Learning Spark
chapter 2. 아파치 스파크 다운로드 및 시작
3단계: 스파크 애플리케이션 개념의 이해
중요 용어 정리
- 애플리케이션: API를 써서 스파크 위에서 돌아가는 사용자 프로그램. 드라이버 프로그램과 클러스터의 실행기로 이루어진다.
- SparkSession: 스파크 코어 기능들을 사용할 수 있는 시작점을 제공, API로 프로그래밍을 할 수 있게 하는 객체이다. 스파크 셸에서 스파크 드라이버는 기본적으로 SparkSession를 제공하며, 애플리케이션에서는 사용자가 직접 SparkSession를 생성해서 사용해야 한다.
- 잡(job): 스파크 액션에 대한 응답으로 생성되는 여러 태스크들의 병렬 연산
- 스테이지(stage): 각각의 job들은 스테이지라고 불리는 서로 의존성을 가지는 다수의 태스크 모음으로 나뉜다.
- 태스크(task): 스파크 이그제큐터로 보내지는 작업 실행의 가장 기본적인 단위
트랜스포메이션, 액션, 지연 평가
트랜스포메이션은 이미 불변성의 특징을 가진 원본 데이터를 수정하지 않고 하나 의 스파크 데이터 프레임을 새로운 데이터 프레임으로 변형한다. 액션은 쿼리 실행 계획의 일부로서 기록된 모든 트랜스포메이션들의 실행을 시작하게 한다.
지연평가
액션이 실행되는 시점이나 데이터에 실제 접근하는 시점까지 실제 행위를 미루는 스파크의 전략으로 하나의 액션은 모든 기록된 트랜스포메이션의 지연 연산을 발동시킨다. 이 지연 연산은 쿼리 최적화를 가능하게 하는 반면, 리니지와 데이터 불변성은 장애에 대한 데이터 내구성을 제공한다.
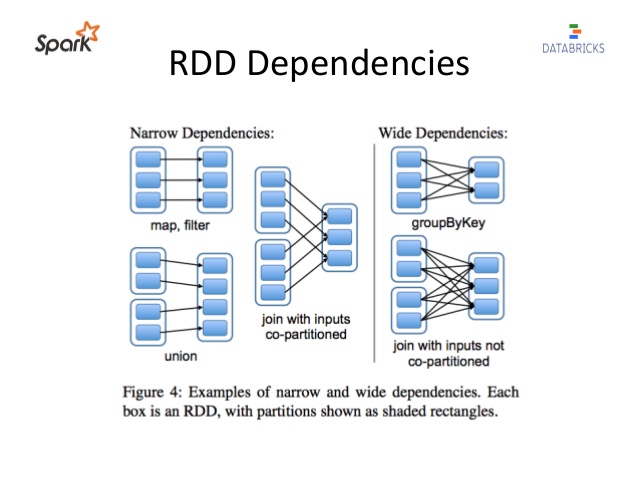
좁은/넓은 트랜스포메이션
트랜스포메이션은 지연 연산 종류이기 때문에 연산 쿼리를 분석하고 최적화하는 점에서 장점이 있다.
여기서 말하는 최적화는 연산들의 조인이나 파이프라이닝이 될 수 있고, 셔플이나 클러스터 데이터 교환이 필요한지 파악해 가장 간결한 실행 계획으로 데이터 연산 흐름을 만드는 것이다.
여기서 트랜스포메이션을 아래 두가지 유형으로 분류할 수 있다.
- 좁은 의존성: 하나의 출력 파티션에만 영향을 미치는 연산으로 파이션 간의 데이터 교환은 없으며, 스파크는 파이프라이닝을 자동으로 수행한다. ex. where(), filter(), contains()
- 넓은 의존성: 하나의 입력 파티션이 여러 출력 파티션에 영향을 미치는 연산으로, 스파크는 클러스터에서 파티션을 교환하는 셔플을 수행하고 결과는 디스크에 저장한다. ex. groupBy(), orderBy()
스파크 UI
스파크는 스파크 애플리케이션을 살펴볼 수 있는 그래픽 유저 인터페이스(GUI)를 제공한다.
드라이버 노드의 4040 포트를 사용하며, 아래 내용을 볼 수 있다.
- 스파크 잡의 상태(스케줄러의 스테이지와 태스크 목록)
- 환경 설정 및 클러스터 상태 등의 정보
- RDD 크기와 메모리 사용 정보
- 실행 중인 이그제큐터 정보
- 모든 스파크 SQL 쿼리
로컬 모드에서 웹 브라우저를 통해 http://localhost:4040 으로 접속해보자. 아래와 같은 화면에서 잡, 스테이지, 태스크들이 어떻게 바뀌어 진행되는지, 연산 내에서 여러 개의 태스크가 병렬 실행될 때 스테이지의 자세한 상황 등등 확인할 수 있다. 스파크 UI가 스파크 내부 작업에 대해 디버깅 및 검사 도구의 역할을 한다는 것을 이해하고 더 자세한 내용은 7장에서 다루겠다.
