텍스트 타입
텍스트 타입은 일반적으로 문장을 저장하는 매핑 타입으로 사용한다.
일반적으로 문장이나 여러 단어가 나열된 문자열을 텍스트 타입으로 지정한다.
텍스트 타입으로 지정된 문자열은 분석기에 의해 토큰으로 분리된다.
이렇게 분리한 토큰들은 인덱싱된다. 이를 역인덱싱이라고 한다.
DSL 쿼리를 이용해 다음과 같이 검색을 할 수 있다.
GET text_index/_search
{
"query": {
"match": {
"contents": "day"
}
}
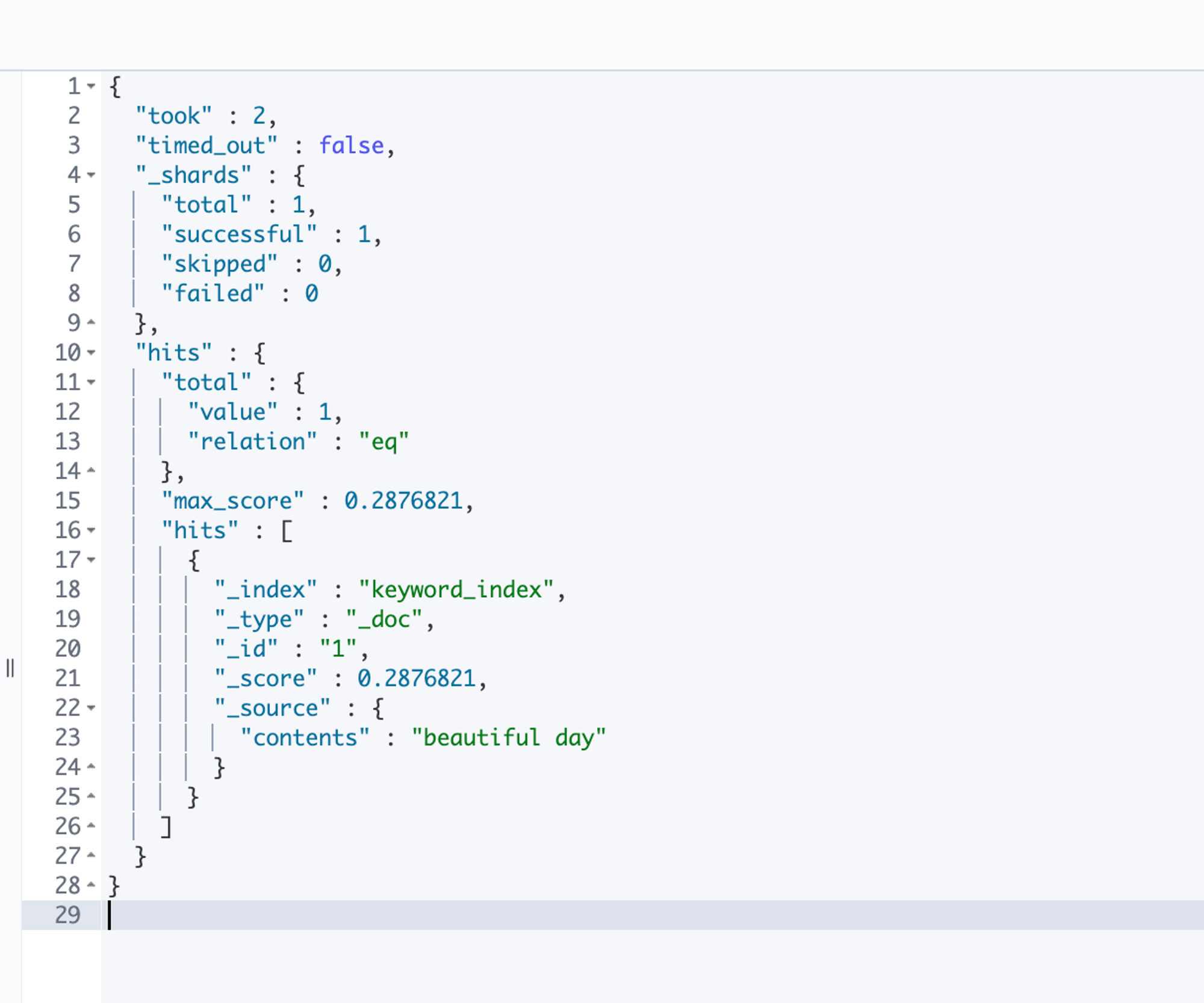
}1번 도큐먼트의 contents 필드에 [beautiful, day]라는 2개의 용어가 저장되어있어서 검색이 된다.
키워드 타입
키워드 타입은 카테고리나 사람 이름, 브랜드 등 규칙성이 있거나 유의미한 값들의 집합, 즉 범주형 데이터에 주로 사용된다.
키워드 타입은 문자열 전체가 하나의 용어로 인덱싱된다.
키워드 타입으로 매핑된 데이터는 부분 일치 검색은 어렵지만 대신 완전 일치 검색을 위해 사용할 수 있다.
- 집계나 정렬에 사용할 수 있다.
- 성별이나 상태를 난타내는 필드에 사용할 수 있다.
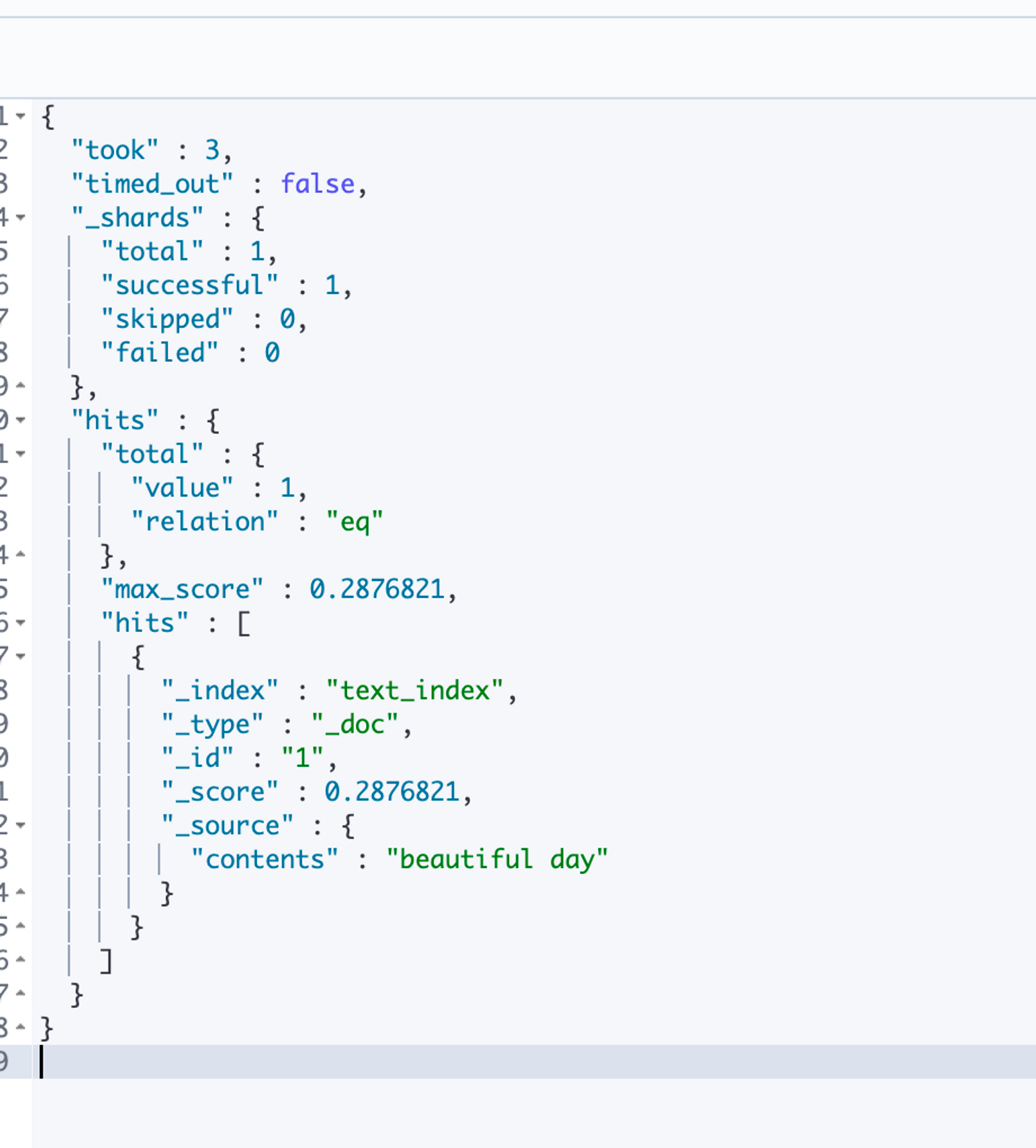
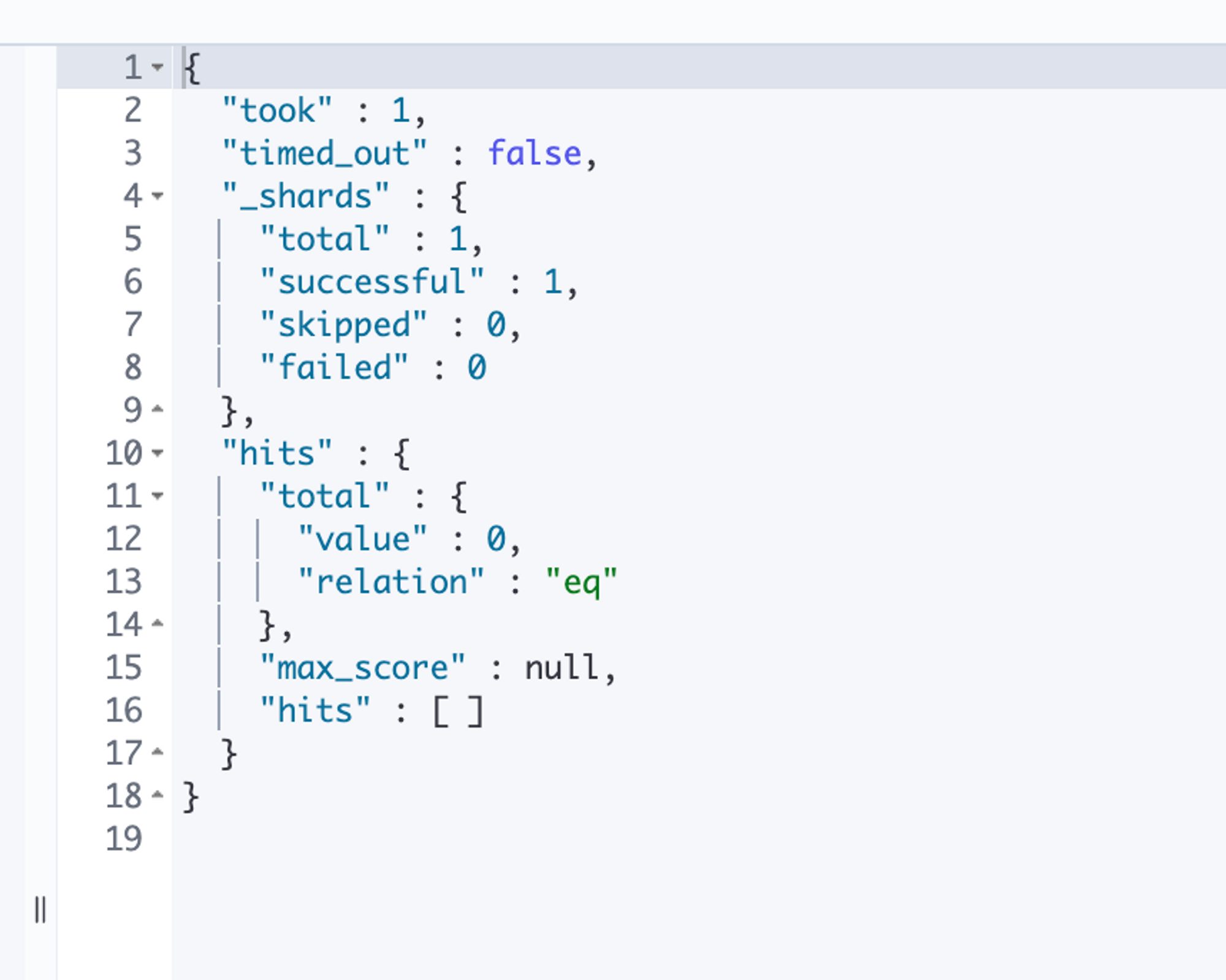
위와 같이 beautiful로만 검색하면 결과가 나오지 않는다.
GET keyword_index/_search
{
"query": {
"match": {
"contents": "beautiful"
}
}
}
beautiful day라고 검색해야 도큐먼트를 찾는다.
GET keyword_index/_search
{
"query": {
"match": {
"contents": "beautiful day"
}
}
}