테이블 생성
--1. 테이블 생성
-- CREATE TABLE 테이블이름
-- 위가 기본 table 생성이다. 추가적으로 생성과 함께 조건을 주려면 아래 test를 참고하여 실행하자.
-- primary key는 기본키를 의미한다. nou null+unique를 의미한다.
-- test
create table test (num number(5) primary key, name varchar2(20),score number(6,2), birth date);
desc test; -- 구조보기
select * from test;insert(데이터 추가)
-- test에 전체데이터 insert
insert into test values(1,'손석구',67.2,'1993-11-13');
-- test에 일부 데이터 insert
insert into test (num,name) values (2,'강호동');
--insert 에러
--무결성 제약조건 ( ~~~~) 에 위배
--insert into test valuse(2,'이영애',68.23,'1987-12-13');
insert into test values(4,'이영애',68.23,'1987-12-13');
-- sysdate 현재날짜 의미
insert into test values(5,'이효리',88.34,sysdate);alter(구조 변경, 수정)
--alter (구조변경-수정)
-- 나이를 저장할 컬럼 추가, 무조건 null로 추가된다.
-- ALTER TABLE 테이블명 ADD 추가할컬럼명 데이터타입;
alter table test add age number(5);
-- 주소를 저장할 컬럼을 추가하는데 초기값을 강남구라고 지정
alter table test add address varchar2(30) default '강남구';
-- 지정한 숫자를 넘어서 기입하면 오류 난다.
--insert into test values(4,'이영애',68.23,'1987-12-13','대한민국 서울시 ㅎㅎㅎ ㅓㅓㅓ 2324-231ㅓ2ㅑㅐㅓㅐ랴ㅓ래ㅑ저ㅑㅐㄷ러ㅐㅑ3ㅓㅐ2ㅓㅐㅓㅐ2ㅑㅓ래ㅓ래ㅑㅓ32');
-- 주소저장 컬럼을 30에서 50으로 바꿔보자.
-- ALTER TABLE 테이블명 MODIFY 컬럼명 데이터타입;
alter table test modify address varchar2(50);
-- age타입을 문자열 (10)으로 변경하고 초가값을 20으로 설정하기
--기존 null은 그대로 있고(전체 그대로 있고) 새로 insert하는것 부터 초기값 들어감
alter table test modify age varchar2(10) default '20';
insert into test(num,name) values (10,'강호동');
-- 컬럼명 변경
-- ALTER TABLE 테이블명 RENAME COLUMN OLD컬럼명 TO NEW컬럼명;
-- score ==> 점수 로 변경
alter table test rename column score to 점수;
alter table test rename column birth to birthday;
-- num의 오름차순 출력
select * from test order by num;
select * from test order by name;drop (삭제)
-- drop (삭제)
-- age라는 컬럼을 삭제
-- ALTER TABLE 테이블명 DROP COLUMN 삭제할컬럼명
alter table test drop column age;
alter table test drop column address;
-- 테이블 삭제
drop table test;sequence (시퀀스)
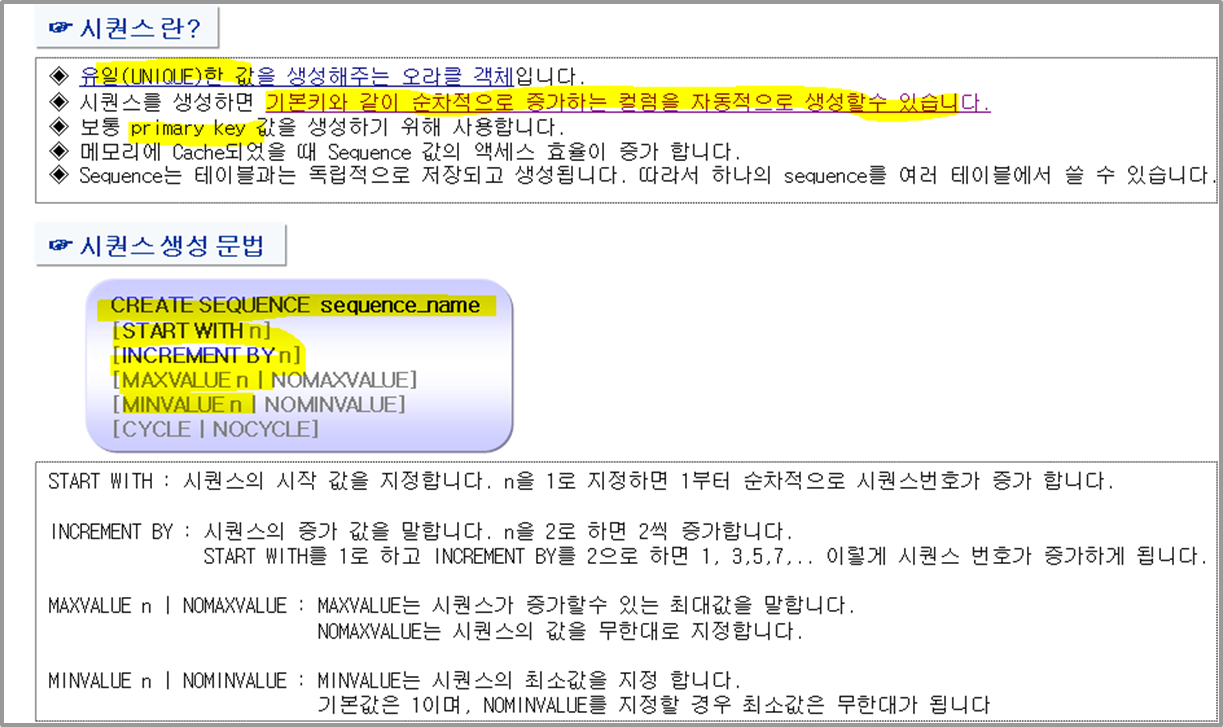
-- 시퀀스 생성
-- 시퀀스 기본으로 생성, 1부터 1씩 증가하는 시퀀스 생성됨.
create sequence seq1;
-- 전체시퀀스
select * from seq;
-- 다음 시퀀스값을 발생하여 콘솔에 출력하자
select seq1.nextval from dual;
-- 현재 마지막 발생한 시퀀스값
select seq1.currval from dual;
--seq1 삭제
drop sequence seq1;
-- 10부터 5씩 증가하는 시퀀스 만들기, cache값 없애기
create sequence seq2 start with 10 increment by 5 nocache;
select * from seq;
-- 시퀀스 발생
select seq2.nextval from dual;
select seq2.currval from dual;
drop sequence seq2;
-- sql1 : 시작값:5, 증가값:2, 끝값:30, 캐시:0, cycle:y
create sequence seq1 start with 5 increment by 2 maxvalue 30 nocache cycle;
-- sql2 : 시작값:1, 증가값:1, 캐시:n
create sequence seq2 nocache;
-- sql3 : 시작값:1, 증가값:2, 캐시:n
create sequence seq3 start with 1 increment by 2 nocache;
create sequence seq4 increment by 2 nocache;
-- 출력
select seq1.nextval,seq2.nextval,seq3.nextval from dual;
-- 전체삭제
drop sequence seq1;
drop sequence seq2;
drop sequence seq3;
drop sequence seq4;
--------------------------------- 시퀀스 1개생성, 테이블 생성
create sequence seq_start nocache;
create table personinfo (num number(5) primary key, name varchar2(20), job varchar2(30), gender varchar2(20), age number(5), hp varchar2(20), birthday date);
select * from personinfo;
desc personinfo;
-- birthday를 ipsaday 로 변경
alter table personinfo rename column birthday to ipsaday;
-- insert
insert into personinfo values (seq_start.nextval, '이성신','메붕이','남자',28,'010-3232-1212','2023-01-11');
insert into personinfo values (seq_start.nextval, '김태희','의사','여자',22,'010-2534-3424','1998-01-11');
insert into personinfo values (seq_start.nextval, '김민중','의사','남자',21,'010-3656-3654','2017-07-12');
insert into personinfo values (seq_start.nextval, '고라니','의사','여자',24,'010-2354-6457','2015-02-11');
insert into personinfo values (seq_start.nextval, '김나박이','백수','여자',24,'010-8892-6745','2022-02-11');
insert into personinfo values (seq_start.nextval, '이존망','백수','여자',27,'010-2342-5343','1999-05-21');
insert into personinfo values (seq_start.nextval, '이린생','메붕이','여자',31,'010-1313-2324','1993-11-13');
insert into personinfo values (seq_start.nextval, '최디알','백수','남자',42,'010-8765-4332','2000-11-11');
insert into personinfo values (seq_start.nextval, '김상식','메붕이','여자',23,'010-3827-1827','2012-12-11');
insert into personinfo values (seq_start.nextval, '박병','메붕이','남자',18,'010-2342-2623','2023-11-11');
commit; -- 최종저장.
-- 커밋을 해야 완료된다. 커밋 안하면 결과적으로 완료한게 아니다.
-- 인원확인
select count(*) from personinfo;
-- 조회 연습
select * from personinfo order by name asc;
select * from personinfo order by age desc;
select * from personinfo order by 5 asc; -- 컬럼 번호로도 가능.
select * from personinfo order by gender,age desc; -- 여기서 젠더는 asc로 들어갔다.
select * from personinfo order by gender,name;
select job from personinfo;
select distinct job from personinfo;
select * from personinfo where name like '김%';
-- 핸드폰 마지막 자리가 1212인 사람
select * from personinfo where hp like '%1212';
-- 입사일자가 11월인 사람을 출력하시오.
select * from personinfo where to_char(ipsaday,'mm')='11';
-- 입사일이 올해 인사람을 출력하시오.
select * from personinfo where to_char(ipsaday,'yyyy')='2023';
-- 나이가 20~30 사이인 사람
select * from personinfo where age between 20 and 30;
-- 직업이 백수 이거나 의사인 사람
select * from personinfo where job='의사' or job='백수';
-- 직업이 백수 이거나 의사가 아닌 사람
select * from personinfo where job not in ('의사','백수');
-- 평균나이, 소수점 한자리로 구하기
select round(avg(age),1) from personinfo;update(업데이트, 내용 수정)
- 조회시 단순히 변경하여 출력하는것이 아니라 DB에 저장된 자료 자체를 수정하는 것이다.
-- 내용수정(update)
-- 3번 직업 나이 수정하기,
-- 조건이 없으면 모든 데이터가 수정된다.
-- UPDATE 테이블명 SET 컬럼1='변경할데이터' WHERE 컬럼2='데이터값';
-- SQL> UPDATE 테이블명 SET 컬럼1='변경할데이터' WHERE 컬럼1='데이터값';
update personinfo set job='던창',age=35;
-- 잘못수정한 데이터 원래대로 돌려놓기 (커밋전에 해야함. 커밋하면 안됌. 커밋하면 최종버전 느낌)
-- rollback;
rollback;
update personinfo set job='던창',age=35 where num=3;
-- 이씨 이면서 여자인 사람의 젠더를 남자로 수정하기.
update personinfo set gender='남자' where name like '이%' and gender='여자';
-- num이 8번인 사람의 직업을 교사로, 입사일으 2000-12-25 로 변경하기
update personinfo set job='교사', ipsaday='2000-12-25' where num=8;delete (삭제)
-- 삭제
--DELETE FROM 테이블명;
delete from personinfo;
rollback;
delete from personinfo where num=2;
-- 여자중에서 나이가 25세 이상만 모두 삭제
delete from personinfo where gender='여자' and age>25;
-- 핸드폰을 ***-****-**** 으로 수정
update personinfo set hp='***-****-****';
-- 테이블 삭제
-- 시퀀스 삭제
drop table personinfo;
drop sequence seq_start;group by
- 쉽게 생각해서 where 조건에 Group 조건을 하나 더 주는 것이다.
- 예시 : where 조건을 반영하시오. 단 A,B Group 중에서만…


--Group by
-- professor에서 학과별로 교수들의 평균급여를 출력하시오.
select deptno, avg(pay)"평균 급여" from professor group by deptno;
-- select절에 사용된 그룹함수 이외의 컬럼이나 현식은 반드시 group by에 사용되어야 한다.
-- professor에서 직급별 평균보너스를 구해보세요.
select position, avg(nvl(bonus,0))"평균 보너스" from professor group by position;
select deptno, position, avg(nvl(bonus,0))"평균 보너스" from professor group by deptno, position;
-- student에서 최고 키와 최고 몸무게를 출력
select grade, max(height) "최고 신장" , max(weight) "최고 몸무게" from student group by grade;
-- 교수의 직급별 총급여와 최고보너스를 구하시오.
select position, sum(pay) "총급여", max(bonus)"최고 보너스" from professor group by position;
-- emp에서 동일한 직업끼리의 사원수
select job "직무", count(job) "사원수" from emp group by job;
-- having 절_조건을 주고 검색하기._반드시 group by 뒤에 쓰인다.
-- 평균급여가 2000 이상인 부서의 부서번호와 평균급여를 구하시오.
select deptno, avg(sal) from emp group by deptno having avg(sal)>2000;
-- where절은 그룹함수의 비교조건으로 쓸수없다.
--professor에서 평균급여가 300 이상인 학과의 학과번호와 평균급여를 구하시오
select deptno 학과 , avg(pay) 평균급여 from professor group by deptno having avg(pay)>300;
--professor에서 평균급여가 300 이상인 학과의 학과번호와 평균급여를 구하시오, 단 101학과는 제외하시오.
select deptno 학과 , avg(pay) 평균급여 from professor where deptno not in(101) group by deptno having avg(pay)>300;
--professor에서 평균급여가 300 이상인 학과의 학과번호와 평균급여를 구하시오, 단 101학과는 제외하시오. 내림차순 정렬까지!
select deptno 학과 , avg(pay) 평균급여 from professor where deptno not in(101) group by deptno having avg(pay)>300 order by avg(pay) desc;
-- emp에서 job별로 sal의 평균급여를 구하시오
select job, avg(sal) from emp group by job;
-- professor에서 직급별 총급여를 구하시오.
select deptno, sum(pay) from professor group by deptno;
-- emp에서 직업별 인원수 최대급여 최소급여 출력하세요 (job의 오름차순)
select job, count (job), max(sal),min(sal) from emp group by job order by job;
-- emp에서 입사년도 그룹로 출력 (입사년도, 인원수, 급여평균(소수점 없이) ) _출력 : 입사년도의 오름차순
select to_char(hiredate,'yyyy') 입사년도, count(*) 인원수, round(avg(sal),0) 평균급여 from emp group by to_char(hiredate,'yyyy') order by to_char(hiredate,'yyyy');rollup (소계, 합계), cube(총계) 함수
-- Rollup 함수
-- 자동으로 소계/합계 구해주는 함수
-- group by 절에 주어진 조건으로 소계값을 구해준다.
select deptno 학과번호, position 직위, sum(pay) 총급여 from professor group by position, rollup(deptno); -- 정교수 끼리의 합, 조교수 끼리의 합 을 추가로 나타내 준다.
select deptno 학과번호, position 직위, sum(pay) 총급여 from professor group by deptno, rollup(position);
-- count
select position,count(*), sum(pay) from professor group by rollup(position);
-- Cube 함수
-- 전체 총계!
-- rollup처럼 각소계에 전체총계까지 구해준다.
select position,count(*), sum(pay) from professor group by cube(position);
select deptno,count(*), sum(pay) from professor group by cube(deptno,position);
select deptno,count(*), sum(pay) from professor group by rollup(deptno,position);제약조건
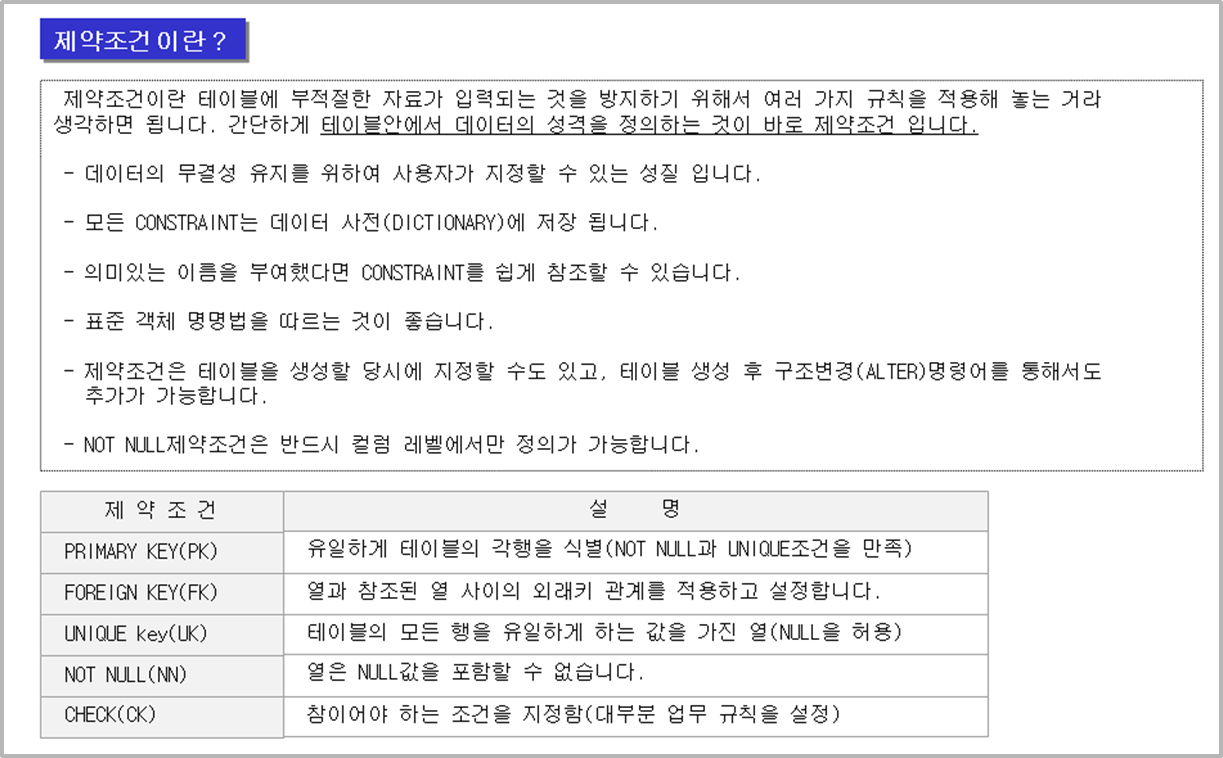
-- 제약조건
-- 테이블 생성
create table sawon (num number(5) CONSTRAINT sawon_pk_num primary key, name varchar2(20),
gender varchar2(10), buseo varchar2(20) constraint sawon_ck_buseo check(buseo in('홍보부','인사부','교육부')),
pay number(10) default 2000000);
-- 시퀀스 생성
create sequence seq_sawon nocache;
-- 데이터 10개 정도 insert
-- 체크 제약조건(SCOTT.SAWON_CK_BUSEO)이 위배되었습니다
insert into sawon values(seq_sawon.nextval,'이영미','여자','교육부',3500000);
insert into sawon values(seq_sawon.nextval,'김신영','여자','인사부',2700000);
insert into sawon values(seq_sawon.nextval,'소지섭','여자','교육부',4200000);
insert into sawon values(seq_sawon.nextval,'마징가','남자','홍보부',2600000);
insert into sawon values(seq_sawon.nextval,'고레와','남자','교육부',5300000);
insert into sawon values(seq_sawon.nextval,'사이다','남자','교육부',2400000);
insert into sawon values(seq_sawon.nextval,'까마귀','여자','인사부',3100000);
insert into sawon values(seq_sawon.nextval,'김치남','여자','인사부',3500000);
insert into sawon values(seq_sawon.nextval,'이상순','여자','교육부',3400000);
insert into sawon values(seq_sawon.nextval,'김수시','남자','홍보부',2800000);
insert into sawon values(seq_sawon.nextval,'박지은','여자','홍보부',4000000);
insert into sawon values(seq_sawon.nextval,'김형진','남자','교육부',4300000);
insert into sawon values(seq_sawon.nextval,'김치호','여자','교육부',4400000);
commit;연습문제!
-- dept에서 30번 부서를 시애틀로 변경해주세요.
update dept set loc='시애틀' where deptno=40;
-- emp 테이블 Totalsal열을 하나 추가하세요. (number (20)으로 줄것)
alter table emp add Totalsal number(20);
-- emp 테이블 Totalsal에 sal과 comm을 합한 가격을 출력하시오.
update emp set totalsal=sal+nvl(comm,0);
-- emp에서 ward 삭제하시오.
delete from emp where ename='WARD';
-- product 테이블에서 100번을 쵸코파이로 수정하세요.
update product set p_name='쵸코페이' where p_code=100;
-- Q1. emp에서 평균연봉이 2000 이상인 부서의 부서번호와 평균급여를 구하시오.
select deptno 부서번호, avg(sal) 평균급여 from emp group by deptno having avg(sal)>2000;
-- Q2. emp에서 deptno별 인원수 구하기
select deptno, count(deptno) from emp group by deptno;
-- Q3. emp에서 job별 인원수를 구하시오(단 인원이 2명이상인곳만 구할것)
select job, count(job) from emp group by job having count(job)>=2;
--Q4. emp에서 job별 급여합계를 구하는데 (president는 제외할것) 급여합계가 5000이상만 구하시고 급여합게가 높은것부터 출력하시오.
-- 출력은 job, 급여총계
select job, sum(sal) from emp where job not in('PRESIDENT') group by job having sum(sal)>=5000 order by sum(sal);
-- Q1. 부서별 인원수와 최고급여, 최저급여 조회
select buseo, count(buseo) 인원수,max(pay) 최고급여, min(pay) 최저급여 from sawon group by buseo;
-- Q2. 위의 쿼리문에서 최고급여, 최저급여에 화폐단위를 붙히고 3자리 컴마도 나오게 해주세요
select buseo, count(buseo) 인원수,to_char(max(pay),'L999,999,999') 최고급여, to_char(min(pay),'L999,999,999') 최저급여 from sawon group by buseo;
-- Q3. 성별 인원수와 평균급여를 출력하시오(인원수 뒤에 명 이라고 나오도록...)
select gender, count(*) || '명' "성별 인원수", avg(pay) from sawon group by gender;
-- Q4. 부서별 인원수와 평균급여를 구하되 인원이 4명 이상인 경우에만 출력하도록 하세요.
select buseo 부서,count(buseo) "부서별 인원수", round(avg(pay),0) "평균 급여" from sawon group by buseo having count(buseo)>4;

java를 잡아...... 하... 이게 맞나...