
program 설치
1. miniconda3 설치
2. visual studio code 설치
3. Analysis Seoul CCTV
Jupyter & VSCode
1. ~ 3. 데이터 읽기
목표
- 인구수 대비 CCTV 설치 현황 시각화
- CCTV 데이터 및 인구현황 데이터 확보- 데이터 정리 및 정렬 후 그래프 도출
anaconda prompt를 이용해 jupyter notebook 실행
기본 조작
- python과 마찬가지로 import '모듈명'을 이용해 모듈을 불러오고 as 키워드로 축약가능
- 명령어
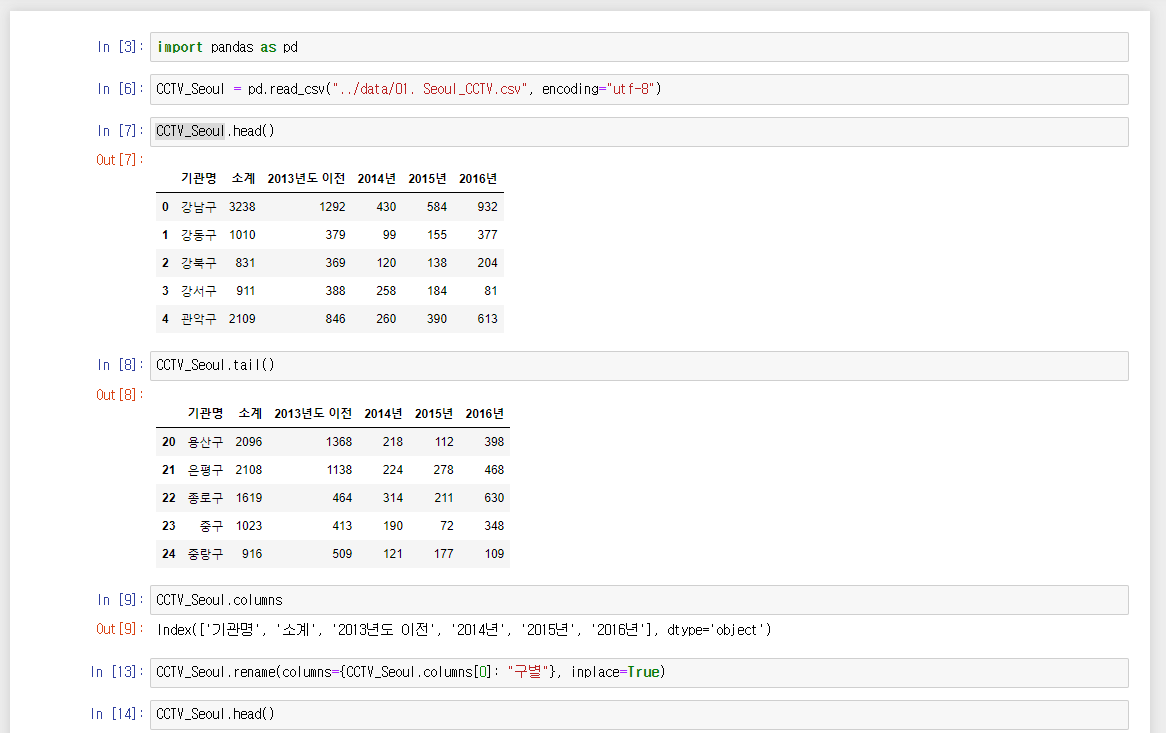
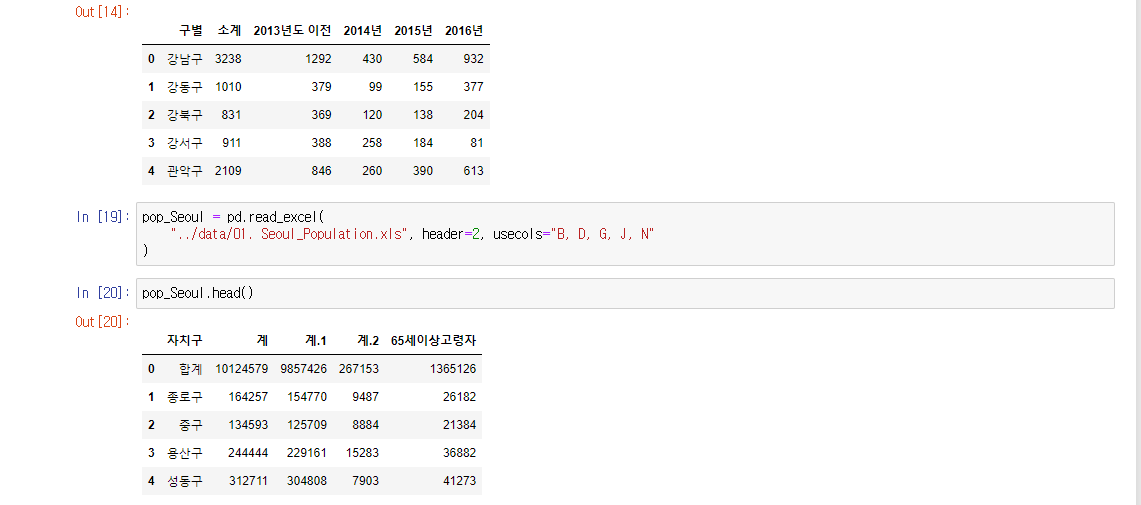
- head() 상단의 5개 데이터를 출력- tail() 하단의 5개 데이터를 출력
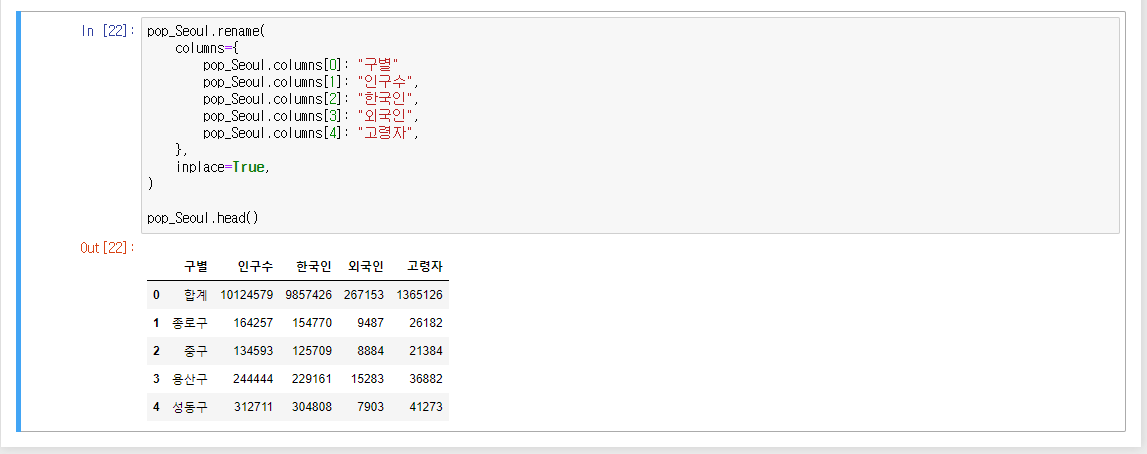
- inplace=True columns 변경을 하위에도 적용
- 사용을 모르는 경우 pandas read_excel(csv) documentation을 구글에 검색하여 찾기
4. ~ 6. Pandas 기초
- pandas는 통상적으로 pd라고 import
- 수치해석적 함수가 많은 numpy는 통상 np로 import
- pandas의 데이터형을 구성하는 기본은 Series이다.
- 날짜(시간)를 이용할 수 있다.
- pandas에서 가장 많이 사용되는 데이터 형은 DataFrame이며, index와 columns를 지정하면 됨.
- 명령어
- df.index - 인덱스 확인- df.columns - 컬럼 확인
- df.Values - 밸류 확인
- df.info - 데이터프레임의 기본정보 확인(데이터 크기 및 형태 확인.)
- df.describe 데이터프레임의 통계적 기본정보를 확인
- df.sort_values(by="columns/index)" - 데이터를 정렬
- df["컬럼명"] - 특정 컬럼만 읽기
- df[시작:끝] - 시작부터 끝-1까지 데이터 슬라이스(인덱스 이름으로도 가능)
- df.loc[행시작:행끝, [열시작:열끝]]으로 슬라이스
- df.iloc - 인덱스 번호로 슬라이스
- etc..
- pandas 기초
- python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세서에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 누군가 스테로이드를 맞은 엑셀로 표현함
- Series는 index와 values로 이루어져 있으며, 한 가지 데이터 타입만 가질 수 있음.- date_range를 이용해 날짜데이터를 datetime64[ns]라는 타입으로 만들 수 있음.
7. ~ 11. 데이터 보기 및 합치기
- head()로 상위 5개의 value 확인 가능
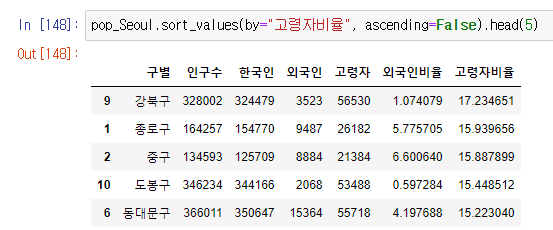
- tail()로 상위 5개의 value 확인 가능- sort_values(by="고령자비율", ascending=False)
- 데이터 프레임 정렬 가능
- by = "기준" 으로 정렬 기준 설정
- ascending True/False 로 오름차순/내림차순 정렬 가능
- drop 함수로 데이터 삭제 가능
- info로 데이터 정보 확인 가능
- corr로 상관계수 확인 가능

초심자 입니다!