학습 정리
Competition이란?
- 구성요소
- Problem
- 대회의 목표이자 참가자가 해결해야하는 과제를 말한다.
- Data
- Problem과 관련된 데이터 셋
- Competitors
- 대회에 참여한 사람들
- Problem
- Competition하면 좋은 이유
- 데이터와 함께 목표가 제공되어서 좋은 경험을 할 수 있다.
- 해당 대회가 열리게 된 배경이 존재한다. 이 배경을 통해서 문제 해결의 필요성과 의미를 이해할 수 있고, 때로는 문제 해결에 도움이될 수 있다.
- 참가자들 함께 문제 해결 능력을 기를 수 있다.
- 다양한 사람들이 함께하기때문에 본인이 생각하지 못했던 여러 방향에서 문제를 바라볼 수 있다.
문제 정의
- 대회에서 제시하는 문제를 보다 명확하게 파악하고 정의해야 한다.
- 이러한 문제 정의는 질문을 던지는 것부터 시작한다.
- 데이터가 어떻게 만들어진 것인지?
- 데이터가 일정한 형식을 가지고 있는지?
- 특별한 목적이나 환경에서 적용되는 것인지? 등등
- 현재 문제가 처한 상황을 인지 (문제의 배경)
- 현재 나의 상황과 환경을 인지 (아는 지식, 경험, 활용가능한 자원 등)
- 데이터의 종류와 특수성을 확인하고 발생가능한 다양한 상황을 가정
- 데이터를 원하는 형태로 추론하기 위해서 적절한 방법을 적용
- 해당 결과가 올바른지 평가하기 위한 방식을 생각한다.
Competition에 참가했는데 나보다 잘하는 사람을 만난다면 그것은 운이 좋은 것이다!!!
그 사람의 모든 것을 흡수한다는 마음가짐으로..
Image에 대해서
- 해상도 (Resolution)
- 이미지의 가로 세로 픽셀 개수를 이야기한다.
- 당연하게 픽셀 수가 높을 수록 높은 해상도를 가진다.
- 픽셀 (Pixels)
- 이미지의 가장 작은 단위를 말한다.
- 하나의 픽셀은 채널 수 만큼 색상 성분을 지닌다. RGB 색공간이라면 [255, 255, 255]
- 1920 x 1080 해상도는 2,073,600개의 픽셀을 가진다.
- 채널 (Channels)
- 색상을 나타내는 성분 수에 따라서 결정된다.
- 일반적으로 RGB의 3개의 채널을 사용하지만 경우에 따라 다르다.
- 1 channel
- Grayscale
- 3 channels
- RGB
- HSV
- LAB
- YCbCr 등등
- 4 channels
- RGBA (투명도 포함)
- CMYK (인쇄시에 많이 사용) 등등
EDA (Exploratory Data Analysis)
- 데이터를 탐구하면서 분석하는 것
- 예시
- 이미지의 기본 정보 확인
- 차원, 채널, 이미지 사이즈, 파일 확장자 등등
- Label이 있는 경우
- 클래스의 분포와 클래스간의 불균형이 존재하지 않는지 확인
- 이미지 샘플 확인
- 이미지를 확인해보면 몰랐던 사실을 알게되는 경우가 많다.
- 중복된 이미지 제거
- 해시 함수를 활용하면 똑같은 이미지를 쉽게 찾을 수 있다.
- 이미지의 기본 정보 확인
모든 데이터가 완벽하게 정리되어있다는 것은 말도 안되는 소리이다.
그렇기 때문에 데이터를 입맛대로 다룰 수 있어야하고, 이러한 데이터를 다루는 것이 문제 해결의 시작이자 실마리가 될 수 있다!!
Image Processing
- 이미지 전처리는 CV pipeline에서 중요한 단계를 맡고있다.
- 모델 성능과 일반화에 직접적인 영향을 미친다.
- 의미있는 feature과 representation을 추출하는데 큰 도움이 된다.
Color Space 변경
- 색공간이란 색을 디지털적으로 표현하고 해석하기 위해 정의된 수학적 모델을 말한다.
- RGB
- Red, Green, Blue
- 가장 많이 사용되는 빛의 삼원색
- HSV
- Hue(색상), Saturation(채도), Value(명도)
- 색을 가장 직관적으로 인식할 수 있도록 한다.
- Lab
- L(Lightness), a(Green-Red), b(Blue-Yellow)
- 색의 일관성을 유지, 각기 다른 장치와의 일관성 유지
- YCbCr
- Y(Luma), Cb(Blue-difference), Cr(Red-difference)
- 비디오 시스템, 비디오 압축, 디지털 방송에서 자주 사용된다.
- Grayscale
- 밝기
- 컬러정보가 필요하지 않는 명암 대비, 텍스처 분석
- OpenCV를 이용해서 색공간을 변경할 수 있다.
cv2.cvtColor(img, cv2.COLOR_BGR2RGB)- BGR -> RGB로 변경
- Hisogram Smotthing
- 이미지의 히스토그램을 평활화 (Equalize)
- Contrast를 개선하고 디테일을 잘보이게 해준다.
- 밝기가 좋지 않은 이미지를 개선하는데 도움이 된다.
cv2.equalizeHist(img_gray)
Geometric Transform
-
image를 변형하는데 사용되는 다양한 수학적 기법을 의미한다.
-
Translation, rotation, scaling, shearing, perspective 등등
-
CNN은 Fully Convolutional이며, 입력 이미지의 크기에 상관없이 처리 가능하다.
-
하지만 입력 이미지의 크기는 출력되는 Feature map에 영향을 준다.
-
CNN은 학습을 하면서 Feature 크기의 패턴을 찾는 방법을 학습하지만, 입력 이미지의 크기가 변경되면 학습된 패턴의 크기 또한 변경된다.
-
그렇기 때문에 CNN을 학습시키면서 다양한 패턴을 학습한 Kernel을 만들 수 있도록 Geometric Transform을 이용하여 다양성을 부여하는 것이다.
-
Translation
- 위치 이동
-
Rotation
- 각도 만큼 이미지 회전
-
Scaling(resize)
- 이미지 크기 조정
cv2.resize
- 크기가 늘어난 후에 새로운 위치는 interpolation 진행
- 이미지 크기 조정
-
Perspective Transformation
- 원근 변환 적용
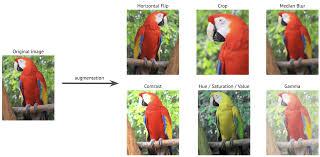
Data Augmentation
- robust한 모델을 형성하는데 도움이 된다.
- 과적합 감소
- 학습 데이터의 다양성이 증가한다.
- 예시
- Flips(horizontal, vertical)
- Rotations
- Crops (random, center)
- Color jittering 등등

- 다양한 라이브러리
- Albumentation
- Torchvision
- Imgaug
- 유용한 기술
- AutoAugment
- 데이터셋에 맞춘 최적의 augmentation 정책을 탐색해준다.
- RandAugment
- 랜덤한 크기로 augmentation의 하위 집합을 무작위로 적용한다.
- AutoAugment
Normalization
Min-Max Normalization
- 이미지 데이터를 [0, 1] 범위로 스케일링 한다.
- 딥러닝 모델의 수렴 속도와 안정성을 증가시킨다.
- 큰 비중을 가진 특징이 학습 과정에서 편향을 만드는 것을 방지해준다.
- 모델이 더 의미 있는 Representation을 학습하는데 도움을 준다.
torchvision.transforms.ToTensor()- albumentation의
ToTensorV2()는 단수한게 Tensor로 변경만 해준다.
Z-Score Normalization (Standardization)
- 평균을 빼고 표준편차를 나눈다.
- 모델이 더 빨리 학습하고 이상치의 영향을 줄이는데 도움을 준다.
torchvision.transforms.Nomalize()
Batch Normalization
- mini batch 단위로 입력 데이터를 정규화 한다.
- 학습시 파라미터가 업데이트 되면서 입력 분포가 변화하는 Internal covariate shift 문제를 개선하였다.
- Normalize로 인해 더 높은 lr을 허용한다.
- 초기값 설정에 대한 민감도가 감소하였따.
- 학습 시 mini-batch에 대한 통계치를 기록하였다가 추론시에 해당 값을 이용하여 Normalize한다.
Image Classification
- 이미지 데이터가 내포하는 의미에 대해 사전 정의된 클래스로 할당하는 task이다.
- 이미지에서 내포하는 의미들이 굉장히 다양하지만 어떠한 것을 기준으로 하느냐에 따라서 분류가 달라질 수 있다.
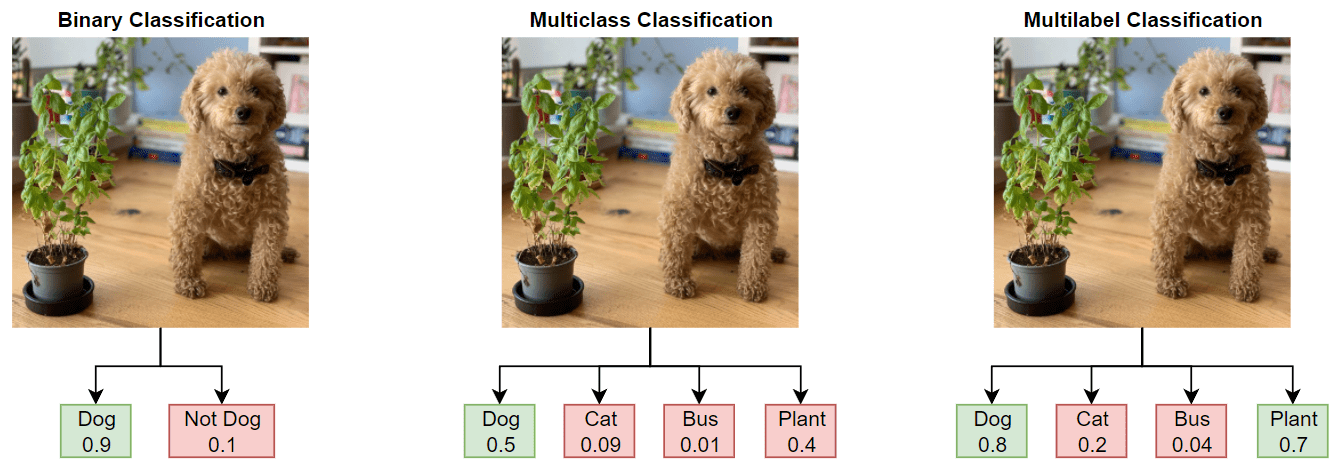
Binary Classification
- 데이터를 두개의 클래스 중 하나로 분류하는 작업
- sigmoid 함수 사용
Multi-class Classification
- 데이터를 여러 개의 클래스 중 하나로 분류하는 작업
- Softmax 함수 사용
Multi-label Classification
- 데이터가 여러 개의 클래스로 동시에 분류될 수 잇는 문제
- 예측할 각각의 클래스마다 Binary Classification을 진행한다.
- sigmoid 사용
Coarse-grained Classification
- 상대적으로 큰 범주로 객체를 분류한다,
- 클래스 간 연관성이 별로 없는 편이다.
- 사과 vs 고양이 vs 우주선
Fine-grained Classification
- 동일한 상위 범주 내에서 세부적인 하위 범주로 분류한다.
- 같은 종내에서 분류하기 때문에 다른 클래스라도 비슷한 점이 존재한다.
- '자동차'라는 상위 범주 내에서 차의 종류를 분류하는 것
Model
- 모델은 일반적으로 객체, 사람 또는 시스템에 대한 표현 방법을 학습한다.
- 복잡한 현상을 단순화하여 이해하거나 예측할 수 있다.
Inductive Bias (귀납적 편향)
- 모델이 학습 과정에서 특정 유형의 패턴을 잘 학습하도록 하는 사전 지식을 의미한다.
- 모델이 어떤 과점에서 데이터를 바라보려고 하는 것인지를 설명하는 것이다.
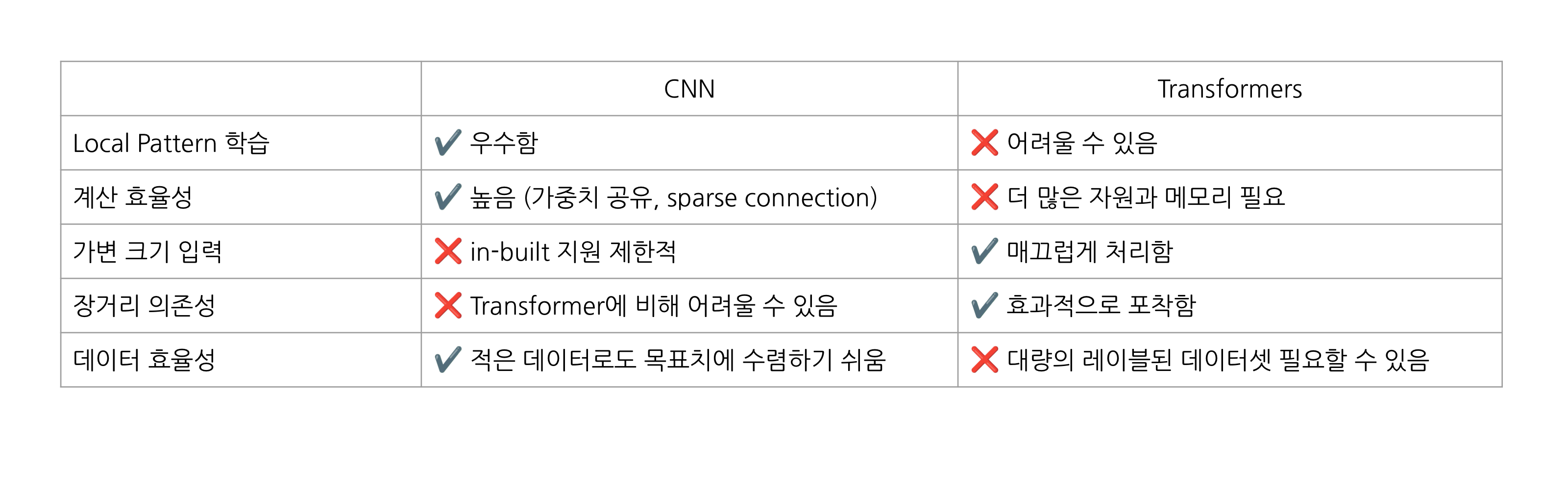
- CNN
- Locality & Translation Invariance
- 이미지에서 지역적인 패턴에 집중하며, 위치와 상관없이 동일한 패턴을 인식한다.
- Hierarchical Feature Learning
- 저수준의 단순 특징을 먼저 학습한 후에 고수준의 복잡한 특징을 학습하는 계층적 구조를 활용한다.
- Weight Shring
- 동일한 커널을 이미지 전체에 사용하기때문에, 파라미터 수를 줄이고 학습의 효율을 높인다.
- Locality & Translation Invariance
- Transformers
- Long-Range Dependencies
- 입력 간의 먼 거리 관계를 효과적으로 포착하여, 문장 내에서 멀리 떨어진 단어들 간의 상호작용을 처리한다.
- Flexible Input Handling
- 고정된 크기가 아닌 다양한 크기의 입력을 처리할 수 있다.
- Self-Attention
- 각 입력의 중요도를 동적으로 계산하기 때문에, 더 중요한 부분에 높은 가중치를 부여한다.
- Long-Range Dependencies
주어진 데이터를 사용하여 문제의 해결에 가장 걸맞는 표현을 낼 수 있는 모델을 가정
- 데이터의 종류에 따라 모델이 결정되는 것이 아니라, 모델의 Inductive Bias를 고려하여 모델을 선택한다.
ConvNeXt
- 최신 CNN Architecture
- ViT가 성능이 좋기로 유명하지만 CNN도 여러 장점으로 인해 여전히 많이 사용되어지고 있다.
- CNN 계열의 모델 디자인을 재설계하여 성능을 높이고자 만든 모델이다.
- 표준 ConvNet의 단순성과 효율성을 유지한다.
- ImageNet에서 SOTA 결과를 달성하였다.
- Depthwise Convolution
- 채널 별로 독립적인 필터를 사용하는 방식이다.
- Inverted Bottleneck
- 처음에 채널 수를 확장하고 핵심 연산 진행 후에 채널 수를 축소시켜 결과를 출력하는 방식이다.
- Bigger Kernel Size
- 더 적은 Activation Function과 Layer Normalization
CNN vs Transformer
Representation
- 데이터를 모델이 어떤 관점에 따라 이해하고 처리할 수 있는 형태로 변환되는 것을 의미한다.
- 같은 이미지라도 어떤 개체가 가질 수 있는 의미는 매우 다양하다.
- 그렇기 때문에 어떤 개체를 표현하는 Representation 또한 다양할 수 있다.
Representation Learning
- 데이터로부터 유의미한 Representation을 자동적으로 학습할 수 있도록 하는 것이다.
- 데이터를 이해하고 중요한 특징을 자동으로 추출하는 것이 목표이다.
- 또한 이러한 Representation은 데이터의 core infomation을 압축하고, 다양한 작업에 응용할 수 있도록 할 수 있다.
- 계기
- 단 하나의 의미만은 가지는 개체는 존재하기 힘들다.
- 같은 이미지라도 해석하는 과점과 관심있게 보는 영역에 따라서 의미가 매우 다양하다.
- 그러므로 어떤 개체를 표현하는 Representation도 다양하다.
- 사람이 설계를 직접 설계를 하게되면 어쩔 수 없이 설계하는 사람이 집중하는 부분에 대해서 학습이 진행될 수 있기 때문에 Representation Learing에 대해서 해당 부분을 극복한다고 이해함.
- Supervised Learning의 한계
- 모든 Task에 대해서 Annotation 작업을 진행하는 것은 Cost가 크다.
- 적은 Annotation으로 학습할 수 있는 모델이 비용적 측면에서 가치가 높다.
- 단 하나의 의미만은 가지는 개체는 존재하기 힘들다.
- 특징
- Feature Extraction
- Raw 데이터에서 중요한 특징을 식별하고 인코딩하는 것
- Generalization
- 보편적인 패턴을 포착하여 보지 못한 데이터에서도 일정 수준의 수행능력을 보이는 것
- Data Efficiency
- 효과적인 특징 학습을 통해 대규모 주석 데이터 셋의 필요성을 줄인다.
- Feature Extraction
Transfer Learning
- 한 도메인에서 pre-trained model을 other domain에 적용하는 것이다.
- 적은 데이터로 더 빠른 학습과 성능 향상을 노려볼 수 있다.
- 특히 Target data가 적을 때 유용하다.
- 방법
- pre-trained model을 적용시키고자 하는 domain에서 가중치를 freeze시키고, classifier만 학습시킨다.
- pre-trained model을 적용시키고자 하는 domain에서 전체 모델을 fine-tuning 한다.
- pre-trained model을 적용시키고자 하는 domain에서 학습 시키고자 하는 layer외에는 가중치를 freeze시키고 학습을 진행한다.
Self-Supervised Learning
- Label이 없는 데이터에서 Representation을 학습한다.
- 데이터 자체에서 Supervision Task를 생성하여 진행한다.
- 훨씬 더 큰 데이터 세트에서 학습할 수 있음
- label이 필요없기 때문에 훨씬 큰 데이터 셋에서도 학습이 가능하다는 의미로 이해하였다.
- 작은 데이터 셋에서도 동작하겠지만, 데이터 셋의 크기가 클수록 학습에 유리해보인다.
- 모델이 더 많은 패턴과 구조를 학습할 수 있기때문이다.
- General-purpose visual feature을 생성한다.
- 다양한 비전 작업에서 유용하게 사용될 수 있는 일반적인 시각적 특징
pretext task
main task를 학습하기 전에 모델이 스스로 유용한 Representation을 학습할 수 있도록 설계된 가상의 학습 과제이다. 이를 통해서 모델이 데이터의 구조를 더 잘 이해하고, main task를 더 쉽게 해결할 수 있도록 돕는다.
How? pretext task를 통해서 학습한 Representation은 Main Task에 전이되어 사용된다. 또한 이 과정을 통해서 모델은 더 나은 초기 가중치를 얻는다.
즉, 모델의 중간목표이다.
- Colorization (색 복원)
- Inpainting (패치 예측)
- Jigsaw puzzle solving (조각난 이미지의 순서 맞추기)
- Prediction relative position (조각난 이미지의 위치 예측)
- Roation Prediction (회전된 각도 예측)
- Contrastive Learning
- Positive pairs
- 같은 이미지의 Augmented 버전
- 그 외 비슷하다 생각할 수 있는 Data
- Negative pairs
- 다른 이미지의 Augmented 버전
- 그 외 다르다고 생각할 수 있는 Data
- Contrastive loss는 positives를 모으고 negatives를 밀어냄
- Positive pairs
Multimodal Learning
- 여러가지 modality에서 정보 결합
- 일반적으로 사용되는 modality : 비전, 언어, 오디오 등등
- 어떤 Image가 의미하는 바를 Image의 특성으로부터 확인할 수 있지만, 다른 Modal로부터 얻을 수도 있다.
- Image의 특성만으로는 찾기 어려운, 복잡하면서 넓은 의미의 영역까지 확장 가능하다.
뒤에는 Training과 Evaluation 과정에 대한 것이 있지만 코드 설명이 대부분인 관계로 프로젝트를 진행하면서 이해하고 추가 작성하도록 하겠음!
