소프트맥스 연산
소프트맥스(softmax)함수는 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산입니다.
분류 문제를 풀 때 선형모델과 소프트맥스 함수를 결합하여 예측합니다.
💻 알고리즘
def softmax(vec):
denumerator = np.exp(vec - np.max(vec, axis=1, keepdims=True))
numerator = np.sum(denumerator, axis=1, keepdims=True)
val = denumerator / numerator
return val신경망
신경망은 선형모델과 활성함수(activation function)을 합성한 함수입니다.
활성함수 (activation function)
비선형 함수로서 딥러닝에서 매우 중요한 개념입니다!
활성함수를 쓰지 않으면 딥러닝은 선형모형과 차이가 없습니다.
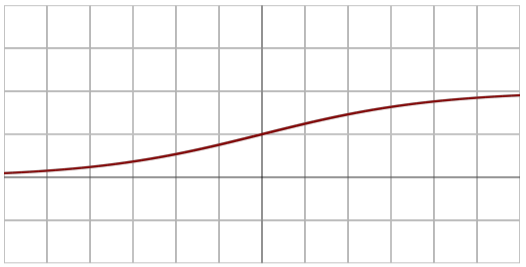
시그모이드
전통적인 활성함수라고 할 수 있습니다.
에서 사이의 값을 가집니다.
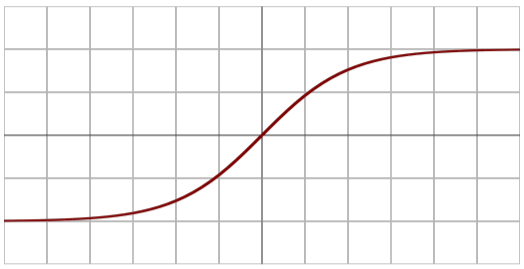
하이퍼 탄젠트
전통적인 활성함수라고 할 수 있습니다.
에서 사이의 값을 가집니다.
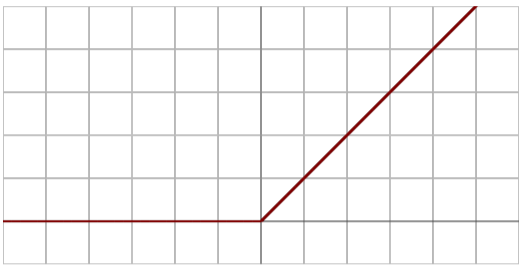
렐루
딥러닝에서 많이쓰입니다.
0보다 작은 값에서는 을 반환하고, 이상의 값에서는 를 반환합니다.
다층 퍼센트론 (MLP)
신경망이 여러층 합성된 함수를 말합니다.
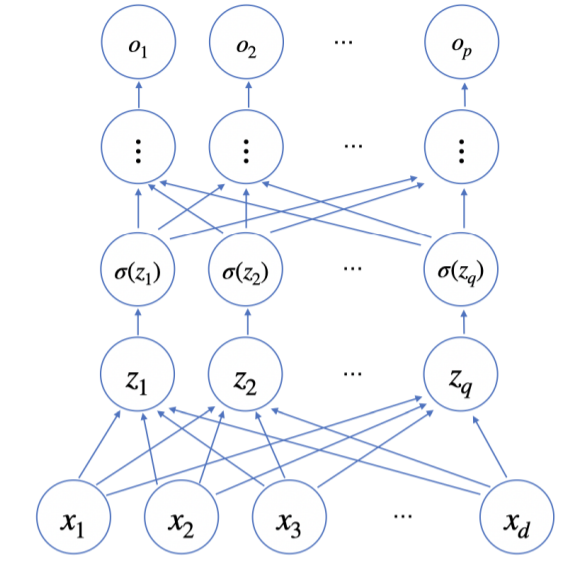
❓ 왜 여러층을 쌓는 걸까?
📝 층이 깊을수록 목적함수를 근사하는데 필요한 뉴런(노드)의 숫자가 훨씬 빨리 줄어들어 좀 더 효율적으로 학습이 가능하기 때문입니다!
역전파 알고리즘
딥러닝은 역전파 알고지름을 이용하여 각 층에 사용된 파라미터를 학습합니다.
각 층 파라미터의 그레디언트 벡터는 윗층부터 역순으로 계산하게 됩니다. 이때 합성함수의 미분법인 연쇄법칙 기반 자동미분을 사용하게 됩니다.

참고자료
네이버 부스트 캠프 AItech

두꺼비는 두껍다