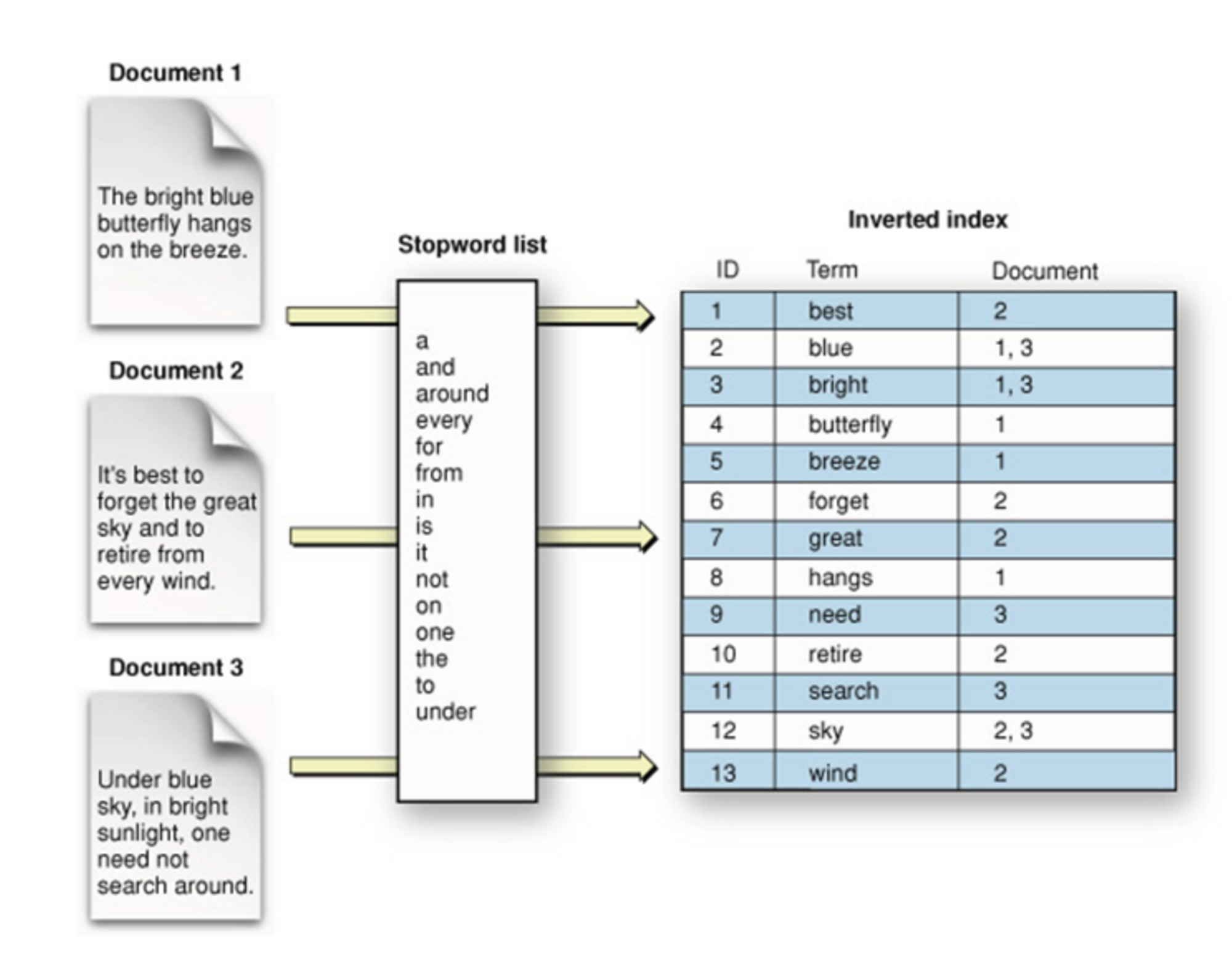
Full Text Index
긴 문자의 텍스트 데이터를 빠르게 검색하기 위한 MySQL의 부가적인 기능
일반 익덱스와 차이로는, 풀텍스트 인덱스는 긴 문장 전체를 대상으로 인덱싱을 하며, InnoDB와 MyISAM 테이블만 지원하며, char, varchar, text타입 문자만 인덱싱이 가능하며 여러개의 열에 풀텍스트 인덱스 지정 가능
Full-text Index 인덱싱 기법
다음 두 가지 종류의 parser를 이용하여 인덱스를 구축
Built-in parser또는Stop-word parser
- Stop-word 기법을 사용하는 기본 내장 파서
- Stop-word가 나타났을 때를 기준으로 토큰을 나눔

- index 추가 구문
ALTER TABLE 테이블명 ADD FULLTEXT INDEX 인덱스명(문자컬럼1, 문자컬럼2);N-gram parser
- 기본 InnoDB 전문 검색(Full Text) 파서는 공백이나 단어 분리자가 토큰인 라틴 기반 언어들에서는 이상적이지만 개별 단어에 대한 고정된 구분자가 없는 CJK(중국어, 일본어, 한국어) 같은 언어들에서는 각 단어는 여러개의 문자들의 조합으로 이루어짐 이러한 단어 토큰들을 처리할 수 있도록 mysql에서 제공하는 새로운 플러그블 전문 파서
- n-gram 기법을 사용하여 할당한 토큰의 크기 n만큼씩 데이터를 인덱스로 파싱해두었다 사용하는 파서

ngram Parser Stopword Handling: Stop-word 처리도 조금 다름.
일반적으로 토큰화된 단어 자체(완전히 일치)가 Stop-word 테이블에 있다면 그 단어는 전문 검색 인덱스에 추가되지 않았음. n-gram 파서의 경우, 토큰화된 단어에 Stop-word가 포함되어 있는지 확인하고 포함된 경우엔 토큰 제외
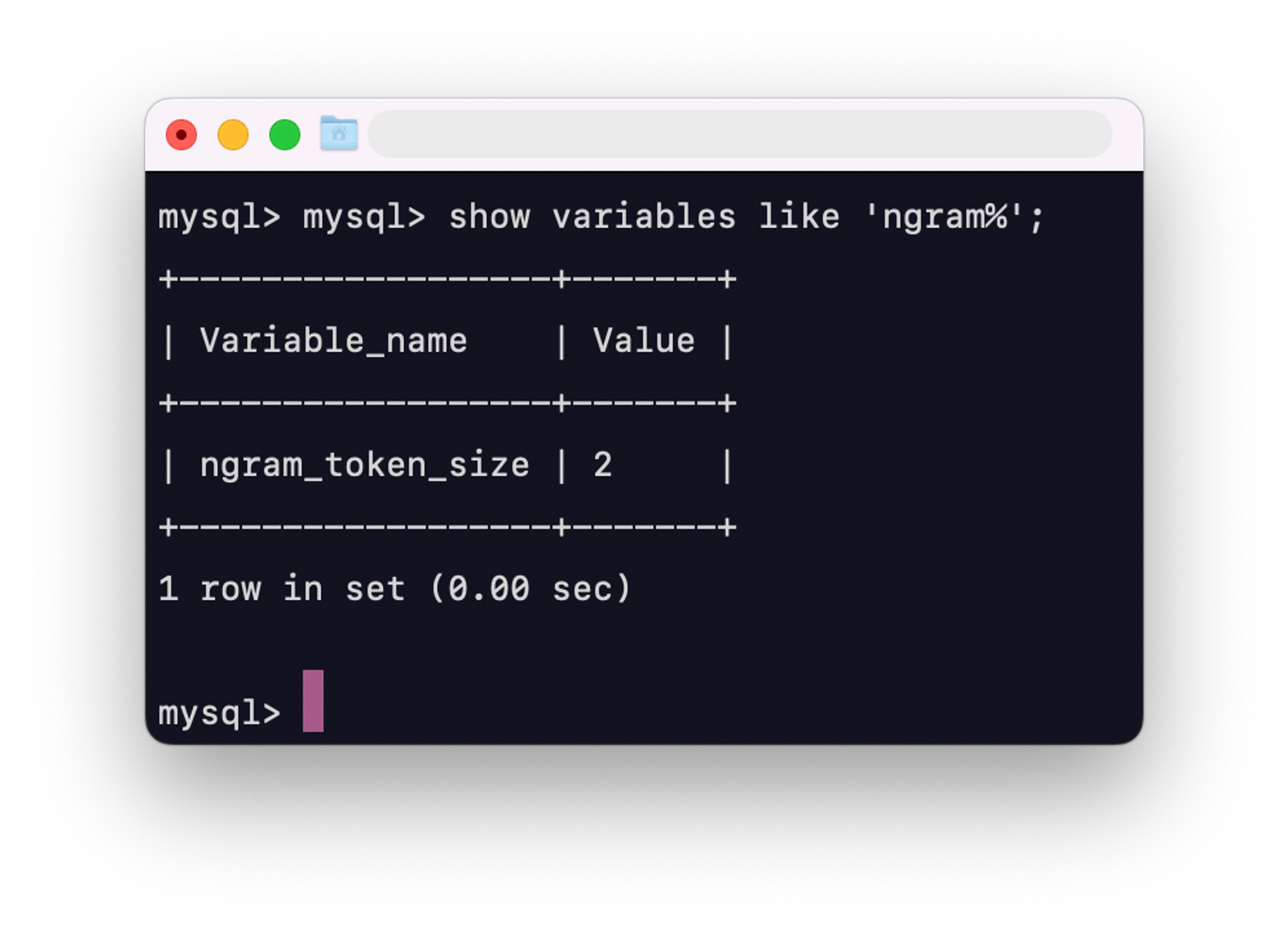
ex) ngram_token_size = 2라고 가정, "a,b"가 포함 된 문서는 "a," 와 ",b" 로 구문 분석 됨. 쉼표 ( ",")가 Stop-word로 정의 된 경우 "a," 와 ",b" 는 모두 쉼표를 포함하므로 색인에서 제외
⇒ 이를 고려하여 Stop-word 설정
ngram Parser Space Handling: 공백은 항상 하드 코드된 stopwords 임으로 공백을 제거.
예를 들면, ‘my sql’는 항상 ‘my’, ‘y’, ‘s’, ‘sq’, ‘ql’로 토큰화되어지고 ‘y’와 ‘s’는 인덱싱되지 않음
- index 추가 구문
ALTER TABLE 테이블명 ADD FULLTEXT INDEX 인덱스명(문자컬럼1, 문자컬럼2) WITH PARSER ngram;Full-text Search 검색 쿼리
select * FROM 테이블명 WHERE MATCH (col1,col2,col3...) AGAINST (expr [search_modifier])search_modifier 종류
- 자연어 검색(natural search):
- 검색 단어 중 하나라도 포함되는 행, 단어가 정확한 것을 검색
- ex) ‘영화’ 검색시 ‘영화는’, ‘영화가’ 등 능동적인 검색 불가
- 위의 쿼리 [search_modifier] 위치에 특별 옵션을 지정하지 않거나 in natural language mode 지정
- 불린 모드 검색(Boolean mode search):
- 해당 단어가 포함되는 행을 찾는 규칙을 추가적으로 적용하여 해당 규칙에 매칭되는 행을 찾음.
- 검색의 정확도에 따라 결과가 정렬되지는 않음.
- 위의 쿼리 [search_modifier] 위치에 in boolean mode 지정
- 구문 검색 가능. 필수(+), 예외(-), 부분(*), 구문(” ”) 연산자를 사용할 수 있음
기호 뜻 예시 (~: select * from newspaper) 설명 + 검색 필수 ~ WHERE MATCH(article) AGAINST('영화 +액션' IN BOOLEAN MODE); 영화를 찾되 반드시 액션이 들어가 있는 경우 - 검색 제외 WHERE MATCH(article) AGAINST('영화 -액션' IN BOOLEAN MODE); 영화를 찾되 액션은 안들어가는 경우 ~ 검색 부정 WHERE MATCH(article) AGAINST('영화 ~액션' IN BOOLEAN MODE); ‘영화’를 찾되 ‘액션’이 없는 경우 보다 ‘액션’이 있는 경우가 아래 순위 * 부분 검색 WHERE MATCH(article) AGAINST('영화*' IN BOOLEAN MODE); ‘영화를’, ‘영화가’, ‘영화는’ 등 “ 부분 검색 일치 WHERE MATCH(article) AGAINST("재밌는 영화" IN BOOLEAN MODE); 부분 검색 “” 안에 있는 구문과 정확히 동일한 철자의 구문 ex) “재밌는 영화”, “재밌는 영화가” 등 검색 가능하나 “재밌는 한국 영화”, “재밌는 할리우드 영화” 불가
- 쿼리 확장 검색(query extension search):
- 2단계에 걸쳐 검색을 수행. 첫 단계에서는 자연어 검색을 수행한 후, 첫 번째 검색의 결과에 매칭된 행을 기반으로 검색 문자열을 재구성하여 두번째 검색을 수행.
- 이는 1단계 검색에서 사용한 단어와 연관성이 있는 단어가 1단계 검색에 매칭된 결과에 나타난다는 가정을 전제로 함
- 위의 쿼리 [search_modifier] 위치에 WITH query expansion 지정
검색 속도 비교
1. 기본 Full-text VS n-gram parser Full-text
Test 환경
비교 사항
| 테이블 | 인덱스 | 카디널리티 |
|---|---|---|
| product_full_text | stop-word parser 적용 full-text index | 1759226 |
| product_full_text_n | N-gram parser 적용 full-text index | 0 |
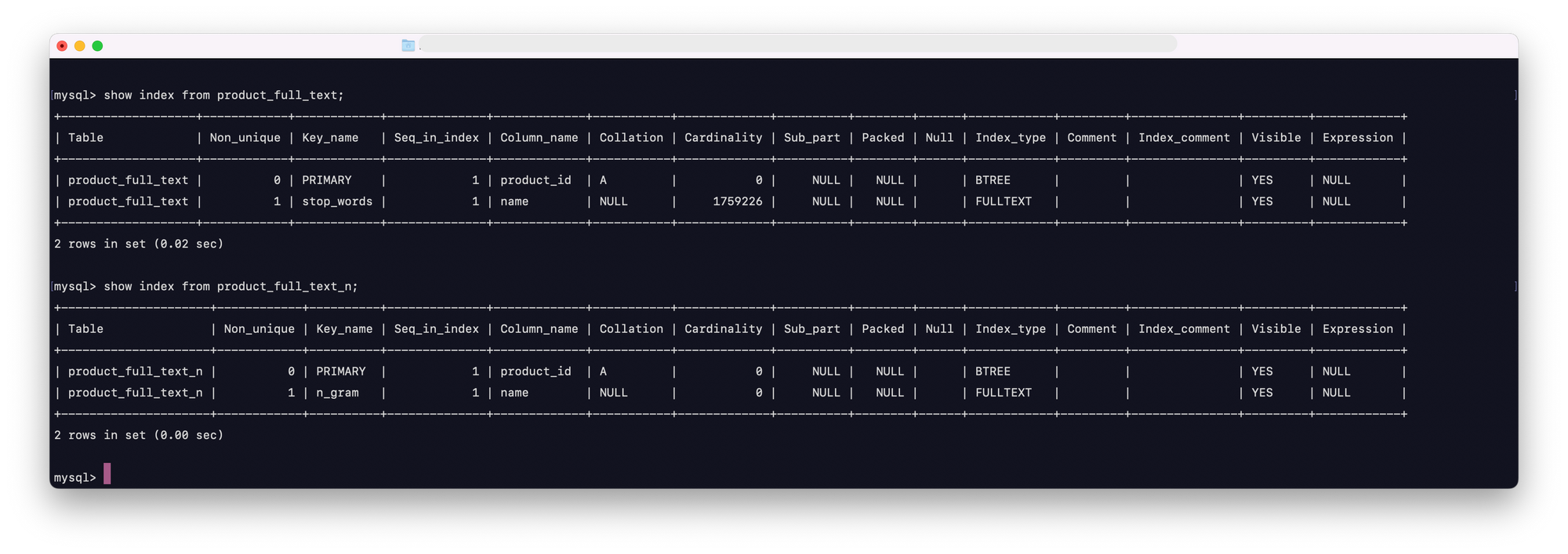
- product_full_text 테이블
Built-in parser인 경우: offset 370
select product_id, name, price, img from product_full_text where match(name) AGAINST("운동화*") order by price, product_id limit 370, 21;
- product_full_text_n 테이블
N-gram인 경우: offset 500
select product_id, name, price, img from product_full_text_n where match(name) AGAINST("운동화*" IN BOOLEAN MODE) order by price, product_id limit 500, 21;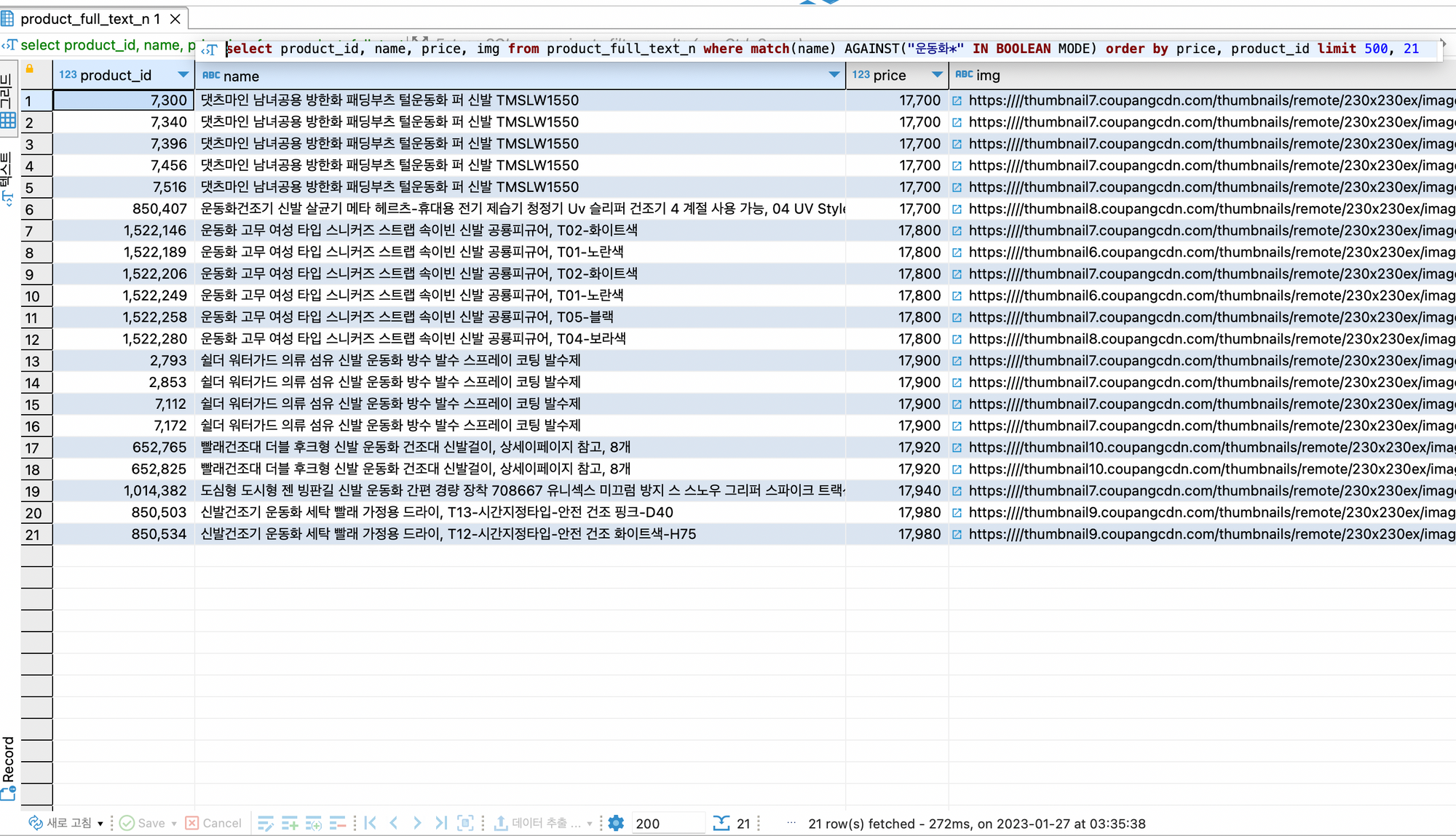
parser 차이에 따라 offset을 다르게 검색한 이유: 같은 가격대에 결과를 비교해 보기 위함
둘의 결과를 비교해보면, Built-in parser 일 때 N-gram에서 검색되는 털운동화 부분이 빠져 검색됨을 통해 검색어인 운동화와 일치한 단어들만 검색됨을 확인.
N-gram 인 경우 더 많은 검색 결과가 포함되며, 검색 결과인 털운동화를 통해 ‘%word’와 같은 검색이 됨을 확인
*offset 500일 때의 속도 비교
| 횟수 | Built-in parser | N-gram parser |
|---|---|---|
| 1 | 71 ms | 309 ms |
| 2 | 63 ms | 420 ms |
| 3 | 55 ms | 364 ms |
💡 결론
parser 차이에 따라 검색되는 데이터가 달라짐을 직접 확인해 보았다. 다음 테스트는 한국어 검색에 적합한 n-gram parser만을 통해 깊이 파보고자 한다.
n-gram parser 적용 Test
최종적으로 n-gram parser를 사용한 full text index를 적용하고자 한다.
그 이유는 n-gram parser가 한국어 검색에 더욱 적합하기 때문이다.
n = 2로 진행한다.
- 테이블 생성 및 ngram-parser full text index 적용
create TABLE product_ngram(
product_id BIGINT NOT NULL PRIMARY KEY AUTO_INCREMENT,
img VARCHAR(255) NOT NULL, on_sale bit(1) NOT NULL,
price BIGINT NOT NULL, name TEXT NOT NULL,
sales INT NOT NULL, stock INT NOT NULL,
FULLTEXT INDEX ngram_idx(name) WITH PARSER ngram
) Engine=InnoDB CHARACTER SET utf8mb4;- innodb_ft_aux_table 구성 변수 설정
- InnoDB INFORMATION_SCHEMA FULLTEXT 인덱스 테이블MySQL 5.6.4에서 `InnoDB`테이블의 `FULLTEXT`인덱스 지원의 도입으로 `INFORMATION_SCHEMA` 데이터베이스에 다음 테이블이 추가
- INNODB_FT_DEFAULT_STOPWORD:
FULLTEXT인덱스를 만들 때 기본적으로 사용되는 중지 단어 목록을 유지 - INNODB_FT_INDEX_TABLE:
FULLTEXT인덱스에 대한 텍스트 검색을 처리하는 데 사용되는 역 인덱스에 대한 데이터가 포함되어 있음 - INNODB_FT_INDEX_CACHE:
FULLTEXT인덱스에 새로 삽입 된 행에 대한 토큰 정보가 포함되어 있음. DML 작업 중 부하가 큰 인덱스 재구성을 피하기 위해 새로 인덱싱 된 단어에 대한 정보는 별도로 저장되며OPTIMIZE TABLE의 실행시 서버가 종료 될 때 또는 캐시 크기가innodb_ft_cache_size과innodb_ft_total_cache_size에서 정의 된 제한을 초과하는 경우에만 기본 검색 인덱스와 결합됨
참고) INNODB_FT_INDEX_TABLE 테이블은 InnoDB 테이블의 FULLTEXT 인덱스에 대한 텍스트 검색을 처리하는데 사용되는 역 인덱스에 대한 정보를 제공.
이 테이블은 처음에는 비어 있으니, 쿼리하기 전 innodb_ft_aux_table 시스템 변수의 값을 FULLTEXT 인덱스를 포함하는 테이블의 이름(데이터베이스 이름 포함)으로 설정해야 함
SET GLOBAL innodb_ft_aux_table = 'hanbange/product_ngram';*RDS에서는 aws에 접속하여 hanbange라는 파라미너 그룹을 새로 생성 후 설정을 바꾸고 DB의 파라미터 그룹을 hanbange로 지정함으로써 연결을 해주어서 이 과정을 진행하지 않아도 된다!
- 인덱스 확인
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_TABLE limit 20;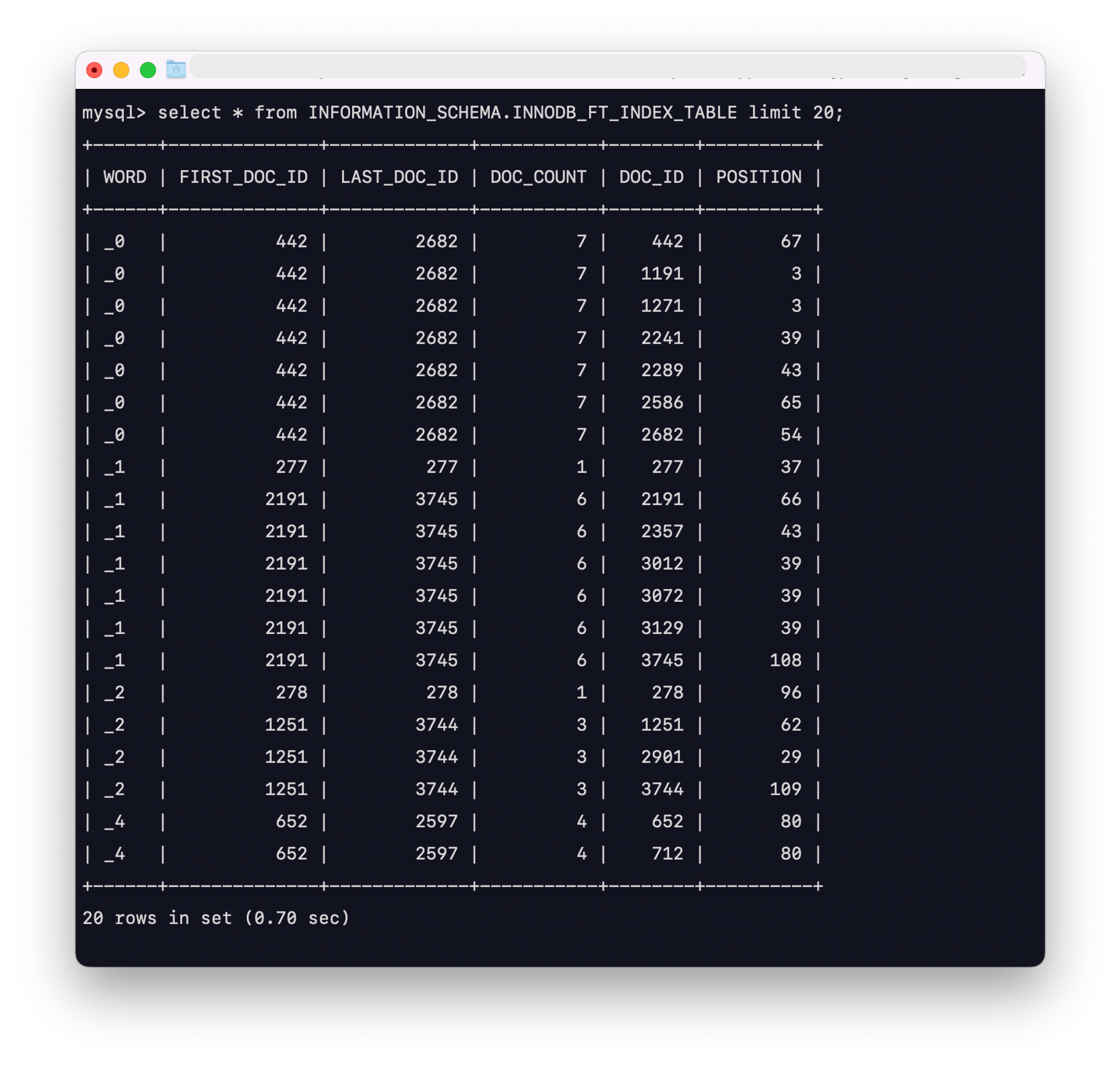
| 컬럼이름 | 설명 |
|---|---|
| WORD | A word extracted from the text of the columns that are part of a FULLTEXT. |
| FIRST_DOC_ID | The first document ID in which this word appears in the FULLTEXT index. |
| LAST_DOC_ID | The last document ID in which this word appears in the FULLTEXT index. |
| DOC_COUNT | The number of rows in which this word appears in the FULLTEXT index. The same word can occur several times within the cache table, once for each combination of DOC_ID and POSITION values. |
| DOC_ID | The document ID of the row containing the word. This value might reflect the value of an ID column that you defined for the underlying table, or it can be a sequence value generated by InnoDB when the table contains no suitable column. |
| POSITION | The position of this particular instance of the word within the relevant document identified by the DOC_ID value. |
불 필요한 인덱스들이 생성된 것을 확인할 수 있으며, 이를 위해 중지 단어를 추가한 테이블을 만들어 설정해 주었다.
CREATE TABLE user_stopword (value VARCHAR(30));insert into user_stopword values ('_'), (','), ('!'), ('['), (']'), ('.'), ('*'), ('/'), ('@'), ('|'), ('❤'), ('✿'), ('°'), ('★'), ('○'), ('®');set global innodb_ft_server_stopword_table = 'hanbange/user_stopword';- 변경내역 확인
show variables like 'innodb_ft%';
변경이 잘 된 것을 확인할 수 있다!
stop words를 설정 해준 후, 새로 DB를 만들고 full-text index를 설정 후 데이터를 넣어주는 작업을 거쳐야 적용이 된다.
SELECT count(*) FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_TABLE;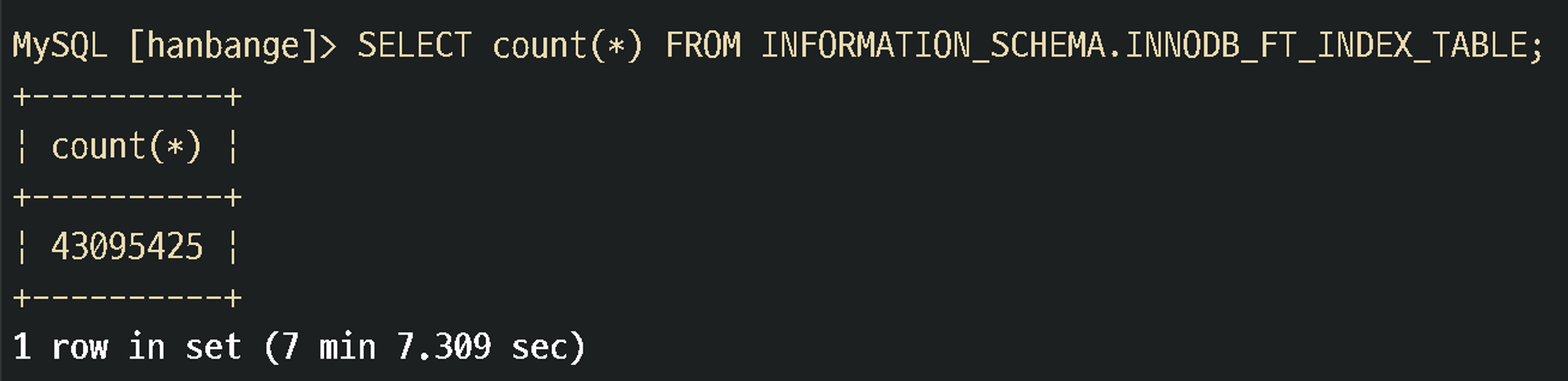
⇒ 사천 만개의 인덱스가 생성됨을 확인
쿼리문
사용자가 원하는 키워드는 자신이 검색한 키워드들의 조합으로 이루어진 결과이다. 따라서 그러한 결과를 만들어주기 위해 사용자가 검색한 키워드가 필수로 포함되도록 + 키워드 를 사용한다.
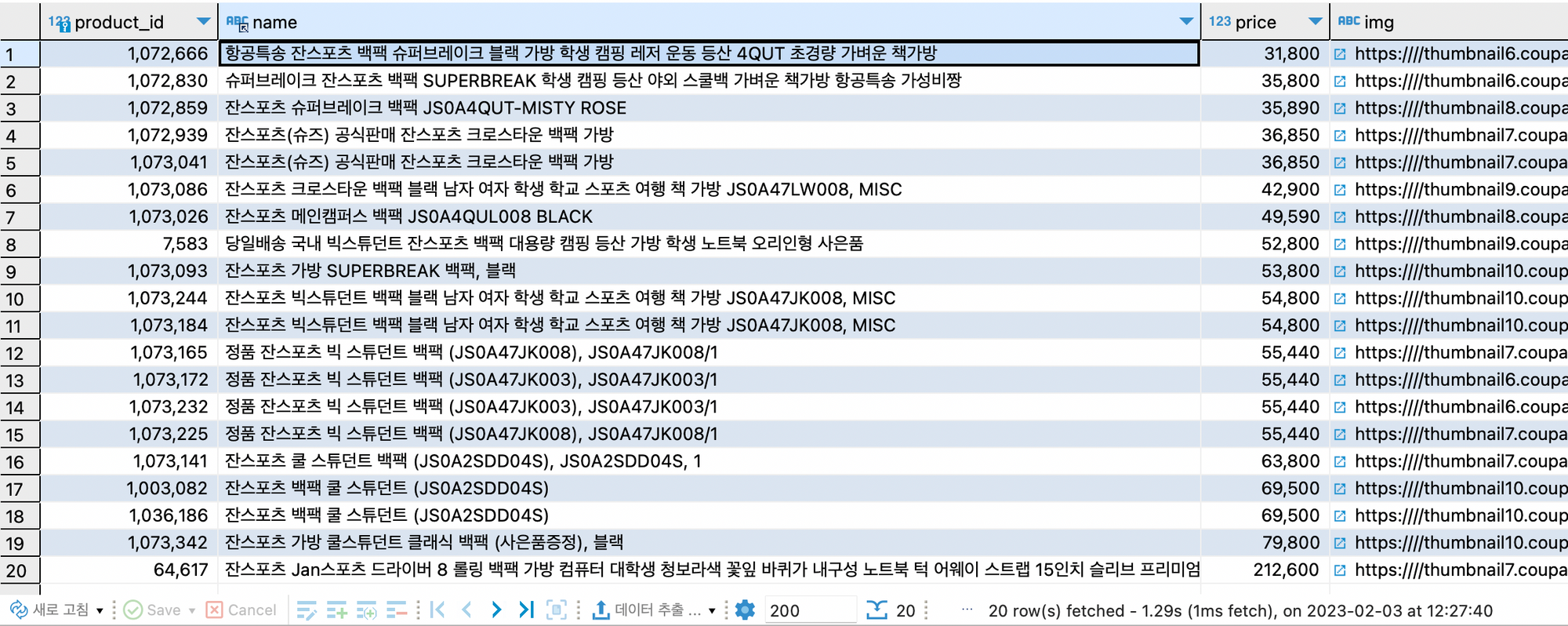
select product_id, name, price, img from product_ngram where match(name) AGAINST('+잔스포츠 +백팩' IN BOOLEAN MODE) ORDER by price limit 20;full-text 적용 코드
// full-text index 를 적용한
@Query(value =
"SELECT * FROM product_ngram WHERE MATCH(name) AGAINST(:keyword IN BOOLEAN MODE)", nativeQuery = true)
Slice<Product> searchFullTextIndex(@Param(value = "keyword") String keyword, Pageable pageable);- 실행계획

검색 키워드 : 잔스포츠 백팩
| 횟수 | 시간 |
|---|---|
| 1 | 1.29s |
| 2 | 163 ms |
| 3 | 60 ms |
검색 키워드: 아디다스 헤어밴드
select product_id, name, price, img from product_ngram where match(name) AGAINST('+아디다스 +헤어밴드' IN BOOLEAN MODE) order by price limit 20;
| 횟수 | 시간 |
|---|---|
| 1 | 124 ms |
| 2 | 182 ms |
| 3 | 121 ms |
검색 키워드: 다이어리 스티커
select product_id, name, price, img from product_ngram where match(name) AGAINST('+다이어리 +스티커' IN BOOLEAN MODE) order by price limit 20;
| 횟수 | 시간 |
|---|---|
| 1 | 10.160s |
| 2 | 7.695s |
| 3 | 1.787s |
| 4 | 1.251s |
| 5 | 1.172s |
검색 정확도 측면
한글자 포함 검색
검색 키워드: 비타민 A
select product_id, name, price, img from product_ngram where match(name) AGAINST('+비타민 +A' IN BOOLEAN MODE) order by price limit 21;
검색 시, 띄어쓰기로 분리된 단어 중 한 단어일 경우(현재 예시에선 ‘A’)를 포함할 경우 검색 결과는 없다.
그 이유는 n=2로 지정하여 한 글자인 경우의 검색을 하지 못하기 때문인데, 현재 검색 결과 조건이 +A라 검색 결과가 나오지 않는다.
- 검색 조건 변경
select product_id, name, price, img from product_ngram where match(name) AGAINST('+비타민 +A*' IN BOOLEAN MODE) order by price limit 21;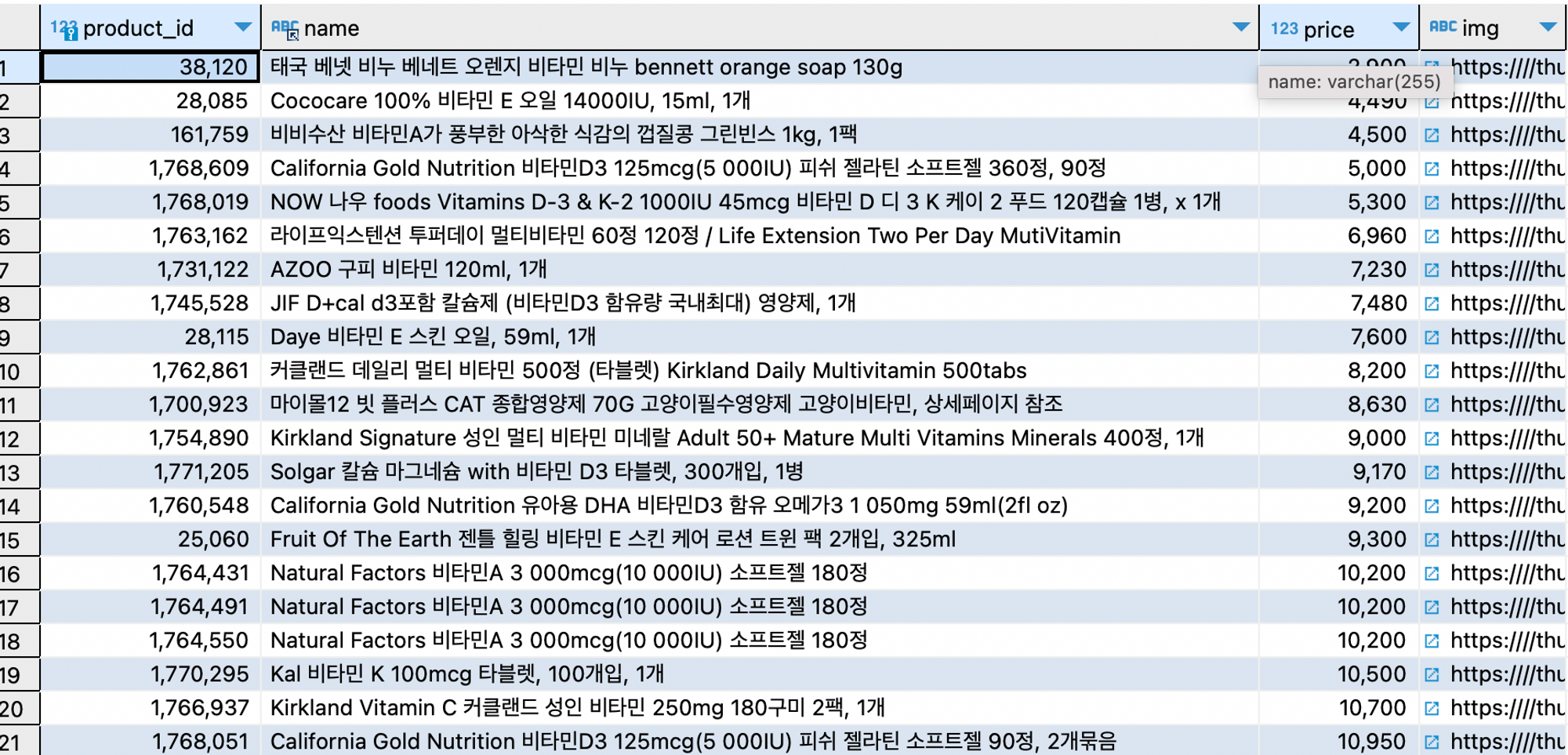
검색 조건을 달리하여 검색해보았다. 그러나 비타민이 포함된 단어들을 모두 결과로 조회하여 정확도가 떨어진다.
띄어쓰기에 따른 검색
검색 키워드: 미움받을 용기
select product_id, name, price, img from product_ngram where match(name) AGAINST('+미움받을 +용기' IN BOOLEAN MODE) order by price limit 21;
검색 키워드: 미움받을용기 → 검색 결과 x
select product_id, name, price, img from product_ngram where match(name) AGAINST('+미움받을용기' IN BOOLEAN MODE) order by price limit 21;대체적으로 검색 속도가 빨라졌으나, ‘다이어리 스티커’에서 볼 수 있듯이 단어별로 엄청난 속도차이가 있다. 또한 형태소 분석의 한계가 있다.
참고
MySQL :: InnoDB 전문 검색 : N-gram Parser
MySQL 5.6 한글메뉴얼
[Mysql] 게시판 검색 FULLTEXT with N-GRAM 전문 검색 최적화 (#스터디)
MySQL 5.6 한글메뉴얼
