<모두의 딥러닝> 읽으면서 정리해둘 겸 작성하는 글입니다.
#1) 첫째 마당: 나의 첫 딥러닝
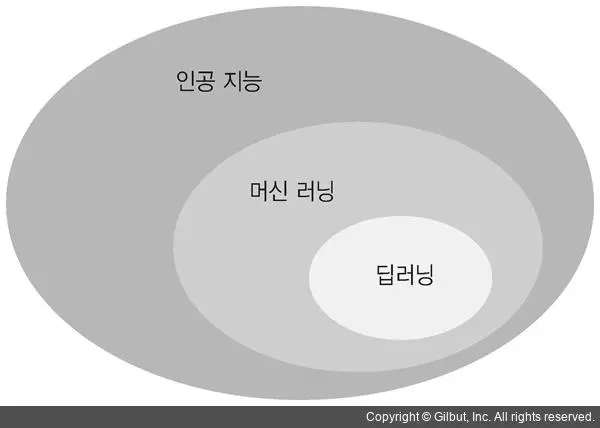
먼저 인공지능, 머신러닝, 딥러닝을 주로 혼동하여서 생각하는데 실제로는 사람의 뇌를 닮은 '인공지능'을 연구하던 중 기존의 데이터를 이용하여 앞으로의 일을 예측하는 '머신러닝'기법이 존재하고 또 '머신러닝'안에는 여러 알고리즘들이 있는데 이 중 가장 좋은 효과를 내는 것이 바로 '딥러닝'입니다.
그리고 머신러닝의 학습 및 예측의 과정을 간단히 예시로 설명하면
수술하기 전에 수술 후의 생존율을 수치로 예측할 방법을 찾는다고 할 때에 여러가지 환자의 속성값과 그에 따른 클래스 값(0=사망 1=생존)을 모아둔 데이터를 입력으로 받아 환자들의 클래스 값을 그래프 위에 펼쳐놓고 이 분포도 위에 생존과 사망 여부를 구분짓는 경계를 그려넣습니다. 이때 데이터가 입력되고 패턴이 분석되는 과정을 학습(training)이라고 하며 그 경계를 정확하게 그려넣는 방법들로 랜덤 포레스트(random forest),서포트 벡터 머신(support vector machine)등 많은 방법들이 고안되었습니다.
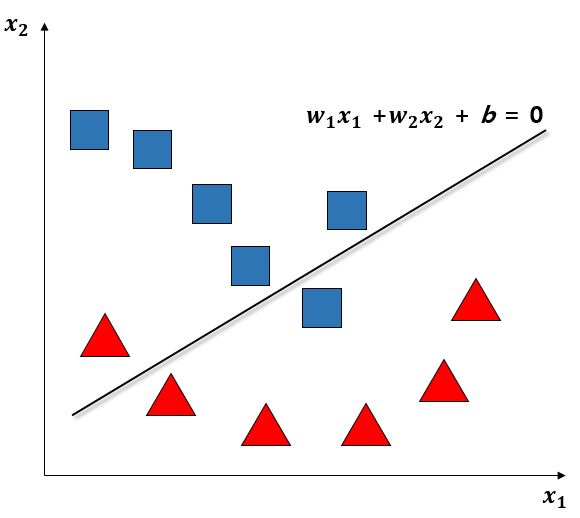
그리고 경계선이 그려진 평면은 일종의 모델이 되는 것이고 새로운 데이터를 넣으면 새로운 환자에 대한 예측을 모델에 기반하여 하게되는 것입니다.
정리하자면 데이터 값이 위의 그림에서 동그라미 및 세모로 표현되고 이를 바탕으로 둘을 구분하는 선을 만드는 것이 곧 모델을 만드는 것이며 선의 정확도를 높이는것이 주요 관건이며, 이후 기존의 동그라미와 세모 (train 데이터셋)가 아닌 새로운 동그라미 및 세모(test 데이터셋)을 input으로 하였을때 그어진 선에 따라 평면에 그려지게 되는 과정이라고 생각할 수 있습니다.
그리고 이러한 모델을 설계할 때 사용하는 것들을 보면
#딥러닝 구조룰 결정(모델을 설정하고 실행하는 부분)
model = Sequential()
model.add(Dense(30, input_dim=17, activation='relu'))
model.add(Dense(1,activation='sigmoid'))model.add() 함수를 이용해 필요한 만큼의 층을 쌓고,
model.compile(loss='mean_squared_error',optimizer='adam',metrics=['accuracy'])
model.fit(X,Y,epoch=30,batch_size=10)model.compile() 함수를 이용해 인자값을 받아 이를 실행시킵니다.
이때 들어가는 인자값을 보면 activation,loss,optimizer를 상황에 맞게 설정하며 키워드를 간단하게 설명하면
activation: 다음 층으로 어떻게 값을 넘길지 결정하는 부분. 주로 relu 혹은 sigmoid함수를 사용합니다.
loss: 한 번 신경망이 실행될 떄마다 오차 값을 추적하는 함수입니다.
optimizer: 오차를 어떻게 줄여 나갈지 정하는 함수입니다.
이후 모댈의 정확도를 측정하기 위해서는 model.evaluate()함수를 이용하여 측정합니다.
이때 실제 사용에서는 test와 train의 데이터셋을 구분하여 evaluate()과정에서는 test 데이터셋만을 사용합니다.
딥러닝 내부에서 어떤 방식으로 결과를 도출하는지를 알지 못하여 이를 주로 '블랙박스'같다고 하는데 그 구동원리 등으로 '선형회귀', '로지스틱 회귀','신경망','역전파'등등을 다음 장에서 배우게 됩니다.
출처 및 참고자료
그림자료
https://www.popit.kr/deep-learning-2/
https://tensorflow.blog/%EC%BC%80%EB%9D%BC%EC%8A%A4-%EB%94%A5%EB%9F%AC%EB%8B%9D/1-%EB%94%A5%EB%9F%AC%EB%8B%9D%EC%9D%B4%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80/
'모두의 딥러닝'<길벗 출판사>
