Recurrent Neural Networks (RNN)
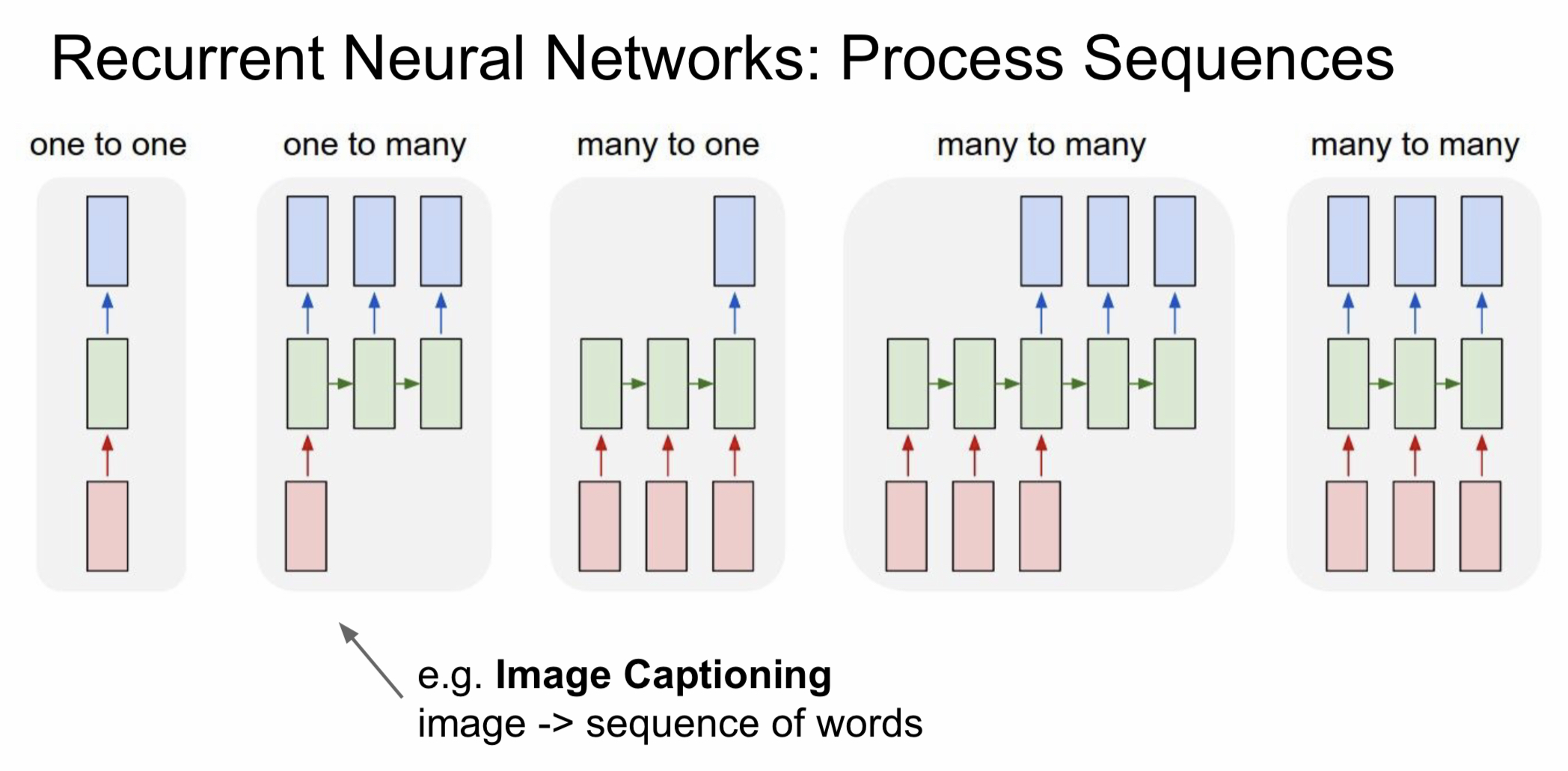
- one-to-one: 가장 기본적인 형태, 하나의 입력이 hidden layer를 거쳐 하나의 출력을 내보냄
- one-to-many: 하나의 입력에 대해서 여러 개의 출력을 내보냄 ex) image captioning
- many-to-one: 여러 입력에 대해서 하나의 출력을 내보냄 ex) sentiment classification
- many-to-many: 여러 입력에 대해서 여러 개의 출력을 내보냄
- 입력에 대한 출력이 바로 나오는 경우: 비디오를 프레임 단위로 classification
- 입력에 대한 출력 시간 차이가 존재하는 경우: 기계번역

- 입출력은 고정이지만, sequential preocessing이 요구되는 경우
- 정답을 예측할 때, 네트워크가 이미지의 여러 부분을 조금씩 살펴본 후, 최종적으로 숫자를 판단
- 입출력이 고정된 길이라도 가변 과정인 경우에 RNN이 상당히 유용

- train time에서 본 이미지들을 바탕으로 새로운 이미지를 생성하는 예제
- RNN을 이용하여, 순차적으로 전체 출력의 일부분씩 생성
- 이 경우도, 출력은 고정된 길이지만 RNN을 이용해서 일부분씩 순차적으로 처리할 수 있음
RNN의 동작 원리
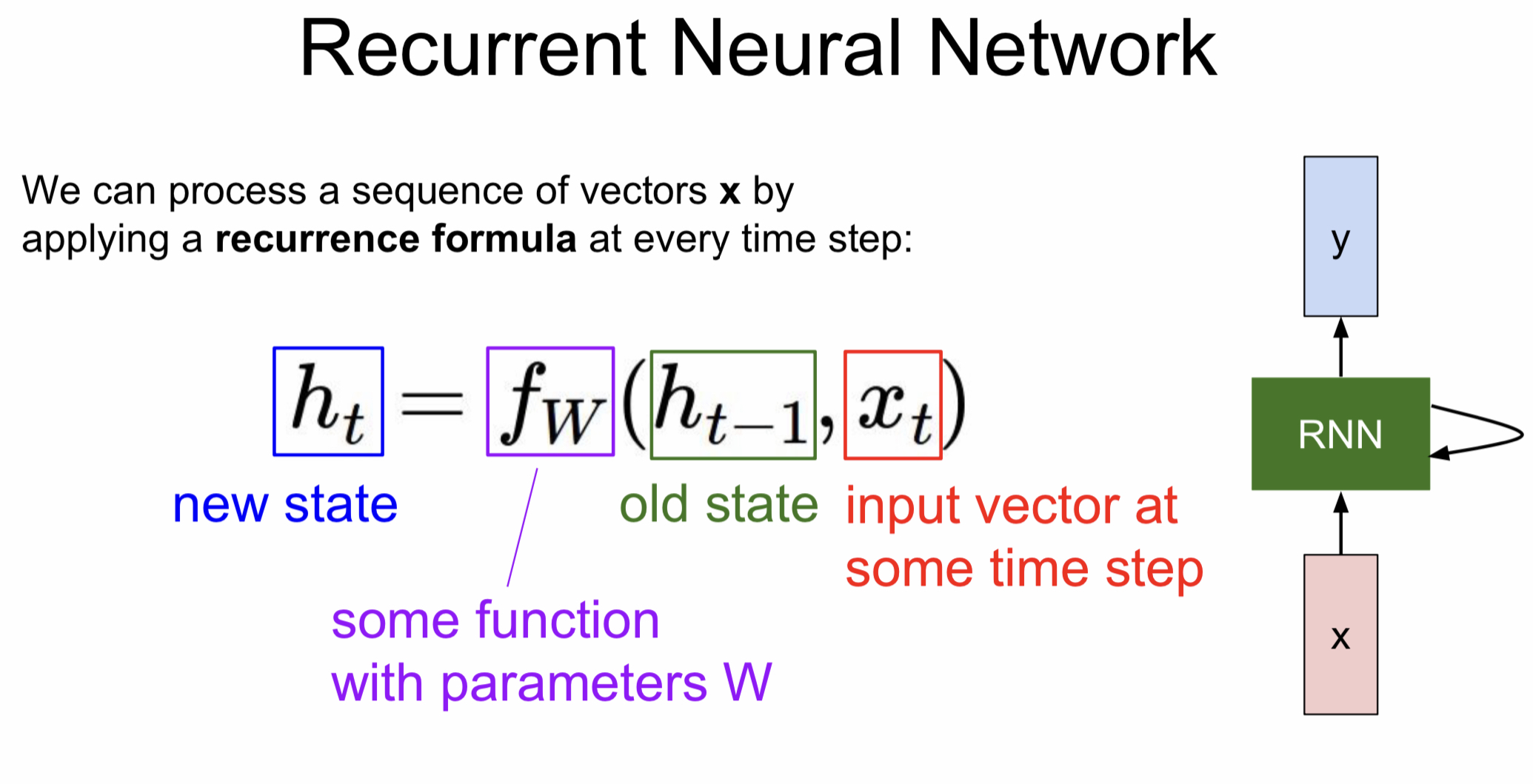
- 일반적으로 RNN은 작은 Recurrent Core Cell을 가지고 있음
- 입력 x가 RNN으로 들어감
- RNN 내부에 있는 hidden state는 RNN이 새로운 입력을 불러들일 때마다 매번 업데이트
- hidden state는 모델에 feed back되고, 이후에 새로운 입력 x가 들어옴 (출력 값을 얻길 원하는 경우에는, hidden state 업데이트 후 출력 값을 내보냄)
- RNN block은 위의 식처럼 재귀적인 관계를 연산할 수 있도록 설계
- 파라미터 W를 가진 함수 f가 존재할 때, 이 함수는 이 전 상태의 hidden state()와 현재 상태의 입력()를 입력으로 받음
- 출력은 다음 상태의 hidden state() (hidden state 업데이트)
- 중요한 것은 함수 f와 파라미터 W는 매 스텝 동일하다는 것

- Vanilla RNN을 수식적으로 표현
- 이전 hidden state와 현재 입력을 받아서 다음 hidden state를 출력
- 간단하게 수식적으로 표현해보면, 가중치 행렬 와 입력 의 곱으로 나타낼 수 있음
- hidden state 또한, 가중치 행렬 와 이전 hidden state 의 곱으로 나타낼 수 있음
- 두 행렬 곱 연산의 결과를 더한 후, non-linearity를 구현하기 위해 tanh 함수를 적용 (선형함수를 사용하게 되면, 층을 거치면서 크게 변화가 발생하지 않음. tanh함수는 RNN의 gradient가 최대한 오래 유지할 수 있도록 해주는 역할로 사용)
- 출력 를 얻고 싶다면, hidden state인 를 새로운 가중치 행렬 와 곱해줌
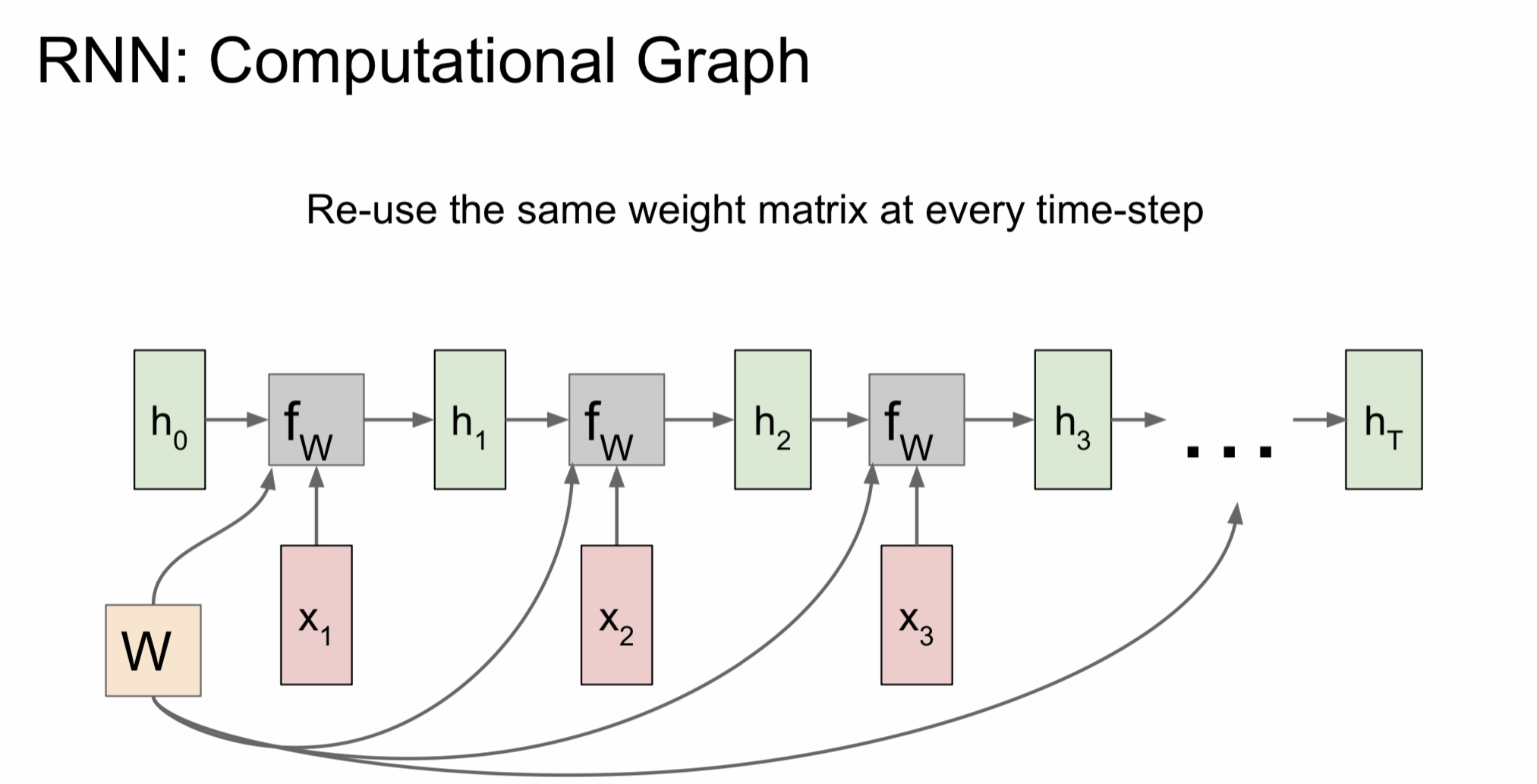
- RNN을 computational graph로 그리면 다음과 같은 모양을 얻을 수 있음
- 여기서 주목할 점은, hidden state를 업데이트할 때마다 동일한 가중치 행렬 W가 매번 사용된다는 점 (h와 x는 달라지지만, W는 매번 동일)
- RNN 모델의 역전파법을 위한 행렬 W의 gradient를 구하려면, 각 스텝에서 W에 대한 gradient를 전부 계산한 뒤, 모두 더해주면 된다
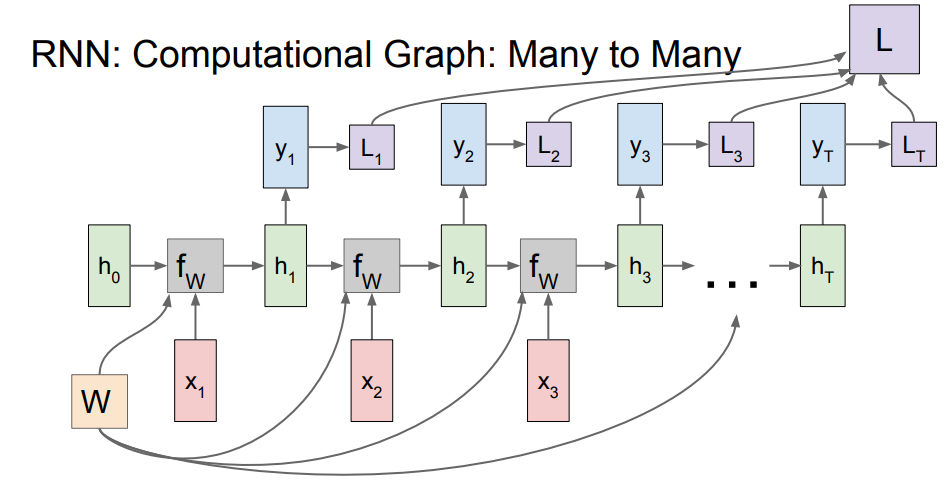
- RNN의 출력 값 가 또 다른 네트워크의 입력으로 들어가서 출력 를 만들어 냄
- 이때 출력 는 매 스텝의 class score
- 출력 에 대한 loss를 계산할 수 있으며, 각 스텝에서 생성된 loss들의 합이 RNN 전체의 loss 값
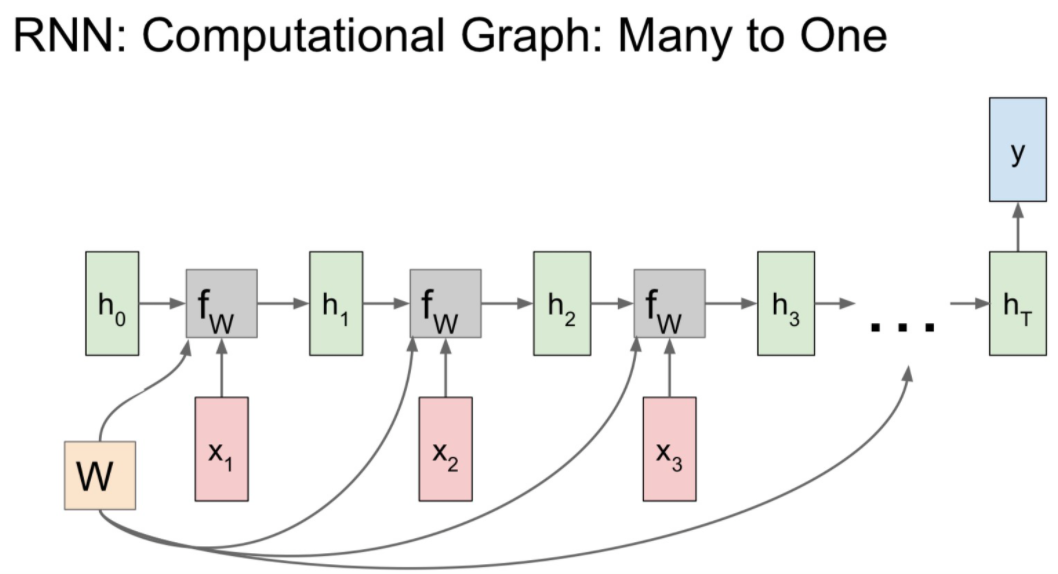
- many-to-one의 경우, 최종 hidden state에서만 결과 값이 나올 것
- 이는 최종 hidden state가 전체 시퀀스의 내용에 대한 일종의 요약으로 볼 수 있기 때문
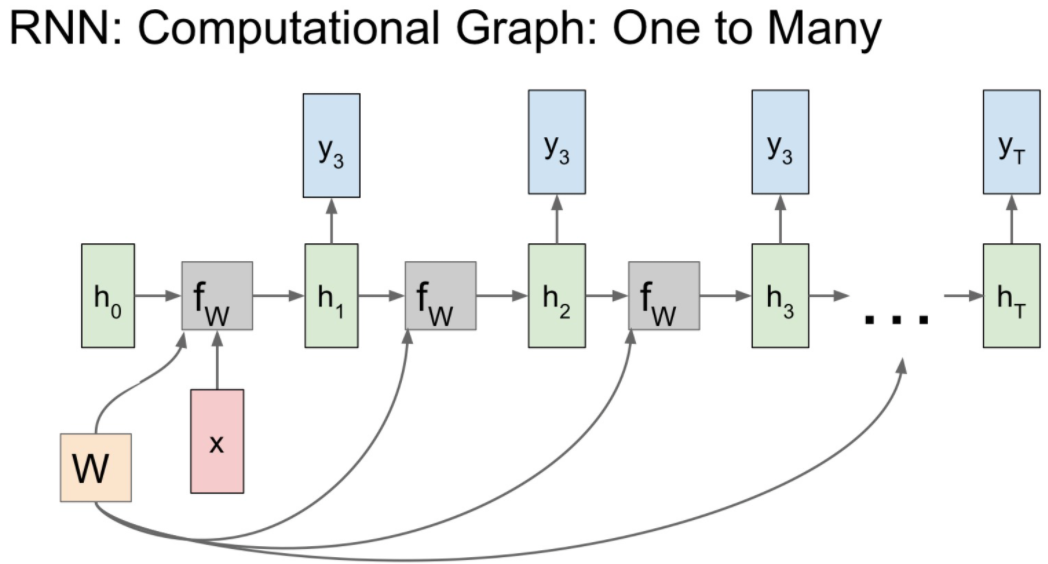
- 고정 입력을 받지만, 가변 출력인 네트워크
- 이 경우는, 입력 모델의 inital hidden state를 초기화시키는 용도로 사용
- RNN은 모든 스텝에서의 출력 값을 가짐
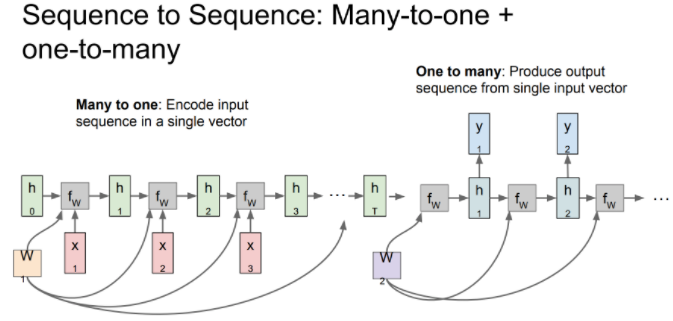
- sequence to sequence 모델, 가변 입력과 가변 출력을 가지는 모델 (many-to-one 모델과 one-to-many 모델의 결합, encoder와 decoder 구조)
- encoder(many-to-one)에서는 가변 입력을 하나의 벡터로 요약
- 이후 decoder(one-to-many)에서는 요약한 벡터를 가변 출력으로 변환하여 출력
- 가변 출력은 매 스텝에서 적절한 단어를 내뱉음
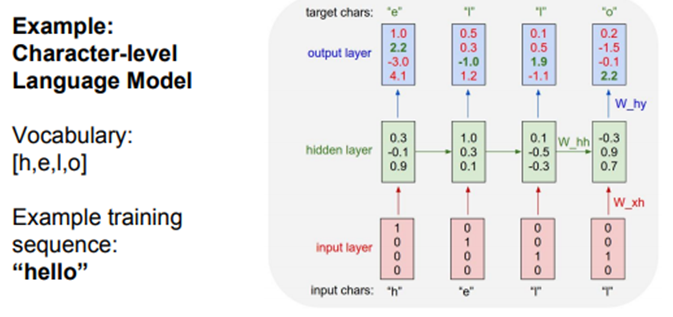
- 다음은 character level language model
- 네트워크는 문자열 시퀀스를 읽고, 현재 문맥에서 다음에 나올 문자를 예측해야 함
- train time에서는 training sequence의 각 단어들을 입력으로 넣어줌 ('hello'가 RNN의 )
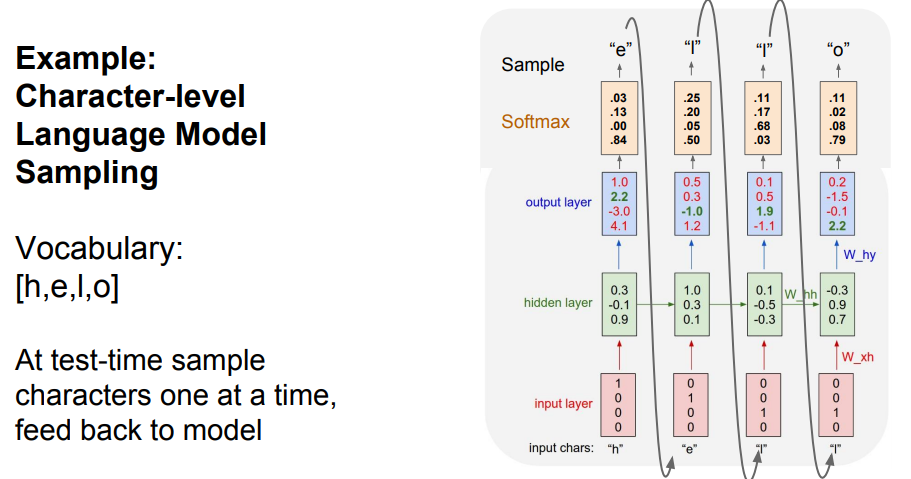
- 해당 모델의 test time
- 우선, 모델에게 문장의 첫 글자만 입력
- 첫 스텝에서 문자 'h'를 이용하여 모든 문자에 대한 스코어를 계산
- 이후, 계산된 스코어를 이용하여 다음 문자를 선택
- 선택된 문자를 다음 스텝의 입력으로 넣어줌

코딩하는 물리학도