1. 배경지식
- JPA에서 xToOne 조회 시 N+1 문제가 발생할 수 있으므로 fetch join을 사용한다.
- JPA에서 컬렉션(OneToMany)을 조회할 경우 관계 일 경우 fetch join 사용 시 오류가 발생할 수 있다.

이를 해결하기 위해 “지연로딩 + Batch 전략”을 사용
default_batch_fetch_size: 100 을 application.yml에 추가
2. 성능 최적화 전
@GetMapping("/api/likebeers/{id}")
public WrapperClass showLikeBeers(@PathVariable("id") Long userid){
User findUser = userService.findOne(userid); //1번 user 조회
List<LikeBeer> likeBeers = findUser.getLikeBeers();
List<Beer> beers = new ArrayList<>();
for (LikeBeer likeBeer : likeBeers) { //2번 likebeer 조회
beers.add(likeBeer.getBeer());
System.out.println("likeBeer.getBeer() = " + likeBeer.getBeer());
}
//3번 beer 조회
List<BeerDto> beerDtos = beers.stream().map(b -> new BeerDto(b)).collect(Collectors.toList());
return new WrapperClass(beerDtos); //api의 확장이 가능하도록 wrapper 클래스로 감싸서 리스트를 return
}1-1. User findUser = userService.findOne(userid) 에서 userid에 해당하는 user 조회 시 select 쿼리 발생
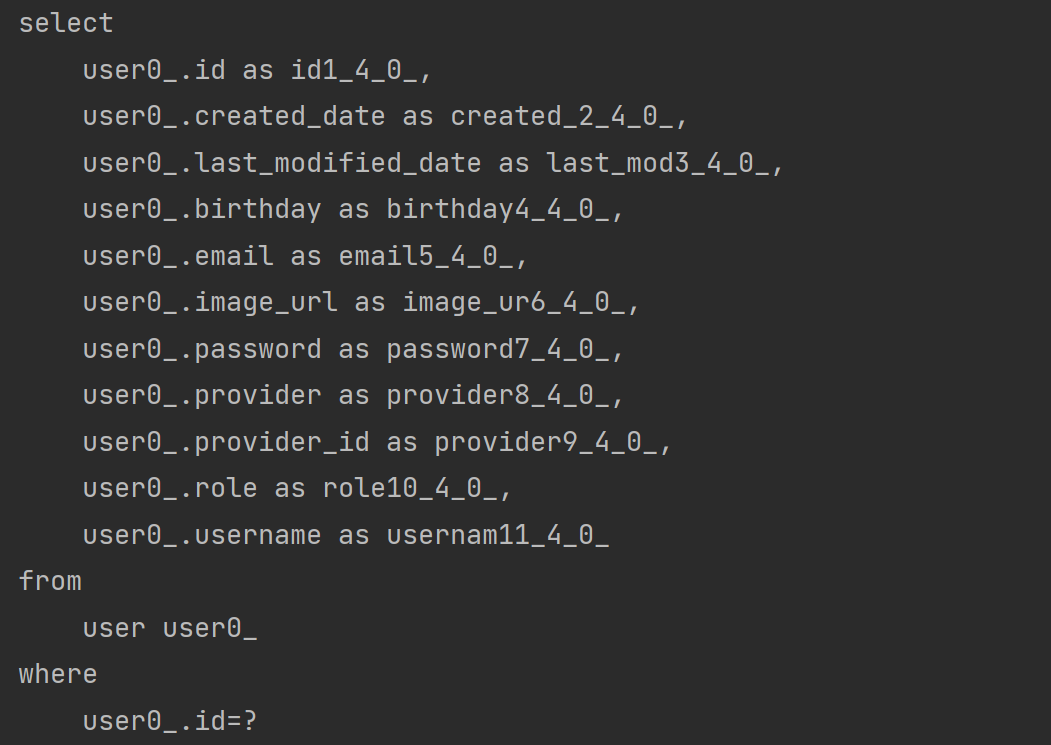
1-2. likeBeer.getBeer() 수행 시 likeBeer 조회 쿼리 발생
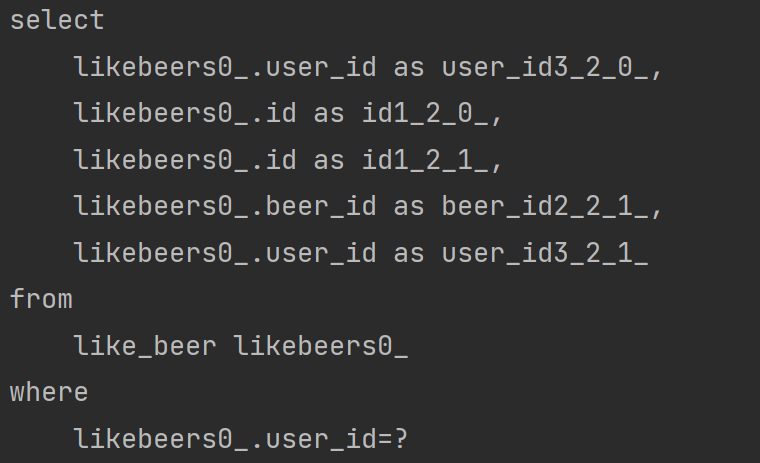
1-3. map(b -> new BeerDto(b) DTO로 변환 시 Beer 엔티티 값에 접근하므로 beer를 조회하는 쿼리가 likeBeer 수 만큼 발생(N+1문제!)
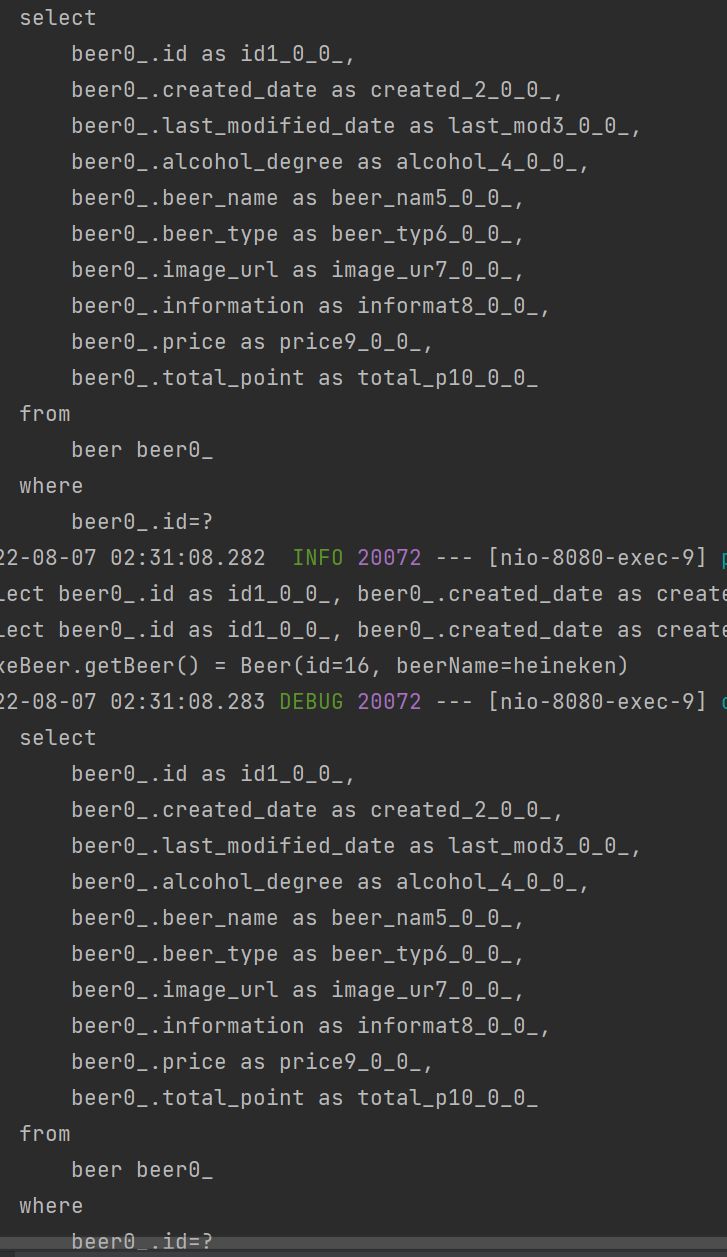
3. 성능 최적화 후(Fetch Join을 사용)
@GetMapping("/api/likebeers/{id}")
public WrapperClass showLikeBeers(@PathVariable("id") Long userid){
//fetch join 사용
List<LikeBeer> likeBeers = likeBeerService.findAllWithBeer(userid);
List<Beer> beers = new ArrayList<>();
for (LikeBeer likeBeer : likeBeers) {
beers.add(likeBeer.getBeer());
System.out.println("likeBeer.getBeer() = " + likeBeer.getBeer());
}
List<BeerDto> beerDtos = beers.stream().map(b -> new BeerDto(b)).collect(Collectors.toList());
return new WrapperClass(beerDtos); //api의 확장이 가능하도록 wrapper 클래스로 감싸서 리스트를 return
}likeBeer Repository 내 fetch join을 사용하는 SQL을 직접 DB에 날리는 모습
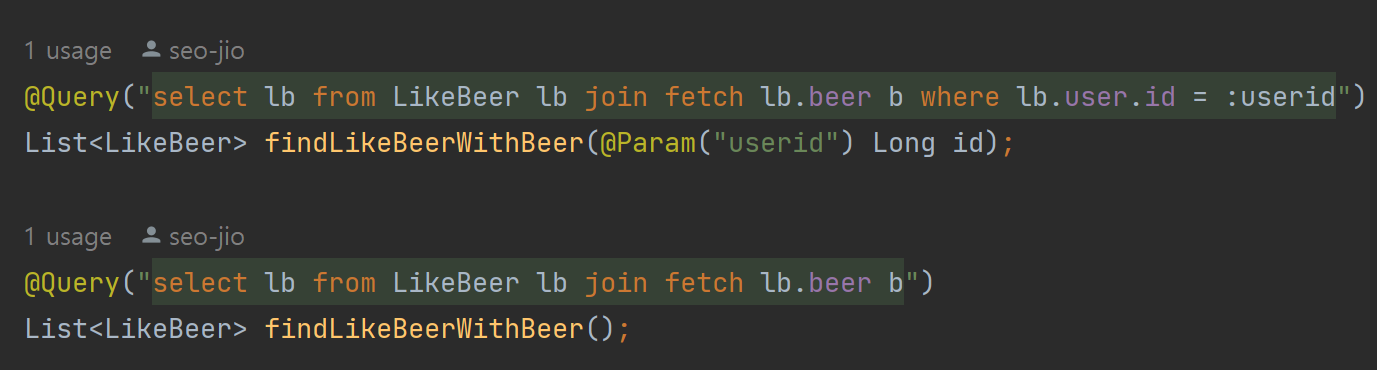
쿼리 결과
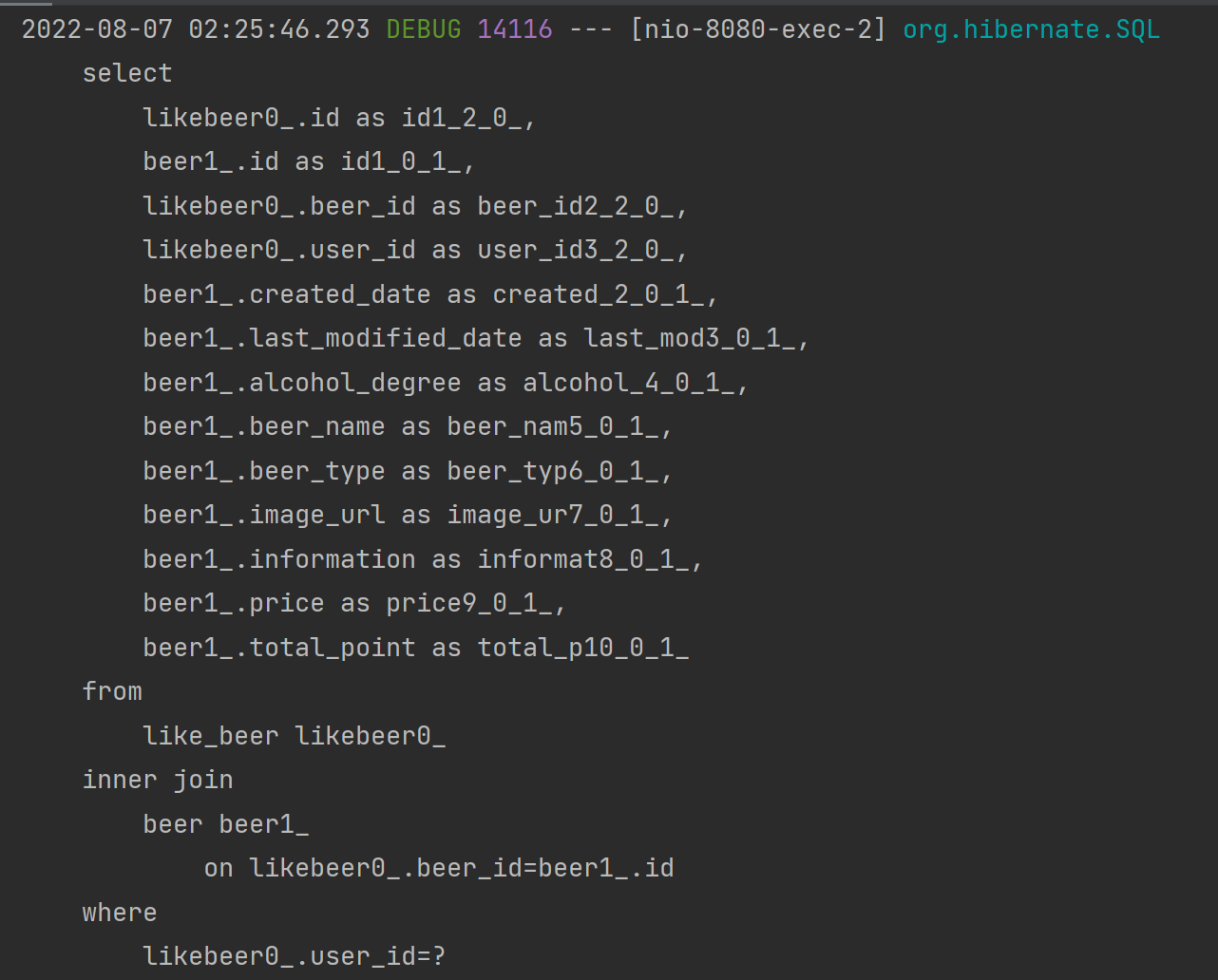
- fetch join을 사용하여 likeBeer를 조회할 때 ManyToOne 관계를 갖는 Beer 까지 한 번에 조회
- N+1 문제 해결(beer의 개수만큼 반복되는 beer 조회 쿼리를 하나로 줄일 수 있었다)
- 기존 userid를 받아 User를 다시 조회 하는 과정을 거쳤는데 쿼리문을 직접 작성하여 where 조건으로 유저와 매핑시켰다.(불필요했던 user 조회 쿼리 생략)
결론적으로 sql문을 대폭 줄일 수 있었다…!

백엔드 개발자를 꿈꾸는 학생입니다!