
🔥 Ollama 기반 AI 모델 구축하기
최근 Ollama를 활용한 LLM 구축이 주목받고 있다. 특히, LangServe를 이용한 원격 Ollama 서버 구성과 GGUF 포맷의 모델 적용이 핵심이다. 이번 포스트에서는 Ollama를 활용하여 RAG(Retrieval-Augmented Generation) 시스템을 구축하는 방법을 다룬다.
1️⃣ Ollama를 LangServe로 도입하기
로컬에서 Ollama를 실행하면 개인 PC에서만 사용이 가능하다. 하지만, 이를 LangServe에 배포하면 다른 사용자가 접근할 수 있는 원격 Ollama 서버를 만들 수 있다.
✅ 필요한 작업
1. GGUF 모델 다운로드
2. Modelfile 생성 및 모델 등록
3. LangServe를 통한 서버 배포
GGUF란?
GGUF(Graphical Unified Format)는 라지 모델을 저장하는 파일 포맷으로, 다양한 LLM을 지원한다. 우리는 Meta-Llama-3-8B-Instruct.Q8_0.gguf 모델을 활용할 예정이다.
모델 다운로드 링크: Meta-Llama-3-8B-Instruct
# Ollama 설치 후 모델 다운로드
ollama pull llama32️⃣ Modelfile 작성 및 모델 생성
이제 Modelfile을 작성하여 LLaMA 모델의 프롬프트 구조, 시스템 설명, 생성 파라미터 등을 설정한다.
📌 Modelfile 예제
FROM Meta-Llama-3-8B-Instruct.Q8_0.gguf
TEMPLATE """{{- if .System }}
<|begin_of_text|>system {{ .System }}<|end_of_text|>
{{- end }}
<|begin_of_text|>user
{{ .Prompt }}<|end_of_text|>
<|begin_of_text|>assistant
"""
SYSTEM """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."""
PARAMETER temperature 0
PARAMETER num_ctx 4096
PARAMETER stop <|begin_of_text|>
PARAMETER stop <|end_of_text|>✅ Modelfile을 적용한 모델 생성
ollama create llama3-instruct-8b -f Modelfile✅ 모델이 정상적으로 생성되었는지 확인
ollama list✅ 모델 실행 테스트
ollama run llama3-instruct-8b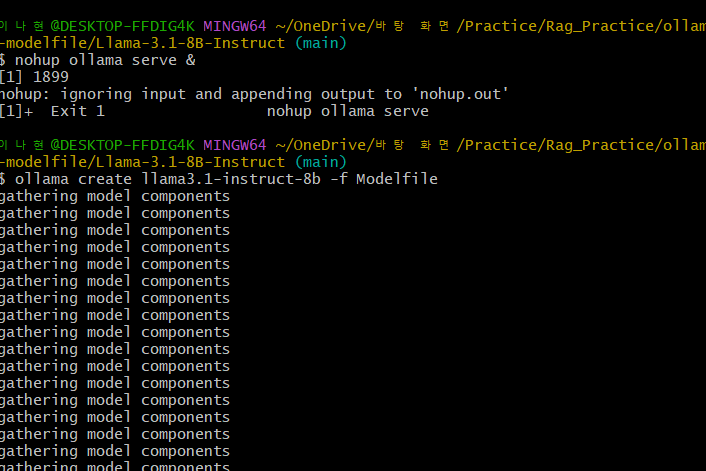
이렇게 가동시켜준 뒤, ollama list 명령어를 활용해 가동 되는지 확인ㄱㄱ
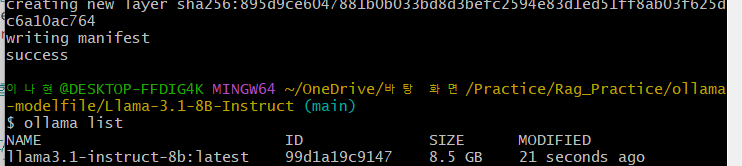
잘 됨 ㅇㅇ
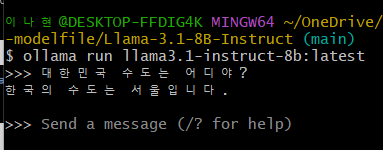
로컬에서도 혹시 모르니까 돌려보고, 정상적으로 작동하는것을 확인한다.
여기서 ollama run 뒤에 list로 확인했던 가동된 이름을 넣어 실행시킨다.
얘는 메모리를 좀 잡아먹으니 프로그램을 여러개 띄우고 실행하면 오류 나니까 참고해야한다.
여기까지 올라마에 gguf 파일을 올려 올라마 세팅이 끝난것이다.
이제 랭체인에 들어가야한다.
파일을 열고 서버랑 클라이언트 집중으로 파일을 만들어 볼 것이다.
이제 아래부터는 fast api를 공부해야한다.
3️⃣ FastAPI를 활용한 Ollama 배포
Ollama 모델을 API 형태로 배포하려면 FastAPI와 Uvicorn을 사용해야 한다.
파이썬은 3.10.10 다운하였다.
https://www.python.org/downloads/windows/
✅ FastAPI & Uvicorn 설치
FastAPI는 가지고 있지 않지만, 개발용 서버를 갖기 위해 uvicorn을 설치해줘야 한다.
pip install fastapi uvicorn✅ FastAPI 서버 코드 작성 (main.py)
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def hello():
return {"message": "Hello, World!"}✅ FastAPI 실행
uvicorn main:app --reload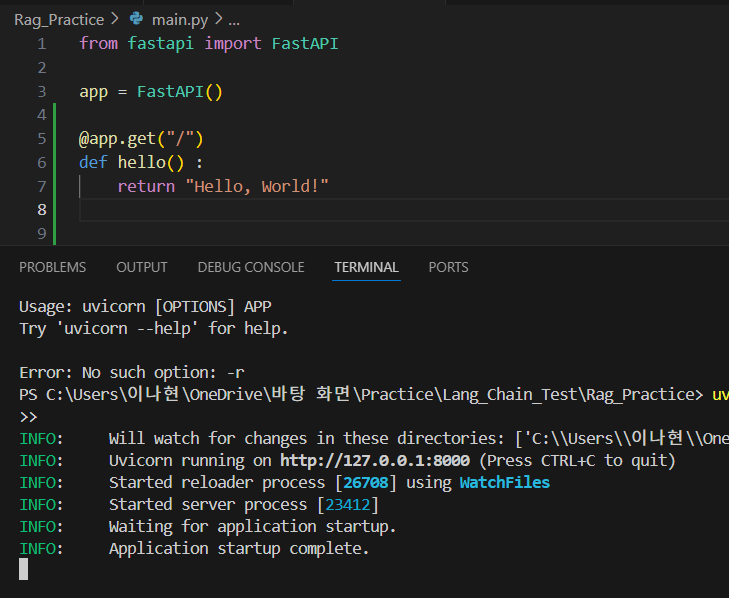
이렇게 로컬 주소를 띄워주는데 들어가보면 return한 값이 메인페이지에 출력되는것을 볼 수 있다.
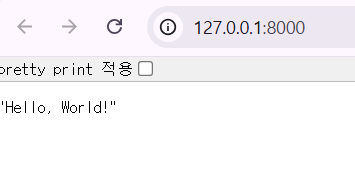
주소에 /docs나 /redoc 을 치면, OpenAPI와 연동되어 문서를 볼 수 있다.
둘이 다른 UI 디자인의 명세서인데 맘에 드는걸로 하면된다.
1. http://127.0.0.1:8000/redoc
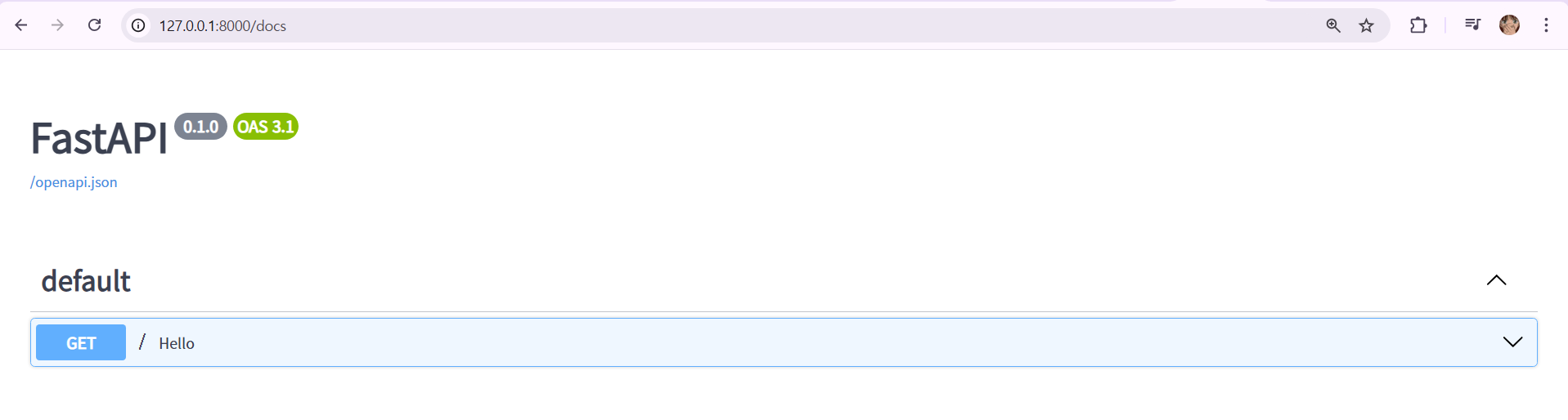
2. http://127.0.0.1:8000/docs
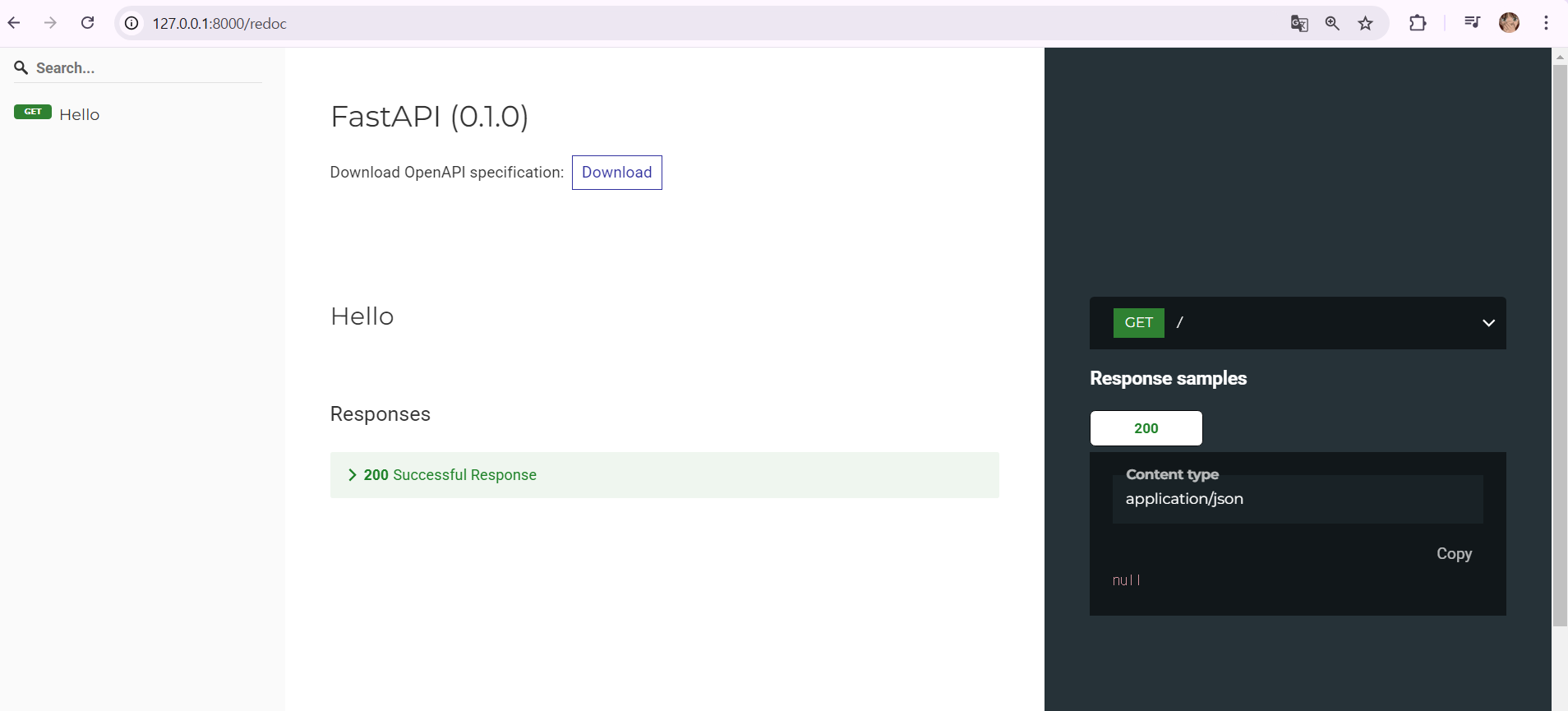
✅ API 테스트
http://127.0.0.1:8000/접속 후 응답 확인http://127.0.0.1:8000/docs || redoc에서 API 문서 확인 가능
4️⃣ LangChain과 Ollama 연동하기
이렇게 ollama를 활용한 LangChain을 맛보기 전에 세팅할 것을 다 완료 하였다면, chain에 사용할 main 파일과 클라이언트, 서버 파일정도만 존재하면 된다.
그리고 아래와 같은 명령어로 LangChain 관련 모듈들을 사용할것이기 때문에 몇 가지 라이브러리를 설치한다.
✅ LangChain 관련 패키지 설치
pip install langchain langchain-core langchain-ollama fastapi uvicorn이제 Ollama 모델을 LangChain에서 사용할 수 있도록 설정한것이다.
pip install fastapi uvicorn langchain langchain-core langchain-ollama
아.. 하다보니까 설치가 끝도 없어서 너무.. 정신이 없더라고요?
그래서 requirements.txt 파일을 만들어줬다.
requirements.txt 파일
fastapi
uvicorn
pydantic
fastapi[all]
langchain
langchain-core
langserve
.
.
.- 프로젝트 폴더에 requirements.txt라는 파일을 생성
- 설치할 라이브러리 명을 텍스트로 넣기
- 아래 명령어로 필요한 패키지를 한 번에 설치가 가능
pip install -r requirements.txt✅ LangChain을 활용한 AI 모델 실행 코드
from langchain.llms import Ollama
llm = Ollama(model="llama3-instruct-8b")
response = llm("What is the capital of France?")
print(response)✅ RAG 시스템 적용을 위해 벡터 데이터베이스(VectorDB) 선택
- FAISS: 빠른 검색 속도 (오픈소스)
- ChromaDB: LangChain과 높은 호환성
- Pinecone: 클라우드 기반 솔루션
우리는 무료로 사용 가능하며, LangChain과 잘 통합되는 ChromaDB를 선택할 것이다.
✅ ChromaDB 설치
pip install chromadb✅ LangChain + ChromaDB로 검색 및 RAG 구현
from langchain.vectorstores import Chroma
from langchain.embeddings import OllamaEmbeddings
# 임베딩 모델 설정
embedding_function = OllamaEmbeddings(model="llama3-instruct-8b")
# 벡터 DB 설정
vector_db = Chroma(persist_directory="./chroma_db", embedding_function=embedding_function)
# 문서 검색
query = "What is Retrieval-Augmented Generation?"
docs = vector_db.similarity_search(query, k=5)
for doc in docs:
print(doc.page_content)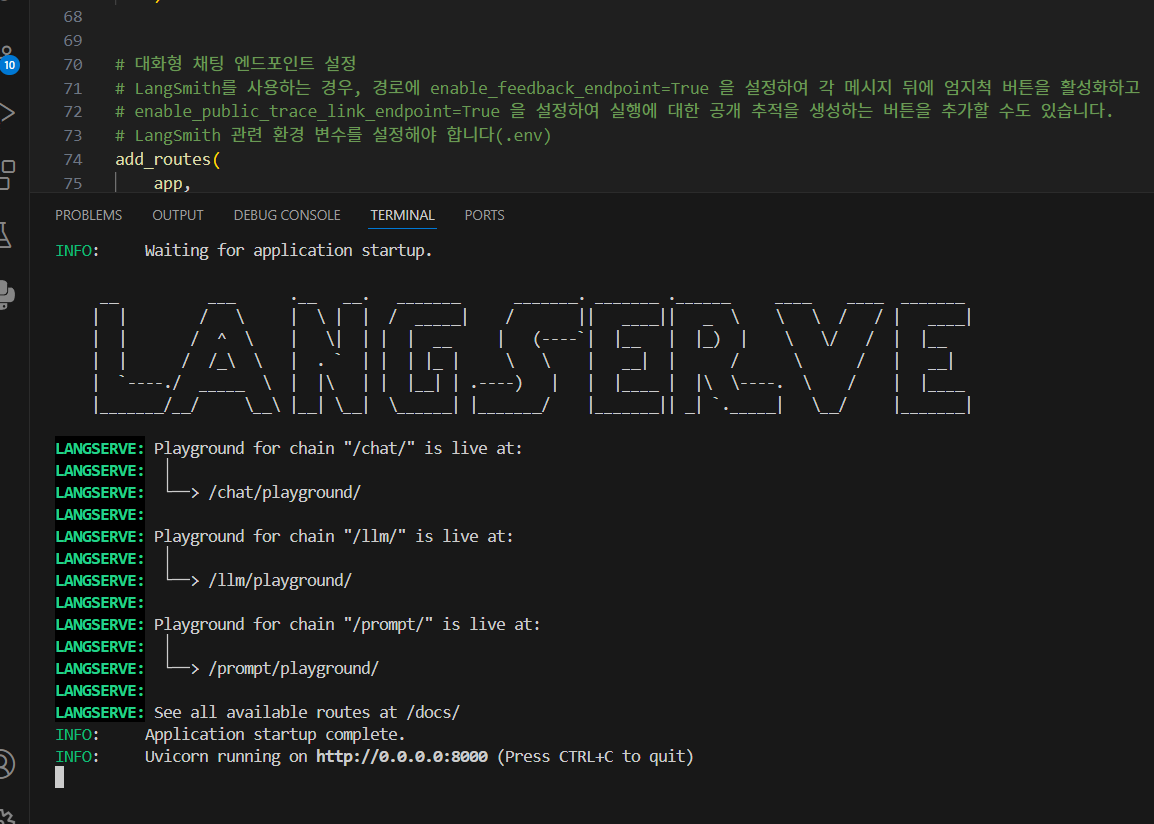
막 이렇게 하고 하다보면 main 역할하는 파일이 있을거다.
그걸 실행해주면 LANGSERVER 가 엄청 예쁘게 실행이 될것이다.
python server.py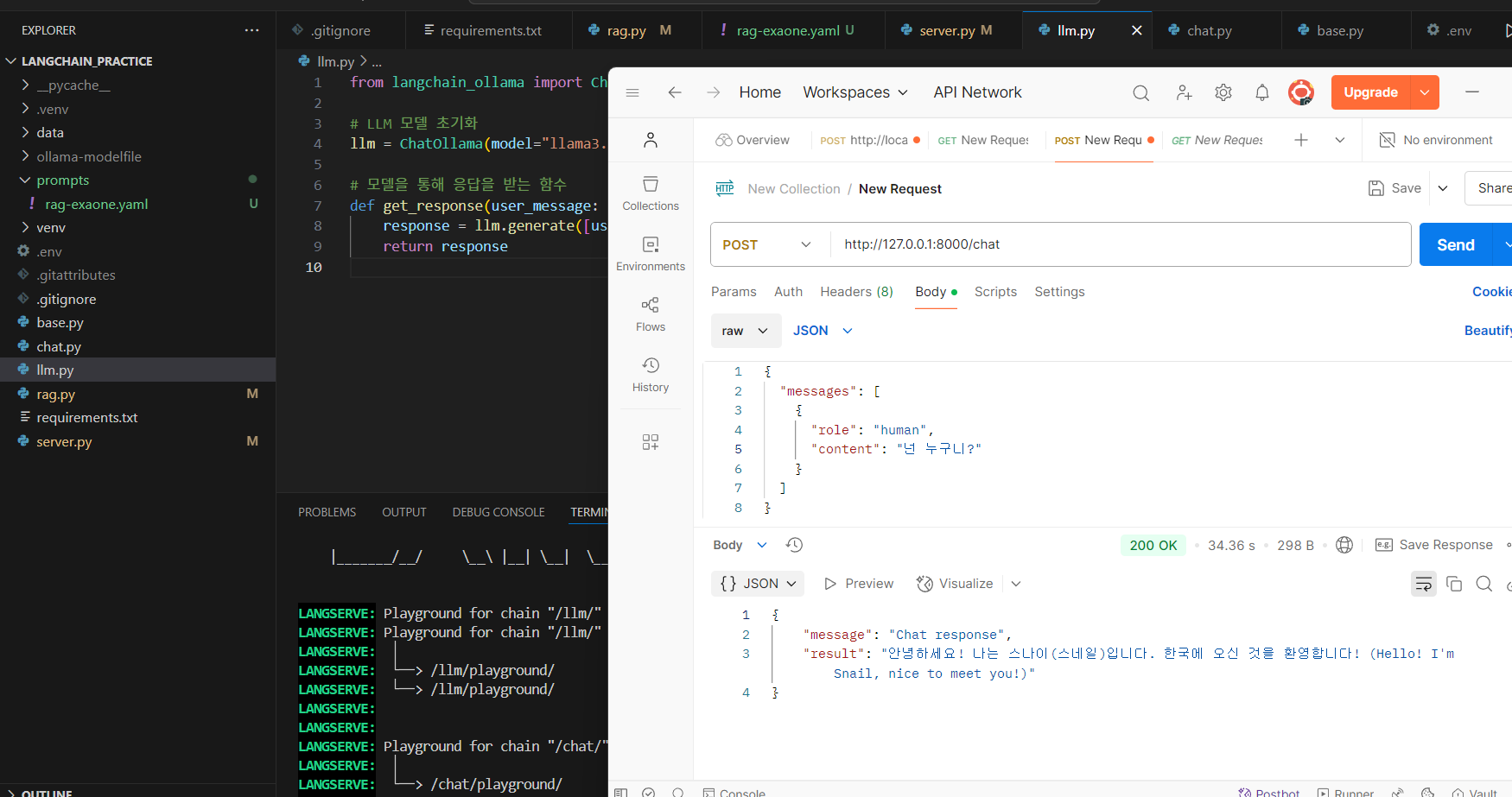
이렇게 fastapi를 사용하여 restapi를 간략하게 작성하고, 200 성공이 되는것을 확인할 수 있다.
💡 프롬프트 엔지니어링: 리스트 방식 vs. 템플릿 방식
AI가 사용자 질문에 더 자연스럽게 응답하도록 하려면, 프롬프트 구조가 중요하다.
아래는 두 가지 대표적인 프롬프트 설계 방식이다.
| 항목 | 리스트 방식 📝 | 템플릿 방식 📄 |
|---|---|---|
| 프롬프트 구조 | 시스템 메시지 + 사용자 메시지를 동적으로 처리 | 템플릿 기반으로 프롬프트를 단순 제공 |
| 유연성 | 유동적이고 복잡한 대화 흐름 구성 가능 | 단순한 프롬프트 구성, 복잡한 대화에는 부적합 |
| 구현 난이도 | 다소 복잡, 동적 메시지 관리 필요 | 간단하고 직관적, 빠르게 구현 가능 |
| 적합한 용도 | 역할 기반 AI, 대화형 챗봇, 다중 문맥 필요할 때 | 간단한 정보 제공, Q&A 형태 응답 |
| 복잡한 대화 처리 | 가능 | 제한적 |
👉 개인적인 선택:
과거에 GPT 프롬프팅을 리스트 방식으로 설계했던 경험이 있어 더 익숙하고,
동적 커스텀이 가능하여 대화 흐름을 유연하게 제어할 수 있다는 점이 장점이라 판단해 리스트 방식을 선택했다.
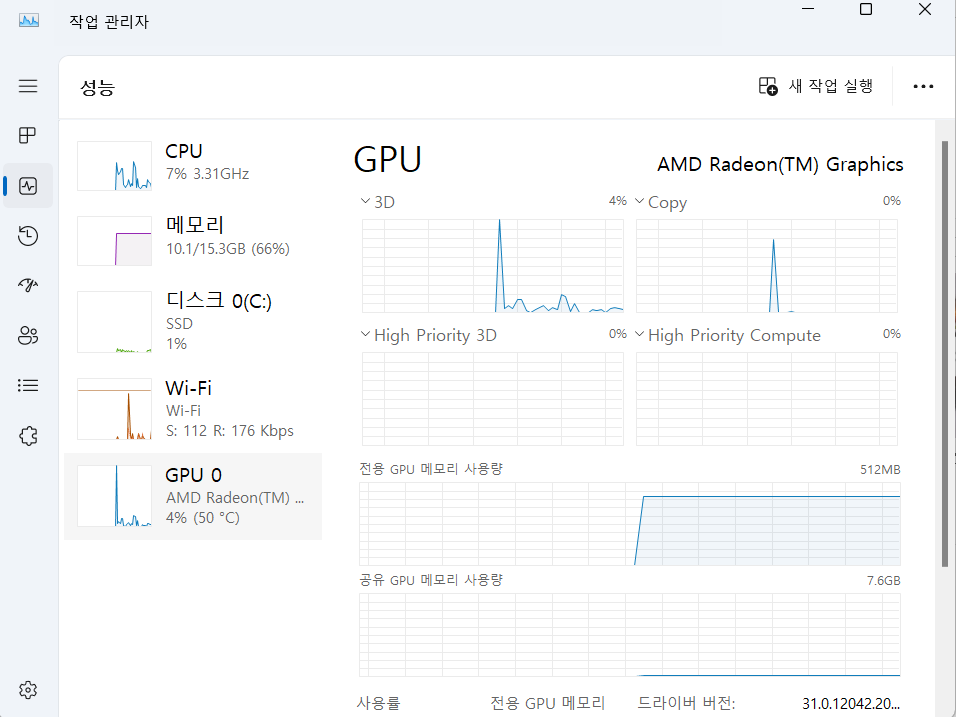
🔍 Ollama 서버를 로컬에서만 돌리면 한계가 있다?
Windows에서는 작업관리자를 활용해 GPU 사용량을 모니터링할 수 있다.
하지만 이건 어디까지나 로컬 환경에서만 실행되는 Ollama 모델을 모니터링하는 방법이다.
🤔 그럼 다른 사람들이 이 모델을 활용할 수 있도록 하려면?
1️⃣ ngrok을 이용해 터널링하여 외부에서 접근 가능하게 만들기
2️⃣ 배포 환경을 구축하여 LangServe에 올려 API 제공하기
로컬에서만 실행하면 본인만 사용할 수 있지만, 서버에 배포하면 다른 사용자들도 API를 통해 접근할 수 있다.
✅ 마무리: Ollama를 활용한 RAG 구축 완료
이제 Ollama를 LangChain과 연동하여 LLM 기반 검색 + 응답 생성 시스템(RAG)을 구현할 준비가 되었다..
🔹 최종 구현 흐름
- Ollama 설치 및 GGUF 모델 다운로드
- Modelfile 작성 및 모델 생성
- FastAPI를 활용한 API 배포
- LangChain + ChromaDB 연동하여 RAG 구축
🔗 참고 자료 & 출처
🎥 영상 참고
🛠️ 설치 및 개념 참고
🚀 Ollama + RAG 관련 자료
