1. 개발기록
- 현재 개발은 AIhub에서 제공하고있는 [농산물 품질(QC) 이미지] 데이터를 사용하고 있다.

파일명이 '품목-품종-등급' 으로 되어있어서
어제 작성을 완료한 코드에서는 카테고리를 '품목-품종'으로 해서 라벨링 작업을 했다.
샘플 데이터를 가지고 했는데도 이미지가 많아서 약 3천장을 학습시켜야 했다.
일단 하이퍼 파라미터 값은 기본 설정 값으로 주고 모델은 ReNet18을 사용해서 학습시켰다.
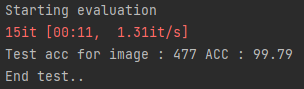
하이퍼 파라미터를 바꾸지 않아도 학습결과가 99.79가 나왔다.
데이터가 너무 좋아서 그런 것 같다.
농산물 품질을 확인할 수 있어야하기 때문에 등급도 라벨에 추가 해서 다시 학습해야 할 것 같다.
강사님께서 linear regression으로 메타정보를 학습시킬 수 있다고 하는데..
이 부분은 라벨학습까지 해보고 좀 더 찾아보고 진행해야 겠다.
- 오전에는 학습을 돌리는데 거의 모든 시간을 다 써서,
오후에는 코드를 라이브러리화, 모듈화해서 수정하고 학습까지 돌릴 수 있으면 다시 돌려볼 예정.
2. 코드기록
- 원래 라벨은 '품목-품종'으로 나누니까 18개의 라벨로 나왔었는데,
AIhub에서 제공하는 pdf로 데이터 포맷을 확인해보니 54개의 라벨이 나온다..
일단은 해보기로 했다.

- 데이터를 폴더별로 정리하는 부분이 조금 이상하게 진행되어서 왜 그런가 했더니 파일이름이
png와 json이 같은 파일도 있고, 아닌 파일도 있어서 이런건 수작업을 했어야 했다.
json에 있는 부분을 가져와서 라벨링을 해보려고 했으나 이런 부분 때문에 과감하게 json을 제외.
이미지 데이터에있는 이미지 데이터 이름을 가지고 라벨링해서 학습하기로 했다.

- 현재 파일을 train, models, data_split으로 나눴는데 이 부분을 정리해야할 것 같다.

