1강 : [Recap] Numpy & Pandas (1) - Numpy tutorial
Numpy
dtype
np.array의 dtype은 반드시 하나로 통일됨.
v = np.array([1, 2, 4.3, 5])
이 경우 dtype은 float으로 통일됨.
v1 = np.array([1, 2, 3, "hi"])
이 경우 str로 통일
v2 = np.array([1.2, 2.3, "3.5"])
이 경우도 str로 통일
통일하는 이유는, array 대상으로 연산 및 함수를 쉽게 적용하기 위함임
shape
1차원 배열같은 경우 (행, 열)로 리턴하는게 아닌, 단순히 원소의 개수를 리턴함.
만약 (행, 열)로 리턴하려면 2차원 배열처럼 선언하면됨.
np.array([ [1,2,3] ])
indexing
- 다차원 배열에서 특정 좌표를 한 번에 인덱싱 가능함.
sample = [[1,2,3], [4,5,6], [7,8,9]]
sample[0,0] -> 1
만약 3차원이라면 sample[0, 2, 1] 이런 식으로.
- 부분 행렬도 꺼낼 수 있음.
sample[ 0:2, 1:3 ]
-> array([[2,3], [5,6]])
sample[ : , 2]
-> array([3, 6, 9])
만약 이걸 2차원 배열 형태로 꺼내고 싶다면
sample[ : , 2:3]
이러면 3행 1열의 2차원 배열을 리턴함
arange
- array를 대상으로 사칙연산을 하면 모든 원소에 대해 그 연산을 적용함.
array of range
np.arange(1, 10, 2)
-> array([1, 3, 5, 7, 9])
np.arange(1, 10, 2) ** 2
-> array([1, 9, 25, 49, 81], dtype=int32)
reshape
- 행렬의 모양을 바꿔줌
v = np.arange(12)
v1 = v.reshape(2, 6)
-> array([[0,1,2,3,4,5],
[6,7,8,9,10,11]])
열 방향으로 채우고싶다면
v1 = v.reshape(2, 6, order="F")
-> array([[0, 2, 4, 6, 8, 10],
[ 1, 3, 5, 7, 9, 11]])
order는 C(행, default) 또는 F
크기가 너무 커서 4행 몇열로 reshape하고 싶을 때 열의 값이 몇이 되는지 계산이 어렵다면 그냥 reshape(2, -1)
이렇게 써주면 열의 값은 알아서 계산해줌.
- 응용
만약 연속적인 값의 다차원 행렬을 만들고 싶다면? (method-chaining)
v1 = np.arange(12).reshape(2, 6)
-> array([[0, 1, 2, 3, 4, 5],
[6, 7, 8, 9, 10, 11]])
np의 사칙연산 메소드
np.max(v)
np.min(v)
np.mean(v)
np.std(v)
- axis를 설정해서 행 마다, 또는 열 마다의 특정 값을 꺼낼 수도 있음. array 형으로 결과를 리턴해줌
v = array([[1, 2],
[3, 4]])
np.max(v)
-> 4
np.max(v, axis=0)
-> array([3, 4])
np.max(v, axis=1)
-> array([2, 4])
axis가 0이면 열 방향, 1이면 행 방향(행 마다의 최대값)
행렬 간의 사칙연산
같은 위치의 원소끼리 연산하는 걸 element-wise calculation 라고 함
v1 = array([[1, 2],
[3, 4]])
np.add(v1, v1)
-> array([[2, 4],
[6, 8]])
np.subtract(v1, v1)
-> 빼기
np.multiply(v1, v1)
-> element-wise multiply
array([[1, 4],
[9, 16]])
np.dot(v1, v1)
-> 행렬곱 (dot-product, 점곱)
@ 주의 : 내적은 결과가 스칼라로 나오는 행렬곱임. 1x3 행렬 내적 3x1 행렬 등. 헷갈리지 말자
2강 : [Recap] Numpy & Pandas (2) - Pandas Recap
Pandas
Series
key 값이 있는 리스트라고 이해하면 편함.
1차원 데이터임.
a = pd.Series([1, 3, 5, 7])
a.values
a.index
-> 프로퍼티명이 index지만, 인덱스 번호라고 생각하지 말고 key라고 생각하면 된다.
a2 = pd.Series([1, 3, 5, 7], index=['a', 'b', 'c', 'd'])
-> 인덱스 값 지정 가능 (인덱스 열이 아님. 키 값일 뿐 Series는 1차원!)
열 인덱싱
df['amount']
df.amount
둘 다 열 Series 리턴
다만 띄어쓰기같은게 포함되어 있으면 위의 방법으로 인덱싱하자.
DF에서 하나의 Cell 값을 얻는 5가지 방법
1) df['amount'][0]
-> 열 먼저 접근 후 키 값(index) 조회
2) df.loc[0]['amount']
-> 행 먼저 접근 후 열 접근
3) df.loc[0, 'amount']
-> 행 먼저 접근 후 열 접근
4) df.at[0, 'amount']
-> 값을 재할당할 때 용이함. loc같은 경우는 값 재할당이 잘 안되는 경우가 있음. loc보다는 at을 적극 활용하자.
5) df.iloc[0, 7]
-> 찐 인덱스 번호 기반 접근
Series 사이의 연산
df['total_payment'] = df['amount'] * df['count']
여기서 새로 생성되는 Series의 위치를 지정하고싶다면
df.insert(8, 열 이름, 리스트(Series))
필터링
df_gender = df[ df['gender'] == 1 ]
df_reacount = df[ (df['count'] < 10) & (df['count'] >= 1) ]
각 조건은 반드시 괄호로 묶어줘야하고, and를 사용하지말고 &를 사용해야함. 마찬가지로 or 대신 |
- df['edu'].value_counts(sort=False)
collections의 Counter 클래스와 유사함.
참고로 Counter로 구한 dict로 Series로 변환가능함.
Series에서 특정 값들이 몇 개씩 들어있는지 구해서 Series로 리턴함. 리턴 Series의 키 값은 value, cell 값은 갯수임
sort 파라미터의 default 값은 True임.(내림차순)
정렬 안하고싶으면 False로 넘겨주자
apply (열 Series에 함수 적용해서 새로운 열 Series 만들기)
def num_to_character(data):
if data == 1:
return 'male'
else:
return 'female'
df['gender_2'] = df['gender'].apply(num_to_character)람다 함수를 활용해도 됨.
df['gender_2'] = df['gender'].apply(lambda x: 'male' if x == 1 else 'female')또는 replace 함수를 활용해도 됨.
df['gender'] = df['gender'].replace([1, 2], ['male', 'female'])이 코드에선 2를 'male'로 replace하도록 작성했는데, 만약 gender 열에 2가 없더라도 에러가 터지지는 않는다.
3강 : 빈도 분석 & 기술 통계량 분석 (1) - 데이터 탐색과 기술 통계 분석
EDA
Exploratory Data Analysis (탐색적 데이터 분석)
데이터를 탐색하면서 결측치 보정, 빈도 분석, 기술 통계량 분석 등등을 하는 것
그 과정에서 시각화를 위해 Pandas, matplotlib , 그 외의 LUX, Bamboolib, PandasGUI 등등의 다양한 라이브러리 활용 가능
plot
Series의 메소드임
df['열이름'].value_counts().plot(kind='그래프종류')
Series에 대한 사칙연산
Series에 바로 사칙연산을 때릴 수 있다.
df['열이름'] * 100
DF의 기술통계량 함수
df.min()
df.max()
df.mean()
df.std()
df.var()
df.quantile()
df.median()
등등 사용가능함.
물론 Series에 대해서도 가능함.
df['열이름'].max() 등등
- df['열이름'].hist() : 빈도 기반 히스토그램 그려줌. Series의 메소드
df에도 hist 메소드가 있음. 모든 열에 대한 히스토그램을 각각 다 그려줌
hist에는 여러 매개변수가 있다. bins의 경우 막대의 폭을 결정하며 값이 작을수록 폭이 커진다.
figsize로 그래프 전체 크기를 결정할수도 있다.
분포의 왜도와 첨도
왜도(Skewness) : 분포가 좌우로 치우쳐진 정도
0에 가까울수록 정규분포라고 가정할 수 있음 (절대값 기준 3 미초과할 때)
분포에서 긴 꼬리(치우쳐진쪽이 몸통, 그 반대의 빈약한 쪽이 꼬리)가 왼쪽에 있으면 음의 왜도
분포에서 긴 꼬리가 오른쪽에 있으면(분포가 왼쪽으로 치우친 경우) 양의 왜도
꼬리의 방향이 부호 결정!
df['열이름'].skew()
첨도(Kurtosis) : 분포가 뾰족한 정도
1에 가까울수록 정규분포라고 가정할 수 있음 (절대값 기준 8 또는 10을 미초과할 때)
왜도가 0이고 첨도가 1일 때 완전한 정규분포로 가정할 수 있다.
머신러닝에서는 그렇게 막 엄밀하게 정규성을 따질 필요는 없다. 통계학적 배경지식을 익힌다는 느낌으로 이 내용은 가볍게 익혀놓자.
df['열이름'].kurtosis()
distplot
sns.distplot(Series, rug=True)
히스토그램에 더해 분포 예측 곡선?같은 것을 추가로 그려줌
rug: 실제 데이터를 x축에 짜잘하게 다 표현해줄 것인지 여부
jointplot
sns.jointplot(x="amount", y="count", data=df, kind="그래프종류")
-> 두 Series에 대해 그래프를 그려줌
4강 : 빈도 분석 & 기술 통계량 분석 (2) - Outlier의 탐지 및 제거
Outlier (IQR Score 활용)
Outlier를 항상 지워버리는게 능사는 아니다.
예를 들어 백화점에서 구매 횟수가 압도적으로 많거나 구매 금액이 압도적으로 많은 Outlier가 있다면 이 분들은 따로 분류해내어 사업적으로 도움이 되는 분석을 할 수도 있기 때문이다.
어떤 데이터의 Outlier를 탐지하고 이를 제거할지 따로 분류해서 데이터로 활용할 것인지를 깊게 생각해보고 실행하자.
boxplot (수염상자그림)
df.boxplot(column='amount')
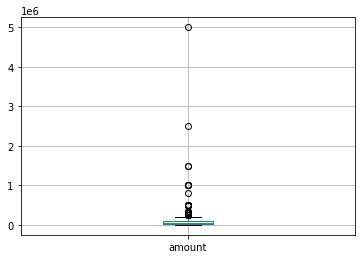
outlier를 확인할 수 있는 메소드이다.
quantile을 기준으로 지정하는 듯 하다.
그림의 검은색 작은 가로 선이 상/하한선이다. 이를 넘어가는 데이터를 outlier로 간주하고 동그라미로 표시해준다.
만약 lower whisker 밑에 outlier로 표시된 동그라미가 없다면, 데이터의 최소값이 곧 lower whisker가 되고, 마찬가지로 상한선 위에 데이터가 없다면 데이터의 최대값이 곧 상한선이 된다.
median
데이터가 짝수개일 때는 가운데 두 데이터의 평균을 중위값으로 삼음.
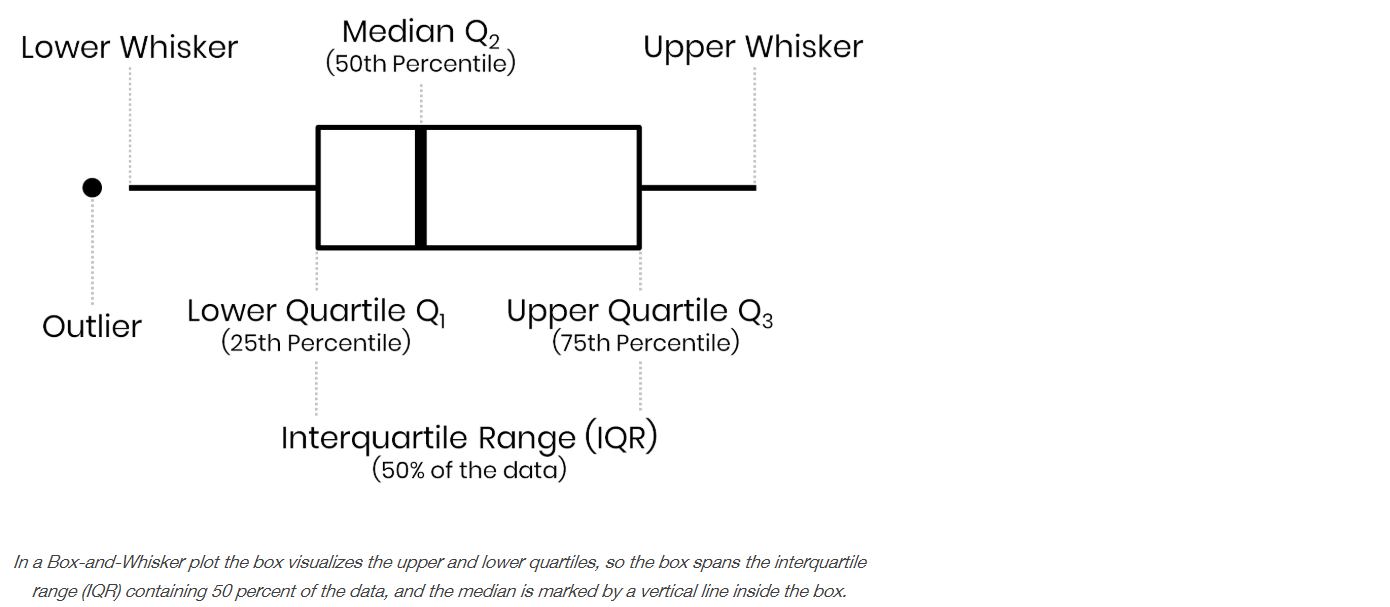
IQR Score
그렇다면 box-and-whisker plot에서 lower whisker와 upper whisker는 어떻게 결정할까?
바로 여기에 IQR Score 기법이 적용된다.
풀 네임은 InterQuartile Range Score 이다.
위 그림에서 25퍼 지점(박스의 밑면)과 75퍼 지점 사이(박스의 윗면)의 범위를 IQR(InterQuartile Range)라고 하는데, 이것의 1.5배를 25퍼 값 에 빼주면 그게 lower whisker가 되고,
IQR의 1.5배를 75퍼 값 에 더해주면 그게 upper whisker가 된다.
lower whisker 밑에 있는 값과 upper whisker 위에 있는 값은 outlier로 간주한다.
IQR 기법이 간단하고 명료한 방법이긴 하지만 때로는 데이터를 꽤나 많이 날려버릴 수도 있어서 그대로 적용하기보단 참고해서 본인이 잘 판단해서 정제하자.
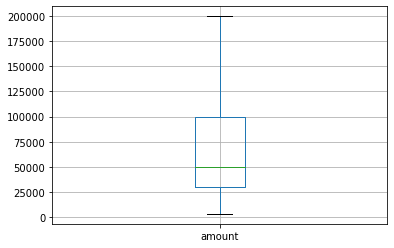
Q1 = df['amount'].quantile(0.25)
Q3 = df['amount'].quantile(0.75)
IQR = Q3 - Q1
lower_whisker = Q1 - IQR * 1.5
upper_whisker = Q3 + IQR * 1.5
df_IQR = df[ (df['amount'] < upper_whisker) & (df['amount'] > lower_whisker) ] log 함수를 활용한 Data(Feature) Scaling
특정 데이터의 scale이 너무 넓은 경우, 왜도와 첨도가 지나치게 클 수도 있다.
데이터에 log를 씌워 scale을 줄여주면, 왜도/첨도를 낮추는 전처리를 해줌으로써 데이터(열)의 정규성을 높이고, 각종 분석에서 보다 나은(정확한) 값을 얻을 수 있다.
processed_df['logamount'] = np.log(processed_df['amount']) 적용 전
- sns.jointplot(x="amount", y="count", data=processed_df, kind="kde")

processed_df['logamount'] = np.log(processed_df['amount']) 적용 후
- sns.jointplot(x="logamount", y="count", data=processed_df, kind="kde")
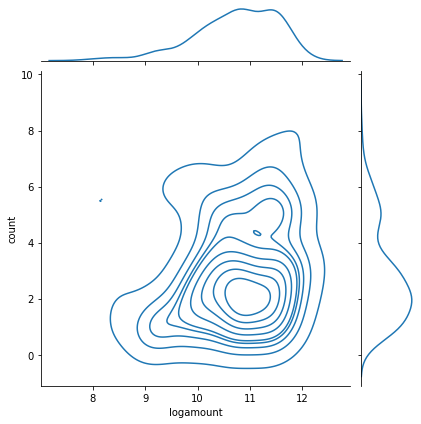
5강 : 파이썬을 활용한 통계 검정 (1) - 교차 검정
교차분석
범주형 열 : 셀의 값이 수치가 아닌 범주의 의미를 갖는 값일 때
ex) 1(남성), 2(여성)처럼, 2는 1의 2배 처럼 연산을 하는게아니라 그 숫자 너머에 어떤 특정 의미가 있는 값 (Numerical이 아닌 Categorical)
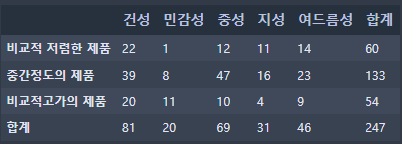
pd.crosstab(범주형 열1, 범주형 열2, margins=True)
범주형 열 두 개의 각 pair의 카운팅을 표로 나타내어주는 메소드이다.(margins는 ALL 추가 여부)
예를 들어 skin이 2이고 propensity가 3인 행의 개수를 구하는데 , 이런 카운팅 값들을 모든 pair에 대해 cross table로 구해준다.
normalize=True를 넣어주면 값의 정규화를 해준다.
margins=True를 했을 때 뜨는 ALL행 ALL열의 값으로 모든 셀을 나눠준다.
그런데 표와 같이 민감성 피부인 고객들이 실제로 고가의 제품을 선호하는게 맞는지, 중성 피부의 고객들이 실제로 중간 가격의 제품을 선호하는게 맞을까? 랜덤한 데이터에 대한 통계이므로 우연히 저런 결과가 나온게 아닐까? 하는 의문이 들 수 있다.
이럴 때 통계학적 의미가 있는지를 검정을 통해 판단해볼 수 있다.
귀무가설(=영가설=None Hypothesis) : 피부 타입에 따라 구매 성향에 차이가 없다. (두 인자 사이의 관계가 없다. 독립적이다.)
대립가설 : 피부 타입에 따라 구매 성향에 차이가 있다. (보통 검증하고자하는 목표. 두 인자 사이의 관계가 있다. 의존적인 관계가 있다. 서로 영향을 준다.)
이 두 가설을 자동으로 세워놓고 검정을 실행함.
Chi-square 검정 (카이제곱검정)
: 두 범주형 변수 사이의 관계가 있는지 없는지를 결정 (독립성 검정)
stats.chisquare(df['범주형열1'], df['범주형열2'])
리턴 값 : Power_divergenceResult(statistic=291.8166666666667, pvalue=0.023890557260065975)
보통은 p-value가 0.05 이하이면 대립가설을 지지함 (유의미한 관계가 있을 것이라는 가설을 지지)
다만 이렇게 단순하게만 해석하면 부족하다.
p-value의 의미를 좀 더 깊이 알아보자.
p-value
p-value : 귀무가설이 참이라는 전제 하에, "관찰이 완료된 값(위의 표)" 또는 그보다 더 극단적인 값(극단적으로 대립가설에 가까운 값)이 샘플 데이터(표본)을 통해 나타날 조건부 확률
즉, 귀무가설이 참이라는 전제 하에 crosstab과 같은 값이 나올 확률값이다.
보통 0.05(5%)를 기준으로 잡고 이보다 낮으면 귀무가설이 참이라고 가정할 때 결과값이 나올 확률이 매우 낮다고 판단하여 귀무가설을 기각하고, 0.05보다 높으면 귀무가설을 기각하지않는다.
다만 유의할 점은, p-value가 0.05보다 낮아서 귀무가설을 기각했다고해서 대립가설이 옳다라는 것을 뜻하는 것은 절대 아니다.
예를 들어 p-value가 0.03이라면 귀무가설을 기각하기는 하겠지만, 적은 확률이라도 어쨌든 3퍼의 확률로 귀무가설이 맞을 수도 있는거니까, 대립가설이 확실히 옳다고 말할 수는 없는 거임.
p-value의 기준 값은 변경할 수도 있다. 귀무가설이 참인데도 불구하고 이를 기각하는 것이 위험하거나 큰 비용이 발생하는 경우, 예를 들어 백신의 경우 효과의 여부를 좀 더 엄밀하게 따지고 싶다면, p-value를 좀 낮춰서, 예를 들어 p-value 기준을 0.01로 잡고 귀무가설이 참이라고 가정할 때 실험 결과값들이 나올 확률이 1퍼센트도 안되는 현저히 낮은 확률이어야만 귀무가설을 기각하고 백신에 효과가 있을 것이라는 대립가설을 지지한다.
참고로, p-value가 기준보다 높게 나와서 귀무가설을 기각하고 대립가설을 지지하게 되었더라도, 실제로 데이터의 크기 변화 자체가 미미하다면 관계를 구하는 것 자체가 실용적인 의미를 갖지 못할 수도 있다.
예를 들어 쇼핑몰에서 구매 버튼의 디자인을 변경하여 구매 수가 n만큼 증가되었고, 이를 통계 검정 후 귀무가설을 기각하고 대립가설을 지지하게 되었다고치자.
근데 이 n 자체가 되게 미미하다면, 설령 디자인 변경이 구매 수 증가에 기여를 한다고쳐도 너무 적게 기여를 하는 것이라서 상업적으로 별 의미가 없는 경우도 있을 수 있다는 것이다.
df.plot.bar(stacked=True)
df.plot(kind='bar', stacked=True)
둘 다 결과가 같음
6강 : 파이썬을 활용한 통계 검정 (2) - 평균 차이 검정 & 상관관계 분석
독립표본 t-test 분석 : 표본이 독립적임. ex) A반의 영어 성적과 B반의 영어 성적의 평균 차이를 검정
대응표본 t-test 분석 : 표본이 동일함. ex) A반의 중간고사 영어 성적과 기말고사 영어 성적 평균 사이의 차이 검정
독립표본
: 두 집단 간의 평균 차이를 검정
stats.ttest_ind(arg1, arg2)
arg : Series(비교하고자 하는 변수 열) 또는 값들만 모아놓은 values
리턴 값 : statistic과 p-value
만약 p-value가 기준보다 높다면 귀무가설을 그대로 갖고, 두 집단 간의 평균값 사이에 유의미한 차이는 없을 확률이 높다고 해석하면 된다. 즉 두 집단의 데이터 값들의 평균이 각각의 데이터 값들 사이의 관계에 어떠한 영향도 주지않을 확률이 높다고 해석하면 된다.
df.boxplot(column = '열1', by='열2')
열1을 열2 값 기준으로 행을 나눠서 수염상자그림을 그리는 메소드
대응표본
stats.ttest_rel(열1, 열2)
동일한 집단의 두 변수를 넣어줌.
이를 시각화하고 싶다면 sns.distplot을 사용해보자.
sns.distplot(df["satisf_b"], kde=False, fit=stats.norm, hist_kws={'color': 'r', 'alpha': 0.2}, fit_kws={'color': 'r'})
kde : 빈도 수에 따른 밀도 함수 그래프 그리는지 유무
fit : 분포에 대한 그래프 선 (fitting line) 그리는지 유무
hist_kws : hist의 keyword arguments. 여러 가지 서식 지정 가능
fit_kws : fitting line의 서식 지정 가능
분산분석 (ANOVA F-test)
ANalysis Of VAriance : 줄여서 ANOVA 라고 많이 부름
stats.f_oneway(anova1, anova2, anova3)
arg : Series or Series의 values
상관관계분석
범주형 변수보단 Numerical 변수들 대상으로 쓰기 좋음
df.corr()
: df의 열의 가능한 모든 pair에 대해 피어슨 상관계수를 구해줌
-1에 가까울수록 음의 상관관계(반비례)
0에 가까울수록 상관관계가 적음(독립)
1에 가까울수록 양의 상관관계(비례)
sns.pairplot(df_corr)
: df의 모든 열의 pair에 대해 선점도 그래프를 그려줌. 보통 Numerical 변수들에 대해서 그려야 좀 추세가 잘 보임. 범주형 열을 대상으로 그리면 추세 파악이 좀 힘듦
중요한 점은, 이 상관관계분석으로 나오는 결과를 바로 적용하면 안된다.
예를 들어서 음의 상관계수가 나왔다고 해서 이 두 변수 사이에 음의 상관관계가 있구나라고 바로 확정지으면 안된다.
그 전에 고려해야할 부분이 하나 더 있다.
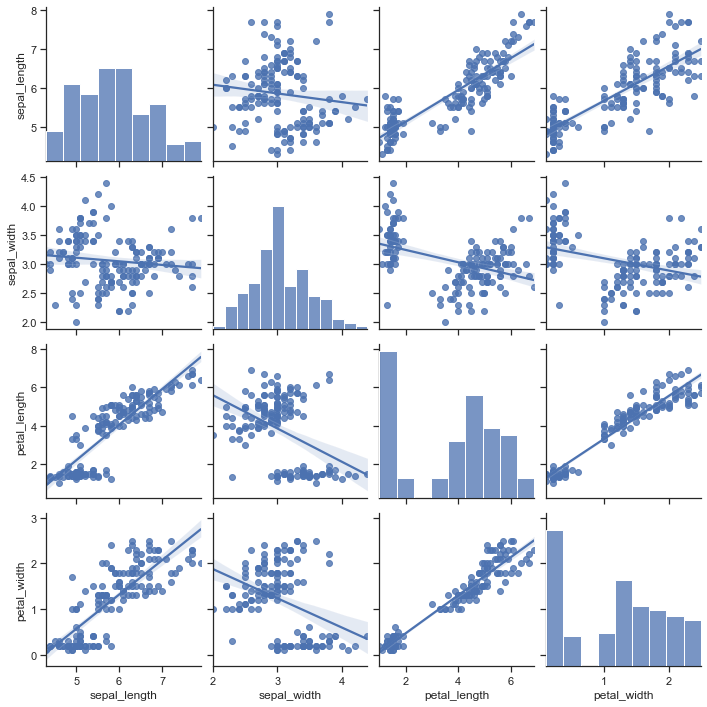
여기서 sepal_width와 petal_length의 pair 그래프를 보면 음의 상관관계로 추세를 보여주는데, 물론 전체로 놓고 보면 음의 상관관계가 맞지만, 이런 형태의 그래프인 경우 위쪽 뭉탱이와 아래쪽 뭉탱이를 그룹지어 나누어서 생각할 수도 있다.
위쪽 뭉탱이는 양의 상관관계를 띠고있고, 아래쪽 뭉탱이는 독립 양상을 띠고있다.
즉 실제로 데이터를 시각화해보고 이런 경우의 pair는 그룹으로 나누어 따로 상관관계를 생각할 수도 있어야한다.
이걸 심슨의 역설이라고 한다.
암튼 이런 식으로 상관계수의 신빙성을 체크해보는게 필요하다.
또한 p-value를 구해서 신빙성을 체크해볼 수도 있다.
7강 : 그로스 해킹을 위한 파이썬 통계 분석
stats.pearsonr(ad_df['Marketing_Costs'], ad_df['User_Acquired'])
피어슨 상관계수와 그 값에 대한 p-value를 구해주는 메소드이다.
상관계수에 따라 약한 상관관계인지 강한 상관관계인지 그 정도를 판단하는 기준은 심리학, 정치 등 분야 별로 조금씩 다르다. 보통은 심리학 기준으로 많이 하는데, 자세한 내용은 검색해보자.
A/B Test
마케팅 전략으로 주로 사용되는 기법이다.
예를 들어 사용자가 웹 사이트에 들어오면 랜덤하게 웹 사이트 시안 A와 B 중 하나로 접속되게하고, 해당 사용자의 체류 시간을 측정한다. 쌓인 데이터를 가지고 독립표본 t-test를 실행하여 A와 B의 평균 체류시간 차이를 확인하고, 그 대소 관계가 통계학적으로 유효한지를 검사한다.
이 일련의 과정을 A/B Test라고한다.
참고 : df['열이름'].dropna() -> 결측치가 포함된 행을 통째로 날려버림
stats.ttest_ind(열1, 열2, equal_var=True or False)
equal_var : 두 집단의 분산이 같은지 여부 (보통 같은 경우 잘 없으므로 False로 써서 쓰자. default 값이 True임), 두 집단의 샘플 데이터 수가 같지 않을 때도 False로 하면 됨.
마케팅에서의 전환율(Conversion rate)과 클릭율(Click-Through Rate)를 검정해보자.
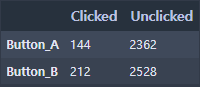
위와 같이 웹 사이트를 방문한 유저들의 구매 확정 버튼 클릭수와 미클릭수를 카운팅해서 행은 버튼 종류, 열은 클릭 여부인 Contingency table로 데이터가 주어졌다고 하자.
이러한 분할표(Contingency table)를 대상으로도 카이제곱 검정을 할 수 있는 메소드가 있다.
stats.chi2_contingency([열1, 열2])
리턴 값이 여러개 나오는데, 두 번째가 p-value임.
이 때 데이터에 대한 해석은, 버튼 A/B(범주형 변수 1)에 대한 클릭 여부(범주형 변주 2) 사이에는 통계적으로 유의미한 차이가 있을 확률이 높다. (B의 클릭율이 높다는 결과값을 믿을만 하다.)
