[Machine Learning] 금융공학 입문 3 - 데이터 분석
0
2025.1.23 작성
OS : Window
개발환경: Google Colab
개발언어: Python
프레임워크: scikit-learn, pandas
데이터(creditset2.csv)를 기반으로 신용 상태(디폴트 여부)를 예측하는 결정 트리 모델을 만들고, 학습 결과를 트리 구조로 시각화하여 이해하기 쉽게 표현합니다.
creditset2.csv
--> 신용 데이터
default... :y
age, loan, income :x
--> age(나이), loan(대출 금액), income(수입)
import pandas as pd
df1 = pd.read_csv("creditset2.csv")
y = df1.default10yr
X = df1[["age", "loan", "income"]]
# 결정 트리 분류 모델
from sklearn.tree import DecisionTreeClassifier, plot_tree
model = DecisionTreeClassifier()
model.fit(X,y)
plot_tree(model)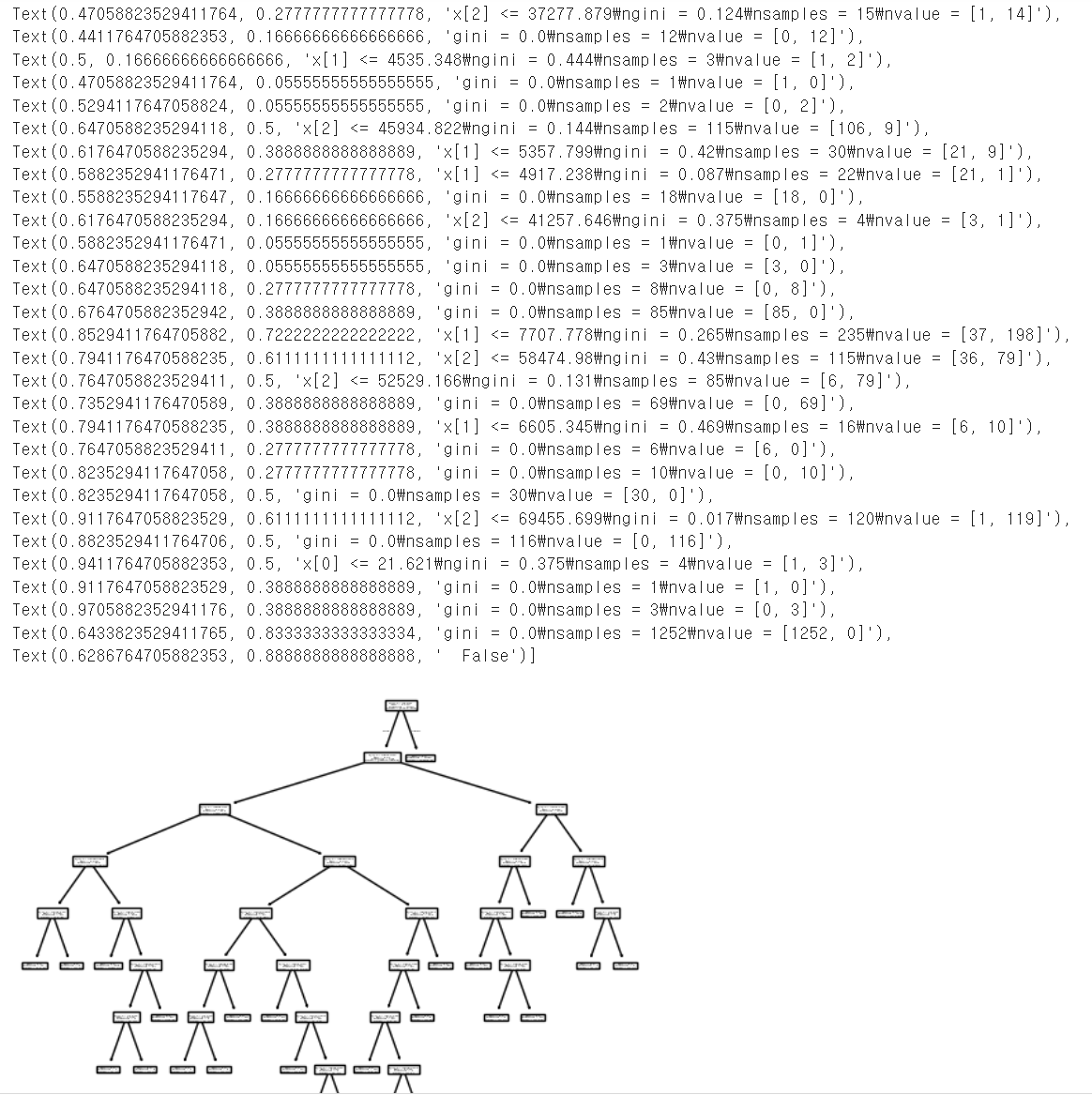
85:15 파티셔닝, train으로 학습
import pandas as pd
from sklearn.model_selection import train_test_split
df1 = pd.read_csv("creditset2.csv")
y = df1.default10yr
X = df1[["age", "loan", "income"]]
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.85)
# 결정 트리 분류 모델
from sklearn.tree import DecisionTreeClassifier, plot_tree
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# plot_tree(model)
(y_test == model.predict(X_test)).mean() # 정분류율, Accuracy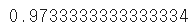
더 자세한 결과 보기
import pandas as pd
from sklearn.model_selection import train_test_split
df1 = pd.read_csv("creditset2.csv")
y = df1.default10yr
X = df1[["age", "loan", "income"]]
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.85)
# 결정 트리 분류 모델
from sklearn.tree import DecisionTreeClassifier, plot_tree
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# plot_tree(model)
(y_test == model.predict(X_test)).mean() # 정분류율, Accuracy
from sklearn.metrics import classification_report
print(classification_report(y_test, model.predict(X_test)))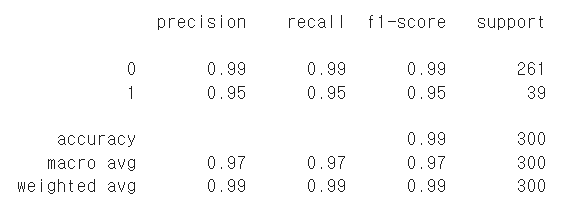
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.85, random_state=123, stratify=y)
print(y_train.value_counts()/1700)
print(y_test.value_counts()/300)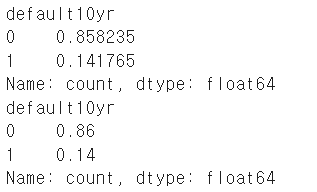

벨로그 쫌 재밌네?