학습 내용
Activation Function
- 활성화 함수는 이전 층의 결과값을 변환하여 다른 층의 뉴런으로 신호를 전달하는 역할을 한다.
- 활성화 함수가 필요한 이유는 모델의 복잡도를 올리기 위함인데 비선형 문제를 해결하는데 중요한 역할을 한다.
- 비선형 문제를 해결하기 위해 단층 퍼셉트론을 쌓는 방법을 이용했는데 은닉층을 무작정 쌓기만 한다고 해서 비선형 문제를 해결할 수 있는 것은 아니다.
- 활성 함수를 사용하면 입력값에 대한 출력값이 비선형적으로 나오므로 선형분류기를 비선형분류기로 만들 수 있다. -> 활성 함수로 비선형 함수를 사용해야하는 이유이다.
Sigmoid Function
- 출력값의 범위가 0 ~ 1 사이의 값이다.
- Logistic Regression에서 활성화 함수로 사용된다.
- 몇가지 단점이 존재한다.
- Vanishing Gradient : 입력값이 크거나 작으면 기울기가 0에 수렴한다. 따라서, 가중치가 갱신이 되지않으므로 학습이 중단되게 된다.
- non-zero-centered : 입력값이 모두 양수라면 출력값 또한 모두 양수이기 때문에 모든 가중치에 대한 upstream 기울기가 항상 양수 또는 음수가 되어 학습이 원활하게 이루어지지 않는다. 그렇기 때문에 지그재그 형태로 업데이트가 이루어지면서 비효율적으로 학습이 이루어진다.
- exp() 연산의 cost가 높다.
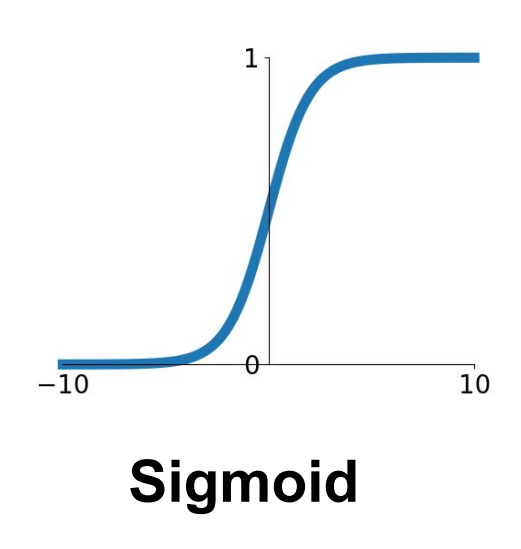
Tanh Function
- 하이퍼블릭 탄젠트 함수라고 한다.
- 출력값의 범위가 -1 ~ 1 사이의 값이다.
- Sigmoid 함수값의 중심을 0으로 맞추기 위해 개선된 함수이다.
- 양수와 음수가 나오는 비중이 비슷하므로 zigzag 현상이 상대적으로 덜하지만, 여전히 존재는 한다.
- Vanishing Gradient 문제가 여전히 발생한다.
- exp() 연산의 cost가 높다.
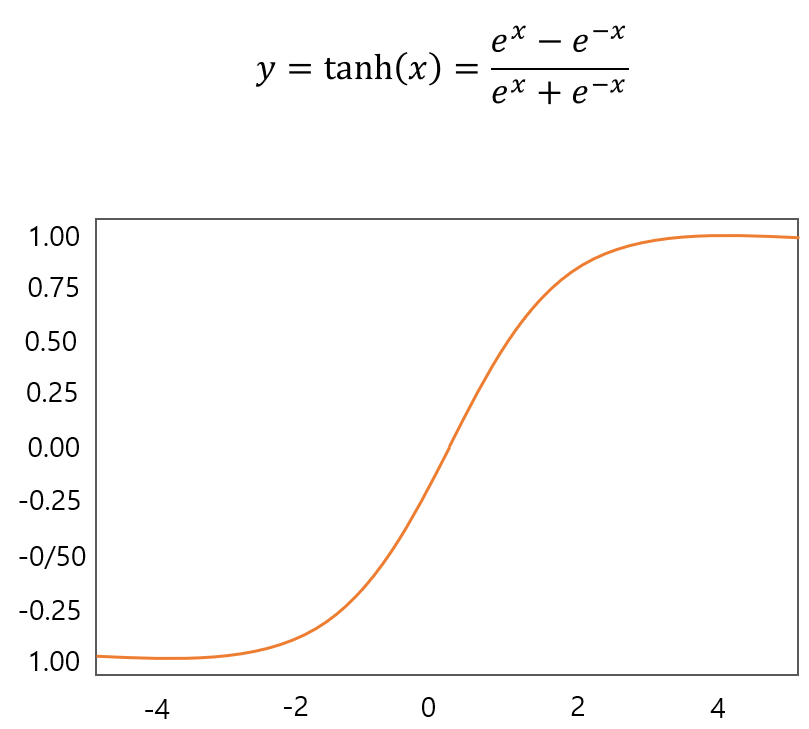
ReLU Function
- Sigmoid, Tanh Function에서 나타나는 Vanishing Gradient 문제를 일부 해결한 Activation Function이다.
- 양수 영역에서는 Saturation되지 않는다.
- Saturation : 특정 구간에서 출력 값이 거의 변화하지 않는 포화 상태를 의미한다. -> 값의 변화가 없다면 기울기가 0에 가깝다는 것을 의미한다.
- Sigmoid, Tanh Function과 같은 함수보다 약 6배 빠르게 수렴한다.
- 연산이 효율적이다.
- 몇가지 단점이 존재한다.
- 출력 값이 zero-centered하지 않는다.
- Dead ReLU Problem : 출력 값이 음수라면 saturated 되는 문제가 발생한다.
- x = 0일때 미분 불가능하다.
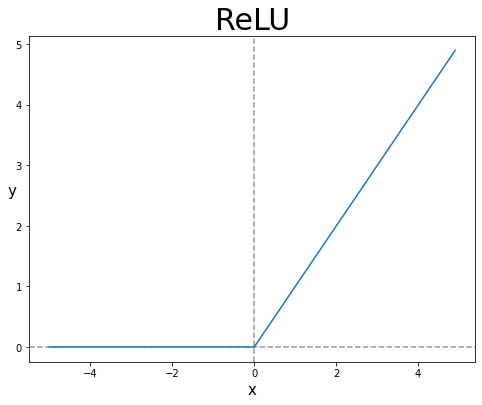
Leaky ReLU
- ReLU의 Dead ReLU Problem 문제를 해결하기 위해서 음수일 때 약간의 기울기를 적용하여 주는 방식을 사용한다.
- 모든 영역에서 Saturate 하지 않는다.
- 연산에 효율적이다.
- Sigmoid, Tanh Function보다 빠르게 수렴한다.
- No Dead ReLU Problem -> Vanishing Gradient 문제를 해결
- 단점으로는 x가 0 미만일 때 적용해줄 기울기를 추가적인 하이퍼파라미터로 설정해야 한다.
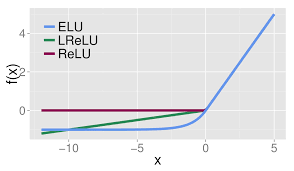
ELU (Exponential Linear Unit)
- ReLU의 모든 장점을 가지고 있다.
- Leaky ReLU에 비해서 음수지역에 견고성을 더한다.
- 출력 값이 거의 zero-centered하다.
- exp()연산이 비싸다. -> 비싼 이유는 미분할때 복잡하기 때문이다.
Weight Initialization
Small Gaussian Random Initialization
- 가중치를 평균이 0이고, 작은 표준편차를 가진 가우시안(정규) 분포에서 무작위로 초기화하는 방법이다.
- 얕은 신경망에서는 좋은 결과를 내며 널리 사용된다.
- 초기 단계에서 출력값을 크게 바꾸지 않도록 하여 학습을 안정적으로 시작할 수 있다.
- 단점
- 입력이 0에 가까우면 모든 기울기가 0에 가까워져 신경망이 비활성화 되거나, 학습이 느리게 진행될 수 있다.
- 신경망이 깊은 경우에는 Vanishing Gradient 문제가 발생할 수 있다.
Large Gaussian Random Initialization
- 가중치를 평균이 0이고, 큰 표준편차를 가진 가우시안(정규) 분포에서 무작위로 초기화하는 방법이다.
- 초기 단계에서 출력값을 크게 변하게 하여 학습이 빠르게 진행될 수 있도록 한다.
- 단점
- 의 값이 1에 가까우면, 모든 기울기가 0에 가까워져 학습이 되지 않는다.
- 신경망이 깊은 경우에는 극단값으로 밀려나게 된다.
- 가중치가 너무 큰 경우에는 기울기 폭발의 위험이 있다.
- 의 값이 1에 가까우면, 모든 기울기가 0에 가까워져 학습이 되지 않는다.
Xavier Initialization
- 가중치를 특정 분포에서 초기화하는 방법으로, 신경망의 각 층에 따라 입력 뉴런 수와 출력 뉴런 수에 기반해 가중치를 설정한다.
- 시그모이드 계열의 활성화 함수를 사용할 때 자주 사용된다.
- ReLU 함수 사용시에는 출력값이 0으로 수렴하는 현상이 발생한다.
- Xavier Normal Initialization
- 표준편차를 으로 가진 가우시안 분포에서 무작위로 초기화한다.
- Xavier Uniform Initialization
- 최솟값 , 최댓값 의 범위내에서 균등하게 가중치를 초기화한다. (연속균등분포)

기동코딩