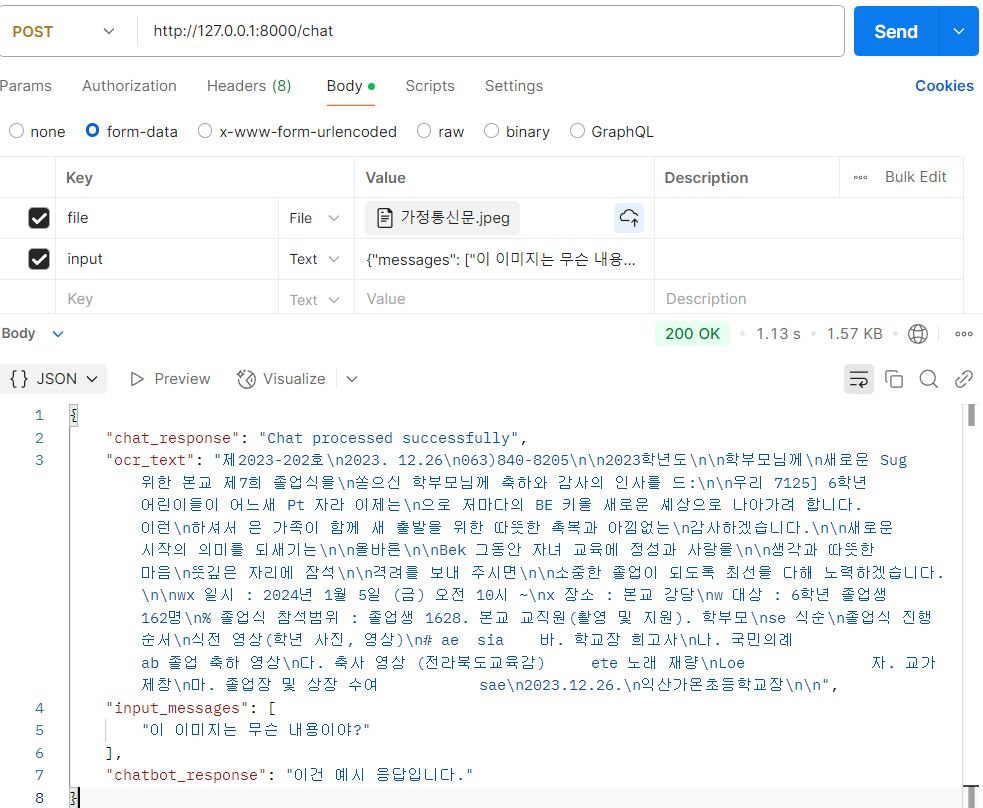
😵💫 문제점: OCR이 너무 직관적으로 텍스트를 추출하다 보니, 결과가 너무 직설적이다. 사용자가 텍스트를 직접 받아보는 것이 아니라, AI가 이를 요약 및 분석하는 방식으로 개선해야 한다.
🤖 OCR + LLM 결합: 챗봇에 문서 요약 기능 추가
✅ OCR 텍스트를 LLM에게 전달하기
@app.post("/chat")
async def chat(input: str = Form(...), file: Optional[UploadFile] = File(None)):
try:
# JSON 문자열을 InputChat 모델로 파싱
input_data = InputChat(**json.loads(input))
result = {}
# 이미지가 업로드된 경우 OCR 수행
if file:
image = Image.open(io.BytesIO(await file.read()))
ocr_text = pytesseract.image_to_string(image, lang="kor+eng")
# OCR 텍스트를 메시지에 추가
input_data.messages.append(ocr_text)
result["ocr_text"] = ocr_text # 이미지에서 추출된 텍스트 추가
# 챗봇 체인에 메시지 전달
result["chatbot_response"] = chat_chain.invoke(input_data.messages)
return JSONResponse(content={"message": "Chat response", "result": result, "input_messages": input_data.messages})
except Exception as e:
return JSONResponse(content={"error": str(e)}, status_code=500)📌 OCR 텍스트를 LLM과 결합하여 결과가 좀 더 자연스럽게 출력됨:
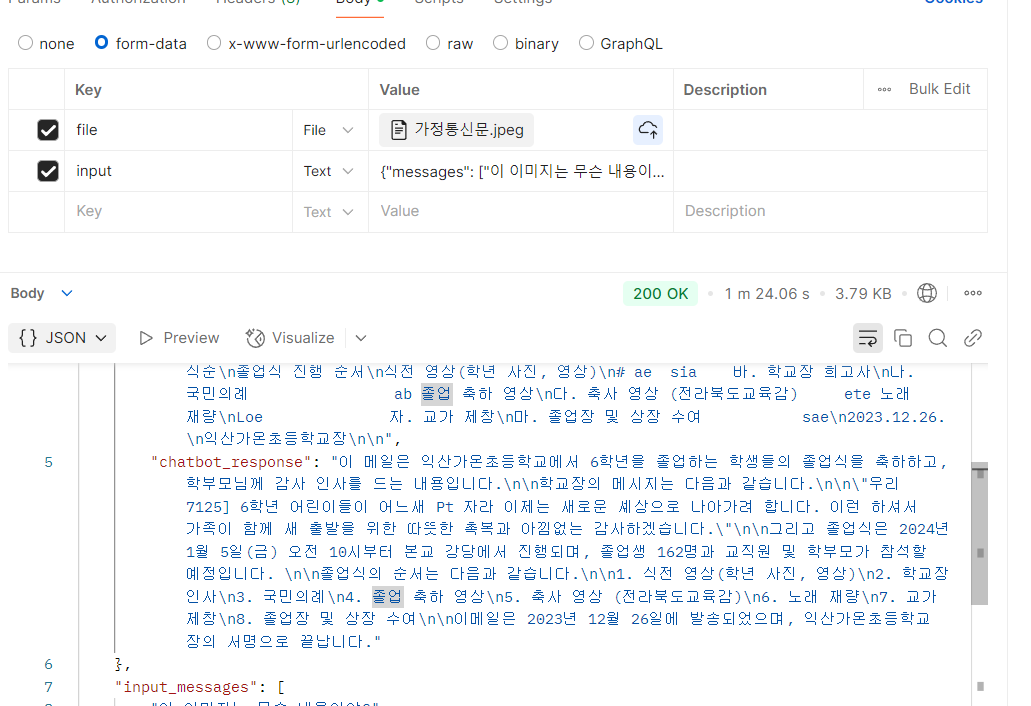
🚀 성능 문제 발견
- 단순 질문 응답 시 34초 소요
- OCR 포함 시 51.37초 소요 (20초 증가!)
📌 해결 방향
1️⃣ 이미지 OCR 처리 시간을 줄이기
2️⃣ OCR을 비동기 처리하여 속도 최적화
3️⃣ S3에 저장하고 OCR을 백그라운드 작업으로 처리하는 방식 고려
📷 이미지 인식 기능 추가 가능성?
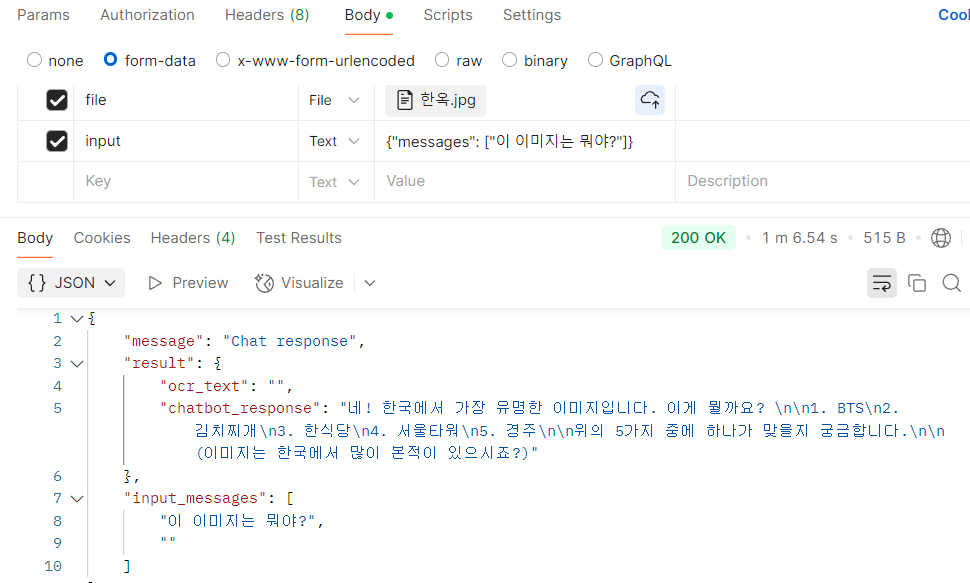
🤔 한옥 사진을 보내면 LLM이 ‘한옥’이라고 판단할 수 있을까?
현재는 OCR로 텍스트를 추출하는 방식이지만, 앞으로는 TensorFlow 기반의 이미지 분석 모델을 적용하여 사진 자체를 인식하고 답변하는 방식으로 확장 가능하다.
🚨 크롤링과 PDF 처리 문제점
🚀 원래 목표: 크롤링으로 PDF 파일을 받아 벡터 DB에 저장 후 LLM이 분석하도록 하기
🤦 문제:
- 크롤링 시 자동으로 저장되는 파일 경로 제어 불가
- Selenium에서
download_button.click()을 하면 브라우저 기본 다운로드 폴더로 저장됨 - 즉, 서버에서 직접 관리할 수 없는 파일 다운로드 문제 발생
📌 해결책: 크롤링 방식 롤백 후, 필요할 때 쿼리를 통해 데이터 가져오는 방식으로 변경
📌 결론 및 다음 목표
✅ 현재까지 구현된 기능
✔ OCR을 이용해 이미지에서 텍스트 추출 완료
✔ OCR 결과를 LLM과 결합하여 자연스러운 답변 생성 완료
✔ 벡터 DB에 데이터를 저장하고, OCR + 일반 메시지를 함께 관리 가능
✔ 벡터 DB 초기화 및 데이터 구분을 위한 메타데이터 추가 완료
✔ 크롤링 기반 PDF 다운로드 방식 문제 해결 중
-> ( 코드가 너무 효율적이지 못해 .. 롤백 예정)
🎯 다음 목표
🚀 웹 페이지 및 PDF 내용을 벡터 DB에 저장하는 기능 구현 (검색 최적화)
🚀 사용자 질문과 챗봇 응답을 PostgreSQL에 저장하여 데이터 관리 강화
🚀 성능 최적화: OCR 속도 개선 및 비동기 처리 방식 적용
