[Pandas & Scikit-learn] 금융공학 입문 2 - 데이터 분석
0
2025.1.22 작성
OS : Window
개발환경: Google Colab
개발언어: Python
프레임워크: Pandas (데이터 전처리 및 관리), Scikit-learn (머신러닝 분석 및 모델링)
adv.csv --> df1
sales가 y
tv, radio, 신문x
tv X
.shape
import pandas as pd
df1 = pd.read_csv("adv.csv")
df1.sales.shape
df1.shape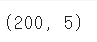
df1.TV.shape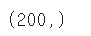
df1[["TV"]].shape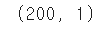
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(df1[["TV"]][0:180], df1.sales[0:180])
# print(model.coef_, model.intercept_)
print(model.predict(df1[["TV"]][180:]))
print(df1.sales[180:])
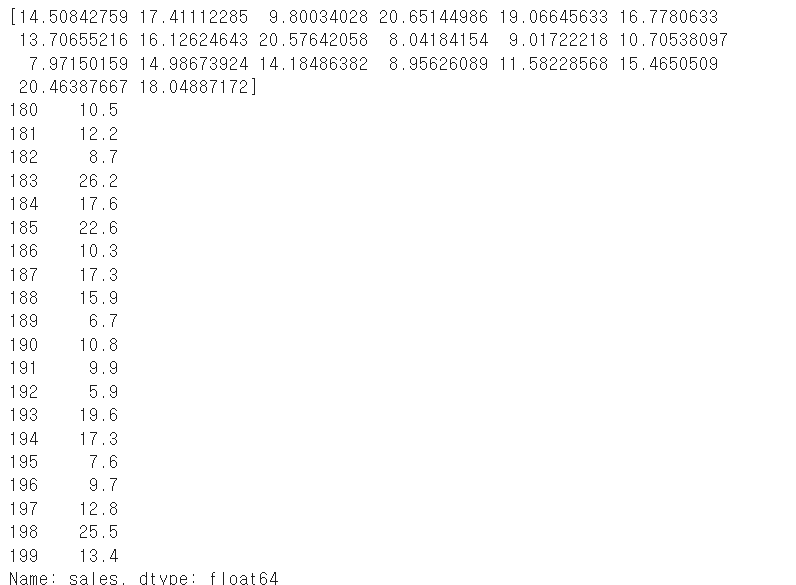
선형 회귀 분석(Linear Regression)
1) ((pred - test.sales)**2).mean()
MSE는 예측값(pred)과 실제값(test.sales) 간의 차이를 측정하는 평가 지표
2) root_mean_squared_error(test.sales, pred)
RMSE (Root Mean Squared Error, 루트 평균 제곱 오차)를 계산하는 함수 호출
RMSE란?
RMSE는 MSE의 단위를 원래 데이터 단위로 맞추기 위해 제곱근을 취한 값
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
train, test = train_test_split(df1, train_size=0.9)
model = LinearRegression()
model.fit(train[["TV"]], train.sales)
# print(model.coef_, model.intercept_)
# 결과는 랜덤하게 하기 때문에 숫자가 다를 수 있음
# print(model.predict(test[["TV"]]))
# print(test.sales)
pred = model.predict(test[["TV"]])
from sklearn.metrics import root_mean_squared_error
root_mean_squared_error(test.sales, pred) #RMSE
((pred - test.sales)**2).mean() #MSE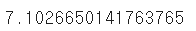
파티셔닝 7:3
radio와 sales 직선식
testing에 대해 RMSE
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
train, test = train_test_split(df1, train_size=0.7)
model = LinearRegression()
model.fit(train[["radio", "TV"]], train.sales)
# print(model.coef_, model.intercept_)
# 결과는 랜덤하게 하기 때문에 숫자가 다를 수 있음
# print(model.predict(test[["TV"]]))
# print(test.sales)
pred = model.predict(test[["radio", "TV"]])
from sklearn.metrics import root_mean_squared_error
root_mean_squared_error(test.sales, pred) #RMSE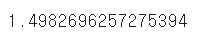
다른 것들 응용하기 좋은 버전
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df1[["TV", "radio"]], df1.sales, train_size=0.7)
model = LinearRegression()
model.fit(X_train, y_train)
# print(model.coef_, model.intercept_)
# 결과는 랜덤하게 하기 때문에 숫자가 다를 수 있음
# print(model.predict(test[["TV"]]))
# print(test.sales)
pred = model.predict(X_test)
from sklearn.metrics import root_mean_squared_error
root_mean_squared_error(y_test, pred) #RMSE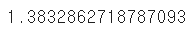

벨로그 쫌 재밌네?