스티커 모으기(2)
문1) N개의 스티커가 원형으로 연결되어 있습니다. 다음 그림은 N = 8인 경우의 예시입니다.
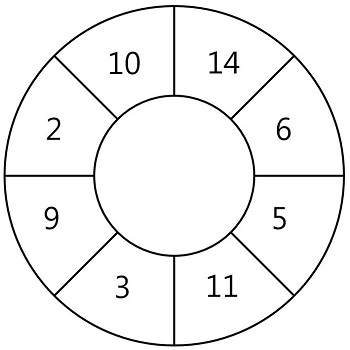
원형으로 연결된 스티커에서 몇 장의 스티커를 뜯어내어 뜯어낸 스티커에 적힌 숫자의 합이 최대가 되도록 하고 싶습니다. 단 스티커 한 장을 뜯어내면 양쪽으로 인접해있는 스티커는 찢어져서 사용할 수 없게 됩니다.
예를 들어 위 그림에서 14가 적힌 스티커를 뜯으면 인접해있는 10, 6이 적힌 스티커는 사용할 수 없습니다. 스티커에 적힌 숫자가 배열 형태로 주어질 때, 스티커를 뜯어내어 얻을 수 있는 숫자의 합의 최댓값을 return 하는 solution 함수를 완성해 주세요. 원형의 스티커 모양을 위해 배열의 첫 번째 원소와 마지막 원소가 서로 연결되어 있다고 간주합니다.
제한 사항
- sticker는 원형으로 연결된 스티커의 각 칸에 적힌 숫자가 순서대로 들어있는 배열로, 길이(N)는 1 이상 100,000 이하입니다.
- sticker의 각 원소는 스티커의 각 칸에 적힌 숫자이며, 각 칸에 적힌 숫자는 1 이상 100 이하의 자연수입니다.
- 원형의 스티커 모양을 위해 sticker 배열의 첫 번째 원소와 마지막 원소가 서로 연결되어있다고 간주합니다.
입출력 예
| sticker | answer |
|---|---|
[14,6,5,11,3,9,2,10] | 36 |
[1,3,2,5,4] | 8 |
입출력 예 설명
입출력 예 #1
6,11,9,10이 적힌 스티커를 떼어 냈을 때 36으로 최대가 됩니다.
입출력 예 #2
3,5가 적힌 스티커를 떼어 냈을 때 8로 최대가 됩니다.
나의 풀이
package programmers;
public class CollectStickers {
public static int solution(int[] sticker) {
if (sticker.length == 1) return sticker[0];
int n = sticker.length;
int[] dp1 = new int[n];
int[] dp2 = new int[n];
dp1[0] = dp1[1] = sticker[0];
for (int i = 2; i < n - 1; i++) {
dp1[i] = Math.max(dp1[i - 1], dp1[i - 2] + sticker[i]);
}
dp2[0] = 0;
dp2[1] = sticker[1];
for (int i = 2; i < n; i++) {
dp2[i] = Math.max(dp2[i - 1], dp2[i - 2] + sticker[i]);
}
return Math.max(dp1[n - 2], dp2[n - 1]);
}
public static void main(String[] args) {
int[] stickers = {1,3,2,1,4,1};
solution(stickers);
}
}
나의 생각
최적 부분 구조 (Optimal Substructure)
- 특정 스티커를 선택하면, 그 스티커와 인접한 스티커들은 선택할 수 없게 되므로, 각 스티커를 선택할 때의 최대 합은 이전의 선택들에 영향을 받음. 이러한 속성은 동적 프로그래밍에서 중요한 특징임
중복된 하위 문제(Overlapping subproblems)
- 스티커를 선택하는 과정에서 각 단계에서의 최적의 선택(최대합)은 이후의 선택에도 영향을 미침. 예를 들어, 특정 스티커를 선택했을 때의 최대 합은 그 이후의 선택에도 사용될 수 있음
원형 배열 처리
- 원형으로 연결된 스티커에서는 첫 번째와 마지막 스티커가 서로 인접해 있음
이를 처리하기 위해, 원형 배열을 두 개의 선형 배열 문제로 나눌 수 있음. 하나는 첫 번째 스티커를 포함하고 마지막 스티커를 제외한 경우, 다른 하나는 첫 번째 스티커를 제외하고 마지막 스티커를 포함한 경우임. 각각의 경우에 대해 독립적으로 최대 합을 구한 다음, 두 경우 중 더 큰 값을 선택함
불량 사용자
문2) 개발팀 내에서 이벤트 개발을 담당하고 있는 "무지"는 최근 진행된 카카오이모티콘 이벤트에 비정상적인 방법으로 당첨을 시도한 응모자들을 발견하였습니다. 이런 응모자들을 따로 모아 불량 사용자라는 이름으로 목록을 만들어서 당첨 처리 시 제외하도록 이벤트 당첨자 담당자인 "프로도" 에게 전달하려고 합니다. 이 때 개인정보 보호을 위해 사용자 아이디 중 일부 문자를 '' 문자로 가려서 전달했습니다. 가리고자 하는 문자 하나에 '' 문자 하나를 사용하였고 아이디 당 최소 하나 이상의 '*' 문자를 사용하였습니다.
"무지"와 "프로도"는 불량 사용자 목록에 매핑된 응모자 아이디를 제재 아이디 라고 부르기로 하였습니다.
예를 들어, 이벤트에 응모한 전체 사용자 아이디 목록이 다음과 같다면
| 응모자 아이디 |
|---|
| frodo |
| fradi |
| crodo |
| abc123 |
| frodoc |
다음과 같이 불량 사용자 아이디 목록이 전달된 경우,
| 불량 사용자 |
|---|
| frd |
| abc1** |
불량 사용자에 매핑되어 당첨에서 제외되어야 야 할 제재 아이디 목록은 다음과 같이 두 가지 경우가 있을 수 있습니다.
| 제재 아이디 |
|---|
| frodo |
| abc123 |
| 제재 아이디 |
|---|
| fradi |
| abc123 |
이벤트 응모자 아이디 목록이 담긴 배열 user_id와 불량 사용자 아이디 목록이 담긴 배열 banned_id가 매개변수로 주어질 때, 당첨에서 제외되어야 할 제재 아이디 목록은 몇가지 경우의 수가 가능한 지 return 하도록 solution 함수를 완성해주세요.
제한사항
- user_id 배열의 크기는 1 이상 8 이하입니다.
- user_id 배열 각 원소들의 값은 길이가 1 이상 8 이하인 문자열입니다.
- 응모한 사용자 아이디들은 서로 중복되지 않습니다.
- 응모한 사용자 아이디는 알파벳 소문자와 숫자로만으로 구성되어 있습니다.
- banned_id 배열의 크기는 1 이상 user_id 배열의 크기 이하입니다.
- banned_id 배열 각 원소들의 값은 길이가 1 이상 8 이하인 문자열입니다.
- 불량 사용자 아이디는 알파벳 소문자와 숫자, 가리기 위한 문자 '*' 로만 이루어져 있습니다.
- 불량 사용자 아이디는 '*' 문자를 하나 이상 포함하고 있습니다.
- 불량 사용자 아이디 하나는 응모자 아이디 중 하나에 해당하고 같은 응모자 아이디가 중복해서 제재 아이디 목록에 들어가는 경우는 없습니다.
- 제재 아이디 목록들을 구했을 때 아이디들이 나열된 순서와 관계없이 아이디 목록의 내용이 동일하다면 같은 것으로 처리하여 하나로 세면 됩니다.
입출력 예
| user_id | banned_id | result |
|---|---|---|
["frodo", "fradi", "crodo", "abc123", "frodoc"] | ["fr*d*", "abc1**"] | 2 |
["frodo", "fradi", "crodo", "abc123", "frodoc"] | ["*rodo", "*rodo", "******"] | 2 |
["frodo", "fradi", "crodo", "abc123", "frodoc"] | ["fr*d*", "*rodo", "******", "******"] | 3 |
나의 풀이
package programmers;
import java.util.HashSet;
import java.util.Set;
public class BadUser {
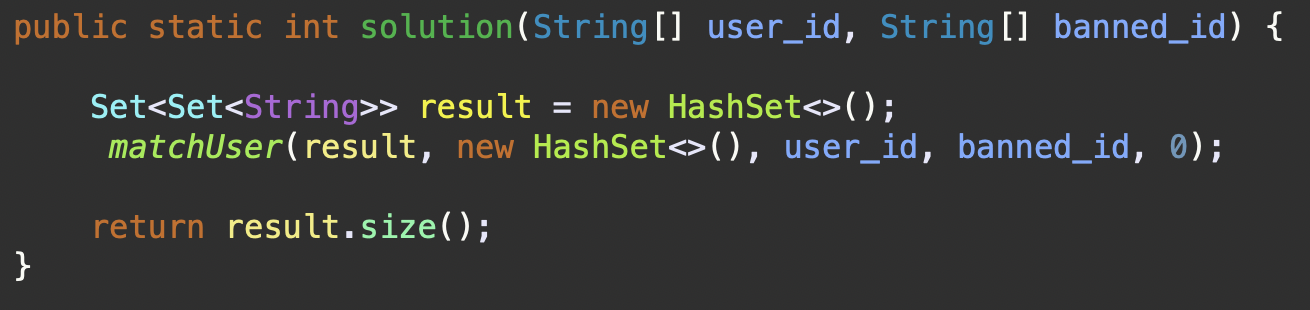
public static int solution(String[] user_id, String[] banned_id) {
Set<Set<String>> result = new HashSet<>();
matchUser(result, new HashSet<>(), user_id, banned_id, 0);
System.out.println(result);
return result.size();
}
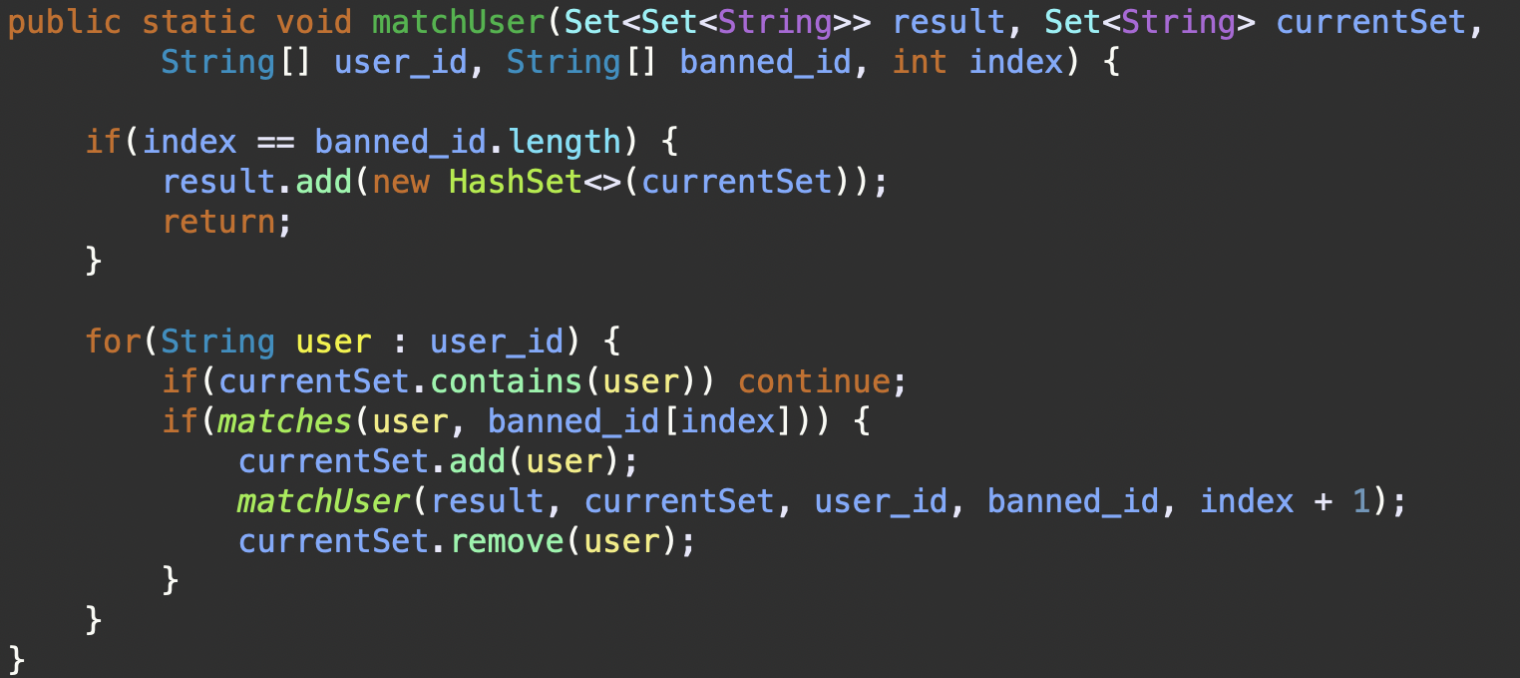
public static void matchUser(Set<Set<String>> result, Set<String> currentSet,
String[] user_id, String[] banned_id, int index) {
if(index == banned_id.length) {
result.add(new HashSet<>(currentSet));
return;
}
for(String user : user_id) {
if(currentSet.contains(user)) continue;
if(matches(user, banned_id[index])) {
currentSet.add(user);
matchUser(result, currentSet, user_id, banned_id, index + 1);
currentSet.remove(user);
}
}
}
public static boolean matches(String user, String banned) {
if (user.length() != banned.length()) return false;
for (int i = 0; i < user.length(); i++) {
if (banned.charAt(i) != '*' && user.charAt(i) != banned.charAt(i)) return false;
}
return true;
}
public static void main(String[] args) {
String[] user_id = {"frodo", "fradi", "crodo", "abc123", "frodoc"};
String[] banned_id = {"fr*d*", "*rodo", "******", "******"};
solution(user_id, banned_id);
}
}
나의 생각
제한사항을 보자마자, 재귀함수를 써서 가능한 모든 조합을 고려해야겠다는 생각을 하였다. 이와 같이 생각한 배경은 제한된 입력 크기를 가지고 있으며(최악의 경우 8^8 = 16,777,216), 문제의 제한사항을 고려한다면 실제로 탐색해야 하는 조합의 수는 이론상 최대치에 비해 상당히 줄어들 수 있을것으로 판단하였다.
어떤 자료구조를 써서, user_id 목록에서 banned_id를 검출할 것인가
- ❗️제재 아이디 목록들을 구했을 때 아이디들이 나열된 순서와 관계없이 아이디 목록의 내용이 동일하다면 같은 것으로 처리하여 하나로 세면 됩니다.
- 해당 조건을 보면 (a,b,c)나 (b,a,c)는 같다는 것이다. 👉🏻 즉, 중복은 허용하지 않는다는 뜻이므로 Set 자료구조를 쓰면 되겠다고 판단하였다.
각각의 메서드를 보면서 정리해보자.
result 변수는 예를들어, {{"a", "b", "c"}, {"a", "b", "d"}, {"a", "c", "e"}} 값을 가질 수 있다. 즉, 각각의 set은 중복을 허용하지 않으며, 전체 set도 중복을 허용하지 않는다.
matchUser()메서드는 매개변수로 result ,currentSet,user_id,banned_id,index를 갖는다.
재귀적으로 동작하는 matchUser메서드의 동작은 다음과 같다.
탈출 조건(기저조건)
index가banned_id의 길이와 같다면, user_id 목록에서 banned_id를 모두 검출하였다는 뜻이므로,currentSet을result에 담아 return한다.
핵심 로직
user_id 목록을 순회하며 목록에 든 user가 currentSet에 포함돼있으면,
continue.
즉, currentSet에 포함시킬 필요가 없으니 패스하겠다는 의미다.
matches() 호출

해당 메서드는
pattern이 일치하는지 확인하는 유효성 검증 로직으로 user 글자수와 banned 글자수가 다르면, 확인할 필요가 없으므로 false을 리턴한다.
그리고 banned의 를 제외한 글자가 user의 글자(charAt(i))와 다르면 false을 리턴
최종적으로 를 제외한 모든 문자가 일치해야 true를 반환한다.
다시 matchUser()

해당 로직이
true라면 currentSet에 user를 추가
재귀 호출
currentSet에user를 추가한 후에,matchUser메서드를 다시 호출하여 다음banned_id항목에 대한 매칭을 시도한다. 이때index + 1을 매개변수로 넘겨줌으로써, 다음banned_id인덱스에 대한 탐색을 계속 진행함
백트래킹
재귀 호출이 반환된 후,
currentset에서 방금 추가된user를 제거함. 이는 이전 상태로 되돌리는 백트래킹 단계로, 다른 조합을 탐색하기 위해 현재 조합에서user를 제거
이러한 재귀 호출과 백트래킹 과정은 모든
banned_id에 대한 가능한user_id의 모든 조합을 시도하고, 중복을 허용하지 않는 유일한 조합들을result변수에 저장하는 데 사용됨

비트 마스킹을 활용한 구현
package programmers;
import java.util.HashSet;
import java.util.Set;
public class BadUserBitMasking {
static Set<Integer> set;
public static int solution(String[] user_id, String[] banned_id) {
set = new HashSet<>();
go(0, user_id, banned_id, 0);
return set.size();
}
public static void go(int index, String[] user_id, String[] banned_id, int bit) {
if(index == banned_id.length) {
set.add(bit);
return;
}
String reg = banned_id[index].replace("*", "[\\w]");
for(int i = 0; i < user_id.length; i++) {
if((((bit >> i) & 1) == 1) ||!user_id[i].matches(reg)) continue;
go(index + 1, user_id, banned_id, (bit | 1<<i));
}
}
public static void main(String[] args) {
String[] user_id = {"frodo", "fradi", "crodo", "abc123", "frodoc"};
String[] banned_id = {"fr*d*", "*rodo", "******", "******"};
solution(user_id, banned_id);
}
}
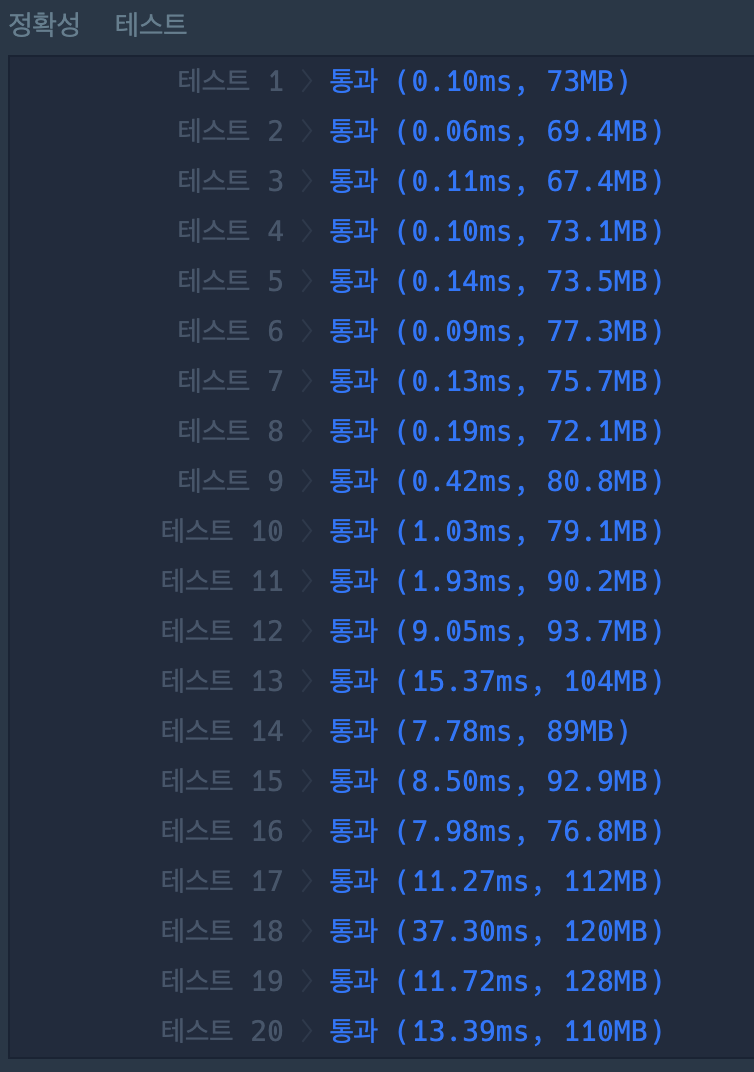
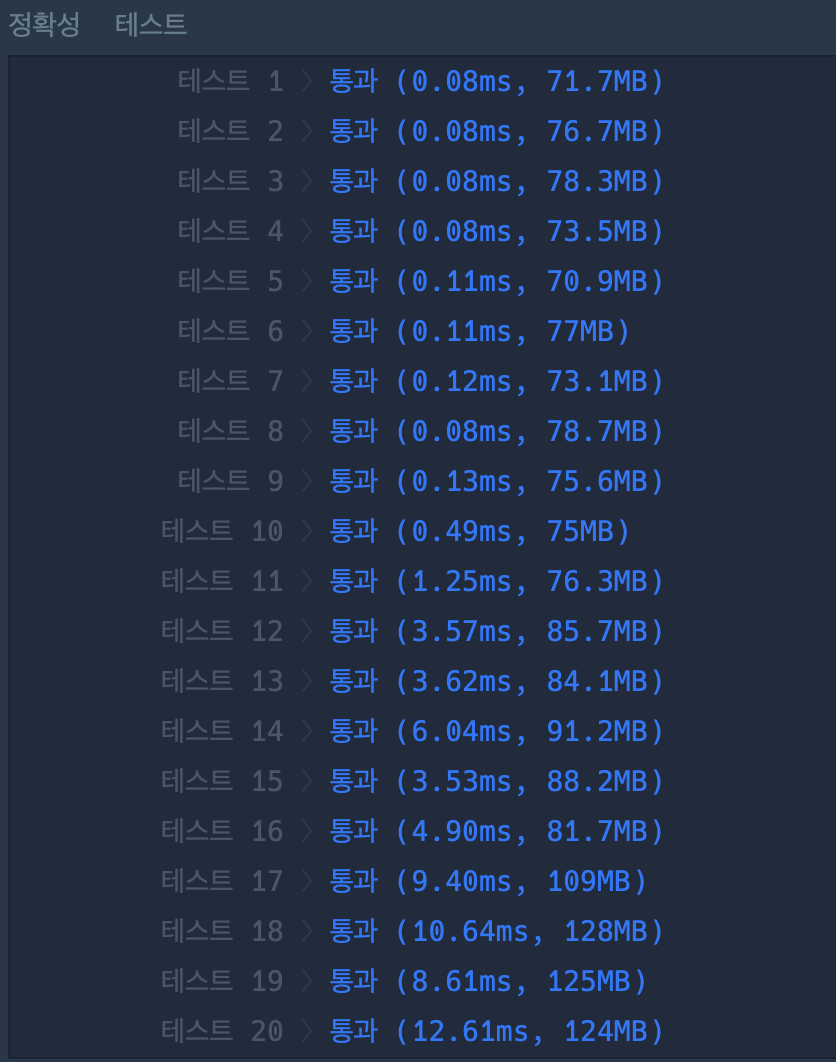
재귀함수와 비트 마스킹의 속도 & 메모리 차이
| 재귀함수 | 비트 마스킹 |
|---|---|
 | 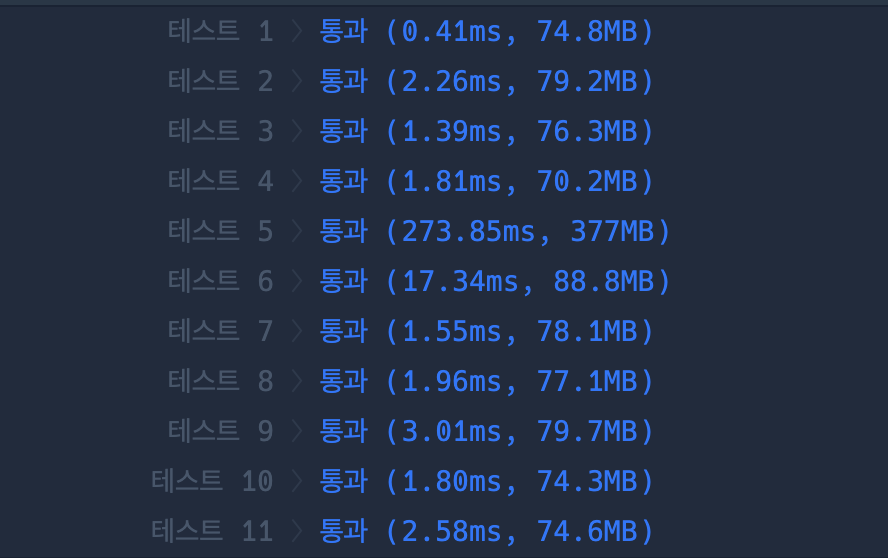 |
즉, 속도면에서는 재귀로 푸는게 훨씬 나은 판단이라고 할 수있다.
보석 쇼핑
문3) 개발자 출신으로 세계 최고의 갑부가 된 어피치는 스트레스를 받을 때면 이를 풀기 위해 오프라인 매장에 쇼핑을 하러 가곤 합니다.
어피치는 쇼핑을 할 때면 매장 진열대의 특정 범위의 물건들을 모두 싹쓸이 구매하는 습관이 있습니다.
어느 날 스트레스를 풀기 위해 보석 매장에 쇼핑을 하러 간 어피치는 이전처럼 진열대의 특정 범위의 보석을 모두 구매하되 특별히 아래 목적을 달성하고 싶었습니다.
진열된 모든 종류의 보석을 적어도 1개 이상 포함하는 가장 짧은 구간을 찾아서 구매
예를 들어 아래 진열대는 4종류의 보석(RUBY, DIA, EMERALD, SAPPHIRE) 8개가 진열된 예시입니다.
| 진열대 번호 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 보석이름 | DIA | RUBY | RUBY | DIA | DIA | EMERALD | SAPPHIRE | DIA |
진열대의 3번부터 7번까지 5개의 보석을 구매하면 모든 종류의 보석을 적어도 하나 이상씩 포함하게 됩니다.
진열대의 3, 4, 6, 7번의 보석만 구매하는 것은 중간에 특정 구간(5번)이 빠지게 되므로 어피치의 쇼핑 습관에 맞지 않습니다.
진열대 번호 순서대로 보석들의 이름이 저장된 배열 gems가 매개변수로 주어집니다. 이때 모든 보석을 하나 이상 포함하는 가장 짧은 구간을 찾아서 return 하도록 solution 함수를 완성해주세요.
가장 짧은 구간의 시작 진열대 번호와 끝 진열대 번호를 차례대로 배열에 담아서 return 하도록 하며, 만약 가장 짧은 구간이 여러 개라면 시작 진열대 번호가 가장 작은 구간을 return 합니다.
제한사항
- gems 배열의 크기는 1 이상 100,000 이하입니다.
- gems 배열의 각 원소는 진열대에 나열된 보석을 나타냅니다.
- gems 배열에는 1번 진열대부터 진열대 번호 순서대로 보석이름이 차례대로 저장되어 있습니다.
- gems 배열의 각 원소는 길이가 1 이상 10 이하인 알파벳 대문자로만 구성된 문자열입니다.
입출력 예
| gems | result |
|---|---|
["DIA", "RUBY", "RUBY", "DIA", "DIA", "EMERALD", "SAPPHIRE", "DIA"] | [3,7] |
["AA", "AB", "AC", "AA", "AC"] | [1,3] |
["XYZ", "XYZ", "XYZ"] | [1,1] |
["ZZZ", "YYY", "NNNN", "YYY", "BBB"] | [1,5] |
입출력 예 설명
입출력 예 #1
- 문제 예시와 같습니다.
입출력 예 #2
- 3종류의 보석(AA, AB, AC)을 모두 포함하는 가장 짧은 구간은 [1, 3], [2, 4]가 있습니다.
시작 진열대 번호가 더 작은 [1, 3]을 return 해주어야 합니다.
입출력 예 #3
- 1종류의 보석(XYZ)을 포함하는 가장 짧은 구간은 [1, 1], [2, 2], [3, 3]이 있습니다.
시작 진열대 번호가 가장 작은 [1, 1]을 return 해주어야 합니다.
입출력 예 #4
- 4종류의 보석(ZZZ, YYY, NNNN, BBB)을 모두 포함하는 구간은 [1, 5]가 유일합니다.
그러므로 [1, 5]를 return 해주어야 합니다.
나의 풀이
package programmers;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
public class JewelryShopping {
public static int[] solution(String[] gems) {
Set<String> gemTypes = new HashSet<>();
Map<String, Integer> gemMap = new HashMap<>();
for(String gem : gems) {
gemTypes.add(gem);
}
int start = 0, end = 0;
int[] answer = {0, gems.length-1};
gemMap.put(gems[0], 1);
while(start < gems.length && end < gems.length) {
if(gemMap.size() == gemTypes.size()) {
if(end - start < answer[1] - answer[0]) {
System.out.printf("start: %d, end: %d\n",start,end);
answer[0] = start;
answer[1] = end;
}
System.out.println(gemMap);
System.out.println(start);
gemMap.put(gems[start], gemMap.get(gems[start]) - 1);
if (gemMap.get(gems[start]) == 0) {
gemMap.remove(gems[start]);
}
start++;
}else {
end++;
if (end == gems.length) break;
gemMap.put(gems[end], gemMap.getOrDefault(gems[end], 0) + 1);
}
}
answer[0] += 1;
answer[1] += 1;
return answer;
}
public static void main(String[] args) {
String[] gems = {"DIA", "RUBY", "RUBY", "DIA", "DIA", "EMERALD", "SAPPHIRE", "DIA"};
solution(gems);
}
}
연속 펄스 부분 수열의 합
문4) 어떤 수열의 연속 부분 수열에 같은 길이의 펄스 수열을 각 원소끼리 곱하여 연속 펄스 부분 수열을 만들려 합니다. 펄스 수열이란 [1, -1, 1, -1 …] 또는 [-1, 1, -1, 1 …] 과 같이 1 또는 -1로 시작하면서 1과 -1이 번갈아 나오는 수열입니다.
예를 들어 수열 [2, 3, -6, 1, 3, -1, 2, 4]의 연속 부분 수열 [3, -6, 1]에 펄스 수열 [1, -1, 1]을 곱하면 연속 펄스 부분수열은 [3, 6, 1]이 됩니다. 또 다른 예시로 연속 부분 수열 [3, -1, 2, 4]에 펄스 수열 [-1, 1, -1, 1]을 곱하면 연속 펄스 부분수열은 [-3, -1, -2, 4]이 됩니다.
정수 수열 sequence가 매개변수로 주어질 때, 연속 펄스 부분 수열의 합 중 가장 큰 것을 return 하도록 solution 함수를 완성해주세요.
제한 사항
- 1 ≤ sequence의 길이 ≤ 500,000
- -100,000 ≤ sequence의 원소 ≤ 100,000
- sequence의 원소는 정수입니다.
입출력 예
| sequence | result |
|---|---|
[2,3,-6,1,3,-1,2,4] | 10 |
입출력 예 설명
- 주어진 수열의 연속 부분 수열 [3, -6, 1]에 펄스 수열 [1, -1, 1]을 곱하여 연속 펄스 부분 수열 [3, 6, 1]을 얻을 수 있고 그 합은 10으로서 가장 큽니다.
나의 풀이
A 방법
package programmers;
public class SumOfContinuousPulseSubsequences {
public static long solution(int[] sequence) {
long answer = Math.max(findMaxPulseSum(sequence,1), findMaxPulseSum(sequence,-1));
return answer;
}
public static long findMaxPulseSum(int[] sequence,int startPulse) {
long maxSoFar = startPulse * sequence[0];
long maxEndingHere = startPulse * sequence[0];
int pulse = startPulse;
for(int i = 1; i < sequence.length; i++) {
pulse *= -1;
long currentVal = pulse * sequence[i];
maxEndingHere = Math.max(currentVal, maxEndingHere + currentVal);
maxSoFar = Math.max(maxSoFar, maxEndingHere);
}
return maxSoFar;
}
public static void main(String[] args) {
int[] sequence = {2, 3, -6, 1, 3, -1, 2, 4};
solution(sequence);
}
}
B 방법
package programmers;
public class SumOfContinuousPulseSubsequences {
public static long solution(int[] sequence) {
long answer = Math.max(findMaxPulseSum(sequence,1), findMaxPulseSum(sequence,-1));
System.out.println(answer);
return answer;
}
public static long findMaxPulseSum(int[] sequence,int startPulse) {
long maxSoFar = 0;
long maxEndingHere = 0;
int pulse = startPulse;
for(int i = 0; i < sequence.length; i++) {
pulse *= -1;
long currentVal = pulse * sequence[i];
maxEndingHere += currentVal;
if(maxEndingHere < 0) maxEndingHere = 0;
if(maxSoFar < maxEndingHere) maxSoFar = maxEndingHere;
}
return maxSoFar;
}
public static void main(String[] args) {
int[] sequence = {2, 3, -6, 1, 3, -1, 2, 4};
solution(sequence);
}
}
나의 생각
카데인 알고리즘(Kadane's Algorithm)
카데인 알고리즘이라는 용어를 처음들어보고 이를 좀더 파헤쳐보기로 했다.
A방법과 B방법에 대한 자세한 내용을 👉🏻 카데인 알고리즘 에서 확인할 수 있다.
| A 방법 | B 방법 |
|---|---|
 |  |
징검다리 건너기
문5) 카카오 초등학교의 "니니즈 친구들"이 "라이언" 선생님과 함께 가을 소풍을 가는 중에 징검다리가 있는 개울을 만나서 건너편으로 건너려고 합니다. "라이언" 선생님은 "니니즈 친구들"이 무사히 징검다리를 건널 수 있도록 다음과 같이 규칙을 만들었습니다.
- 징검다리는 일렬로 놓여 있고 각 징검다리의 디딤돌에는 모두 숫자가 적혀 있으며 디딤돌의 숫자는 한 번 밟을 때마다 1씩 줄어듭니다.
- 디딤돌의 숫자가 0이 되면 더 이상 밟을 수 없으며 이때는 그 다음 디딤돌로 한번에 여러 칸을 건너 뛸 수 있습니다.
- 단, 다음으로 밟을 수 있는 디딤돌이 여러 개인 경우 무조건 가장 가까운 디딤돌로만 건너뛸 수 있습니다.
"니니즈 친구들"은 개울의 왼쪽에 있으며, 개울의 오른쪽 건너편에 도착해야 징검다리를 건넌 것으로 인정합니다.
"니니즈 친구들"은 한 번에 한 명씩 징검다리를 건너야 하며, 한 친구가 징검다리를 모두 건넌 후에 그 다음 친구가 건너기 시작합니다.
디딤돌에 적힌 숫자가 순서대로 담긴 배열 stones와 한 번에 건너뛸 수 있는 디딤돌의 최대 칸수 k가 매개변수로 주어질 때, 최대 몇 명까지 징검다리를 건널 수 있는지 return 하도록 solution 함수를 완성해주세요.
제한사항
- 징검다리를 건너야 하는 니니즈 친구들의 수는 무제한 이라고 간주합니다.
- stones 배열의 크기는 1 이상 200,000 이하입니다.
- stones 배열 각 원소들의 값은 1 이상 200,000,000 이하인 자연수입니다.
- k는 1 이상 stones의 길이 이하인 자연수입니다.
입출력 예
| stones | k | result |
|---|---|---|
| [2, 4, 5, 3, 2, 1, 4, 2, 5, 1] | 3 | 3 |
입출력 예 설명
입출력 예 #1
첫 번째 친구는 다음과 같이 징검다리를 건널 수 있습니다.
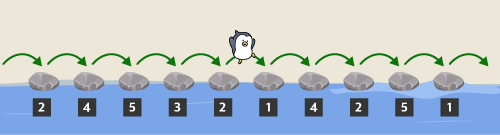
첫 번째 친구가 징검다리를 건넌 후 디딤돌에 적힌 숫자는 아래 그림과 같습니다.
두 번째 친구도 아래 그림과 같이 징검다리를 건널 수 있습니다.
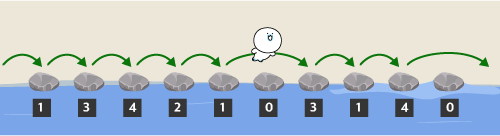
두 번째 친구가 징검다리를 건넌 후 디딤돌에 적힌 숫자는 아래 그림과 같습니다.
세 번째 친구도 아래 그림과 같이 징검다리를 건널 수 있습니다.
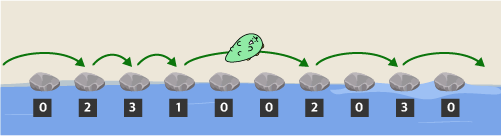
세 번째 친구가 징검다리를 건넌 후 디딤돌에 적힌 숫자는 아래 그림과 같습니다.
네 번째 친구가 징검다리를 건너려면, 세 번째 디딤돌에서 일곱 번째 디딤돌로 네 칸을 건너뛰어야 합니다. 하지만 k = 3 이므로 건너뛸 수 없습니다.
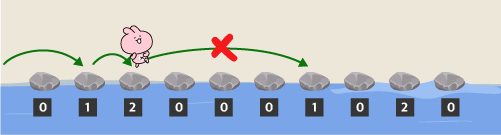
따라서 최대 3명이 디딤돌을 모두 건널 수 있습니다.
나의 풀이
package programmers;
import java.util.Arrays;
public class CrossTheSteppingStones {
public static int solution(int[] stones, int k) {
int left = 0;
int right = Arrays.stream(stones).max().getAsInt();
while(left <= right) {
int mid = (left + right) / 2;
if(canCross(stones, k, mid)) {
left = mid + 1;
}else {
right = mid - 1;
}
}
return right;
}
public static boolean canCross(int[] stones, int k, int mid) {
int count = 0;
for(int stone : stones) {
if(stone - mid < 0) {
count++;
}else {
count = 0;
}
if(count == k) return false;
}
return true;
}
public static void main(String[] args) {
int[] stones = {2, 4, 5, 3, 2, 1, 4, 2, 5, 1};
solution(stones, 3);
}
}
나의 생각
입출력 범위 조건을 보면 stones 배열의 크기가 최대 200,000이고, 각원소의 값이 최대 200,000,000이기때문에 이러한 큰 입력 범위는 단순한 반복문으로 시간 내에 해결할 수 없을 것이라고 판단하였다.
하지만, 뾰족한 방법은 떠오르지않아 찾아보니, 이진 탐색으로 접근해야하는 문제였다.
이 문제는 최대 몇 명까지 징검다리를 건널 수 있는가?와 같은 최적화 문제로, 이진 탐색은 결정문제에 대한 답을 빠르게 찾기 위해 사용될 수있다. 이진 탐색은 O(log N)의 시간 복잡도를 가지며, 대규모 데이터에서 해를 빠르게 찾을 수 있어 문제의 큰 입력 범위에 적합하다.
이진탐색의 과정
1. 배열의 중앙값을 찾는다.
2. 중앙값이 찾고자 하는 값과 같은지 비교한다.
3. 만약 중앙값이 찾고자 하는 값보다 크다면, 찾고자 하는 값은
중앙값의 왼쪽에 있을 것, 그렇지 않다면 오른쪽에 있을 것
4. 찾고자 하는 값이 있는 배열의 절반을 선택하고 나머지 절반은 무지
5. 선택된 절반에 대해 다시 중앙값을 찾고 위의 과정을 반복
left변수는 가장 작은 0을,right 변수는 배열에서 가장 큰 값을 넣는다.
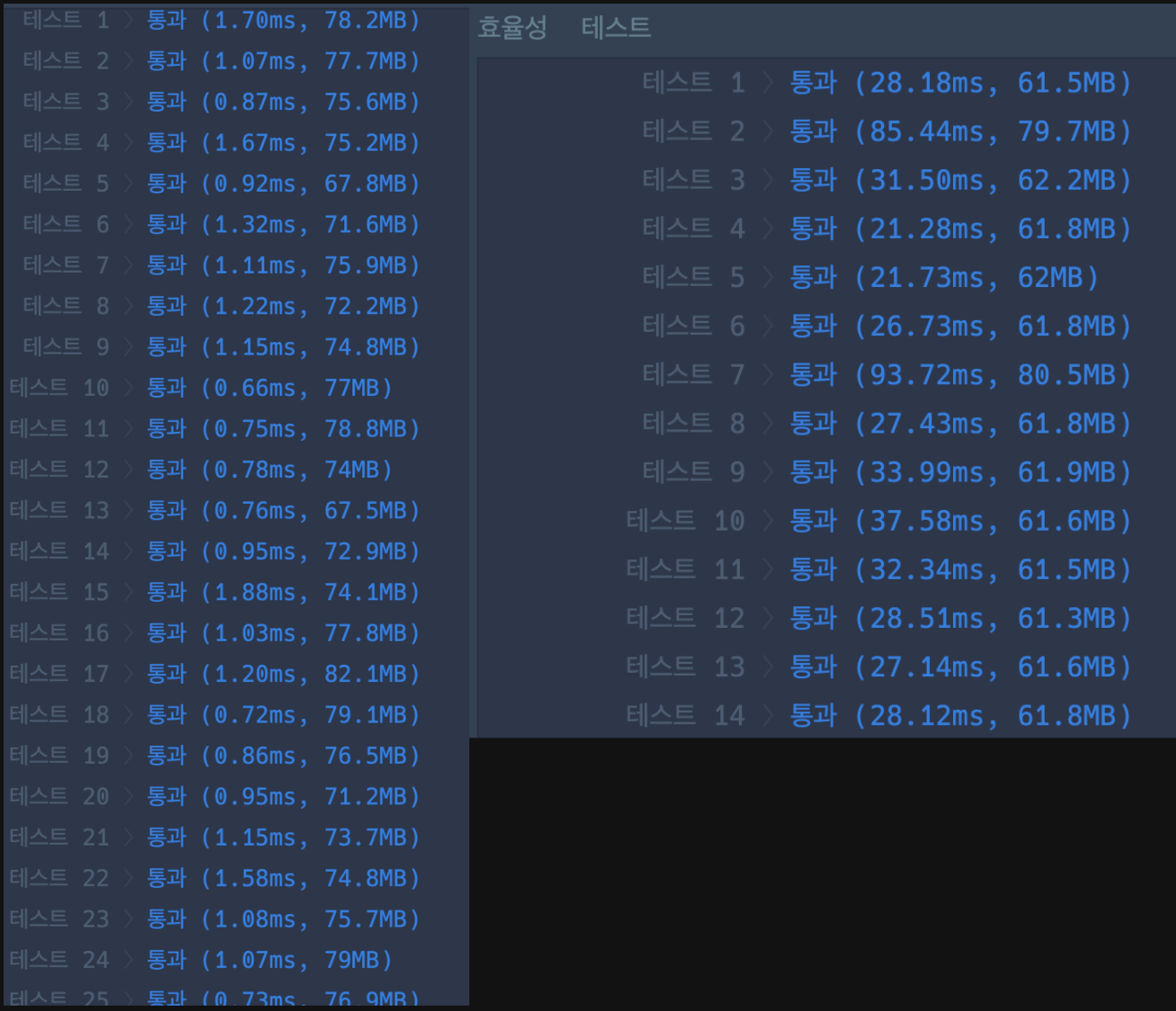
배열에 든 값 중에 가장 큰 값을 뽑아내는 방법이 여러가지가 있지만, 나는 stream()을 사용하였다. 하지만 여기서 의문이 하나 들었는데, stream으로 최대값을 찾는게 빠를까, 단순 반복문을 이용하여 최대값을 찾는게 빠를까 비교해보기로 하였다.
| stream()을 사용한 방법 | 단순 반복문을 사용한 방법 |
|---|---|
 | 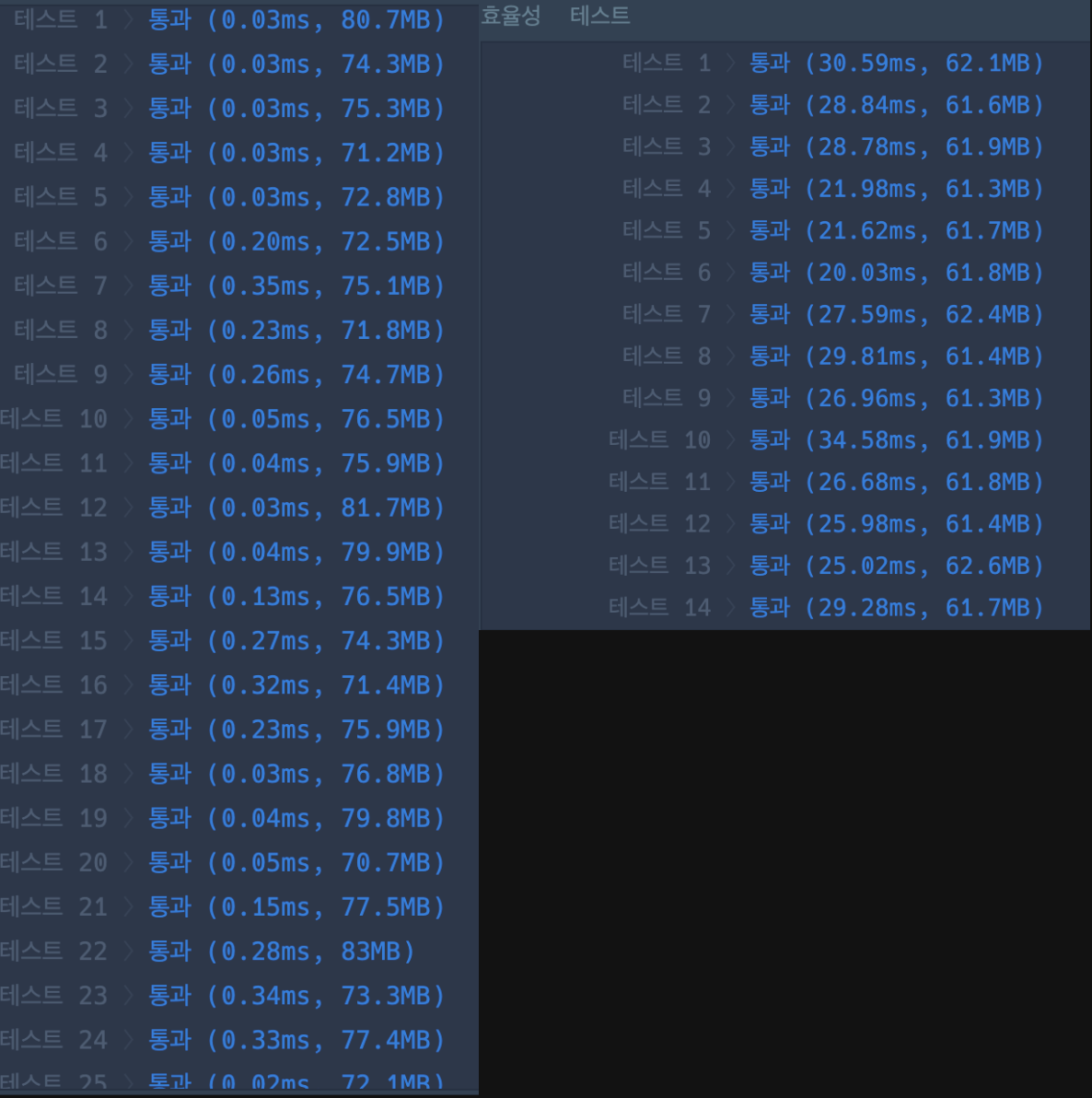 |
단순 반복문을 사용한 결과가 stream() 보다 빠른 이유?
- 오버헤드 : Stream().max()는 내부적으로 스트림을 생성하고, 각 요소에 대한 연산을 수행하는 오버헤드가 있음. 이 과정에서 박싱(Boxing)과 언박싱(Unboxing)이 발생할 수 있으며, 함수 호출과 같은 추가적인 작업이 필요할 수 있음
- 최적화 : 컴파일러와 JVM(Java Virtual Machine)은 for문과 같은 기본적인 구조의 최적화가 잘됨. 이는 루프 언롤링(loop unrolling)과 같은 기법을 포함하여 메모리 접근과 연산을 최적화함
루프 언롤링이 뭐지...?
- 프로그램의 실행 속도를 향상시키기 위한 컴파일러 최적화 기법 중 하나. 이 기법은 반복문 내의 반복되는 코드를 여러 번 복사하여 루프의 반복 횟수를 줄이는 방식으로, 반복문의 오버헤드를 감소시키고 프로그램의 실행 속도를 향상시키는 데 도움이 됨
| 일반 반복문 | 루프 언롤링 적용 반복문 |
|---|---|
 |  |
전형적인 이진탐색 알고리즘

핵심 로직
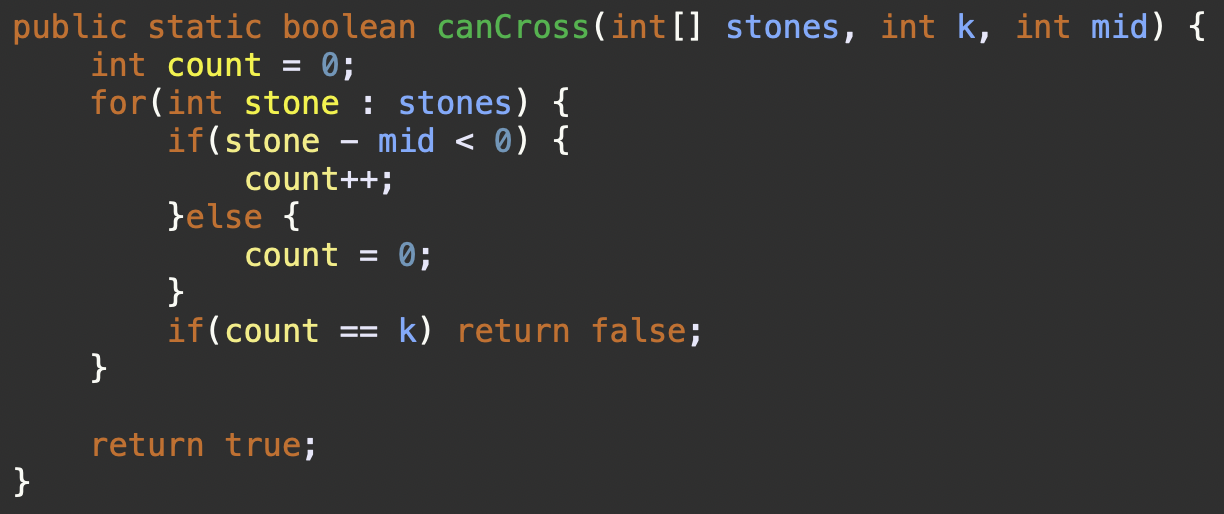
count++는 연속된 0 이하의 돌이 나타날 때마다 증가하는데, 이것은mid명의 친구들이 건너려고 할 때 연속해서 건널 수 없는 돌의 개수를 측정함- else절에서
count = 0으로 설정하는 것은 연속성을 끊고 카운트를 리셋하는 것. 즉, 하나라도 건널 수 있는 돌이 나타나면, 그 지점에서 연속되는 0 이하의 돌이 나타나지 않았다는 것을 의미하므로, 건널 수 없는 돌의 연속 카운트를 다시 시작해야 함
👉🏻 연속되는 돌의 개수가 중요하기 때문에, 이 연속성이 끊어질 때마다 카운트를 0으로 리셋하는 것
