1. 데이터 설명
우선 PCA와 tsne에 관한 설명과 간단한 예시들은 구글에 검색하면 아주 좋은 자료들이 있기에 skip!
# load_Dataset(): return [Image_Path_List, Conversation_Data, Item_Meta_Data, FashionITEM_Meta_JSON, Evaluation_Data]
# 1. Image_Path_List(string_list): 이미지 path로 이루어진 list
# 2. Conversation_Data(DataFrame): 대화 data를 pandas.dataframe으로 재구성
# 3. Item_Meta_Data(DataFrame): 아이템 메타 data를 pandas.dataframe으로 재구성
# 4. FashionITEM_Meta_JSON(Dictionary): 각 이미지별, 일상성/성/장식 특징에 대한 4096차원의 3가지 벡터
# 5. Evaluation_Data(DataFrame): 평가 data를 pandas.dataframe으로 재구성
Image_Path_List, Conversation_Data, Item_Meta_Data, FashionITEM_Meta_JSON, Evaluation_Data = load_Dataset()대회에서 지급된 데이터들을 우리가 사용하기 편하게 하려고 여러 구조들을 통해서 묶어놓았다.
여기서 나는 4번의 FashionITEM_Meta_JSON(Dictionary) 데이터를 축소시켰다. 간단히 JSON파일이라고 하겠다.
JSON파일은 딕셔너리 형태로 되어있으며 아이템 이미지가 key, 벡터 값이 value로 되어있다. 간단히 설명하자면 코디 아이템에 블라우스,코트,신발,스커트 등등 13가지 종류가 있으며 각 종류가 여러개로 되어있다. 그리고 벡터 값은 이미지에 대해 학습을 통해 나온 토큰 값 정도로 생각하면 될 것 같다.
# 예시1) BL-001(블라우스 중 1번째 아이템)에 대한 일상성 벡터 예시
print(FashionITEM_Meta_JSON['BL-001.jpg'])
#결과 3*4096 vector
#[[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.8540367484092712, 1.0132994651794434, 0.575775146484375, 0.5846178531646729, 0.0, 0.04568198323249817, 0.00529518723487854, 0.027411475777626038, 0.14394733309745789, 0.5706108212471008, 0.0, 0.607929527759552, 0.0, 0.050044380128383636, 0.0, 0.05215628817677498, 0.3836817741394043, 0.4110223054885864, 0.0, 0.0, 0.06012576073408127, 0.088470958173275, 0.0, 0.22992366552352905, 0.0, 0.0, 0.0, 0.0, 0.16097980737686157, 1.32383394241333,.....여기서 3은 일상성/성/장식이다.
나는 차원 축소를 통하여 13가지 아이템이 잘 나누어 지도록 하는게 역할이었다. 그러면 일상성/성/장식은 굳이 나눌 필요가 없기 때문에 우선 일상성에 관한 값들만 이용했다.
2. Dataframe 구성
자 이제 우리에게 데이터가 제공되었다. 하지만 앞에서 말했듯이 data가 딕셔너리 형태로 저장이 되어 있다. 우리가 모델에 데이터를 편하게 쓰기 위해 dataframe를 이용하기 때문에 딕셔너리 형태의 데이터를 pandas를 통해 dataframe으로 만들어 준다.
import pandas as pd
#전체 아이템에 대한 메타 데이터를 행렬화한 dataframe
#한개의 아이템당 3x4096으로 mapping(성,일상,패션) 되어 있는데 여기서 한개만 가지고 우선 분석
#한개 아이템--->1x4096 전체 아이템 개수가 2602개 이므로 총 2602*4096 완성
ITEM_Kind=['BL','CD', 'CT', 'JK', 'JP', 'KN', 'OP', 'PT', 'SE', 'SH', 'SK', 'SW', 'VT']
# BL = [items for items in FashionITEM_Meta_JSON if "BL" in items] --> 아이템 한개만 뽑고 싶을 때
total_kind=[] #matadata 저장
for kind in ITEM_Kind:
kind_1 = [items for items in FashionITEM_Meta_JSON if kind in items]
for i in range(len(kind_1)):
kind_1[i] = kind
total_kind.extend(kind_1)
LIST_INDEX = [] #label 저장
for item in FashionITEM_Meta_JSON:
LIST_item = FashionITEM_Meta_JSON[item][0]
LIST_INDEX.append(LIST_item)
df = pd.DataFrame(LIST_INDEX)
df['label']=total_kind
#겉옷 O (자켓JK, 점퍼JP, 코트CT, 가디건CD, 조끼VT): 310+280+310+150+111 = 1161
#웃옷 T (니트KN, 스웨터SW, 셔츠SH, 블라우스BL): 235+160+129+148 = 672
#아래옷 B (치마SK, 바지PT, 원피스OP): 230+234+176 = 640
#신발 S (신발SE): 130
item_O = []
for item in FashionITEM_Meta_JSON:
if 'JK' in item or 'JP' in item or 'CT' in item or 'CD' in item or 'VT' in item:
item_O.append(FashionITEM_Meta_JSON[item][0])
item_T = []
for item in FashionITEM_Meta_JSON:
if 'KN' in item or 'SW' in item or 'SH' in item or 'BL' in item:
item_T.append(FashionITEM_Meta_JSON[item][0])
item_B = []
for item in FashionITEM_Meta_JSON:
if 'SK' in item or 'PT' in item or 'OP' in item:
item_B.append(FashionITEM_Meta_JSON[item][0])
item_S = []
for item in FashionITEM_Meta_JSON:
if 'SE' in item:
item_S.append(FashionITEM_Meta_JSON[item][0])
나는 우선 리스트를 만들어 모든 아이템의 벡터를 집어 넣었고 Dataframe으로 만들었다. 그리고 나중에 시각화를 위해 label을 추가하여 어떤 아이템 종류인지 추가했다.
여기서 문제가 생겼는데 앞에서 말했듯이 key값에는 몇 번째 item인지 숫자가 써져있기 때문에 이 숫자를 없애야 하는 작업이 필요했다.
#ITEM 종류: BL,CD, CT, JK, JP, KN, OP, PT, SE, SH, SK, SW, VT
# 총 13가지 옷 종류
#겉옷 O (자켓JK, 점퍼JP, 코트CT, 가디건CD, 조끼VT): 310+280+310+150+111 = 1161
#웃옷 T (니트KN, 스웨터SW, 셔츠SH, 블라우스BL): 235+160+129+148 = 672
#아래옷 B (치마SK, 바지PT, 원피스OP): 230+234+176 = 640
#신발 S (신발SE): 130
#total: 2603
ITEM_Kind=['BL','CD', 'CT', 'JK', 'JP', 'KN', 'OP', 'PT', 'SE', 'SH', 'SK', 'SW', 'VT']
VT = [items for items in FashionITEM_Meta_JSON if "VT" in items] # 한 가지 아이템에 대한 정보만 보고싶을 때
total_kind=[]
for kind in ITEM_Kind:
kind_1 = [items for items in FashionITEM_Meta_JSON if kind in items]
for i in range(len(kind_1)):
kind_1[i] = kind
total_kind.extend(kind_1)
four_kind = []
for item in total_kind:
if item == 'JK' or item == 'JP' or item == 'CT' or item == 'CD' or item == 'VT':
item = 'O'
four_kind.append(item)
elif item == 'KN' or item == 'SW' or item == 'SH' or item =='BL':
item = 'T'
four_kind.append(item)
elif item == 'SK' or item == 'PT' or item == 'OP':
item = 'B'
four_kind.append(item)
else:
item = 'S'
four_kind.append(item)
print(four_kind) #total_kind에서 겉옷, 웃옷, 아래옷, 신발 4가지로 더 크게 나눔
#print(total_kind) # 전체 데이터 라벨링 하기 쉽게 어떤 item인지만 추출
O_kind = []
for item in total_kind:
if item == 'JK' or item == 'JP' or item == 'CT' or item == 'CD' or item == 'VT':
O_kind.append(item)
T_kind = []
for item in total_kind:
if item == 'KN' or item == 'SW' or item == 'SH' or item =='BL':
T_kind.append(item)
B_kind = []
for item in total_kind:
if item == 'SK' or item == 'PT' or item == 'OP':
B_kind.append(item)
S_kind = []
for item in total_kind:
if item == 'SE':
S_kind.append(item)코드가 굉장히 길어보이지만 사실 전체 아이템을 담는 것은 total_kind부분만 보면 된다. 아래는 후에 스포일 수도 있지만 분류가 사실 잘 되지 않아서 다양한 상황에 대해 보기 위하여 만든 것이다.
3. PCA 차원 축소
많은 사람들이 알고있는 PCA를 통한 축소이다.
sklearn에 보면 PCA module을 참고했다.
from sklearn.preprocessing import StandardScaler
# 위 dataframe값으로 PCA 진행
# Total_PCA는 n개의 구성요소로 PCA한 값의 dataframe
# princialDf은 Total_PCA에서 2개만 뽑음, +labeling
scaler = StandardScaler()
scaler.fit(LIST_INDEX)
train_feature_scaled = scaler.transform(LIST_INDEX)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(train_feature_scaled)
train_feature_reduced = pca.transform(train_feature_scaled)
#총 2603x4096에 대한 pca 결과
간단히 설명하자면 우리가 2603개의 아이템,각 아이템이 4096차원 즉 2603*4096 vector인 LIST_INDEX에 fit와 transform을 통해 PCA를 사용할 준비를 해야한다. 여기서 중요한 점은 정규화 를 해야한다는 점이다.정규화를 하지 않으면 일정한 data값이 아니기 때문에 몇몇 데이터에 의해 결과가 좋지 않을 수 있다. 위 코드에는 정규화를 안했는데 정규화를 하고 나서보니 원래 데이터가 이미 학습이 된 데이터라 그런지 정규화가 되어있었다...😂
다른 부분에 대한 점들은 생략하고 n_components만 본다면 몇 차원으로 줄일 것일지 정하는 것인데 시각화를 위해선 2 또는 3으로 설정한다.
시각화 코드
import matplotlib.pyplot as plt
labels = ['BL','CD','CT','JK','JP','KN','OP','PT','SE','SH','SK','SW','VT']
tsne_df = pd.DataFrame(data = train_feature_reduced
, columns = ['principal component 1', 'principal component 2'])
tsne_df['label'] = total_kind
fig = plt.figure(figsize = (8,8))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('Principal Component 1', fontsize = 15)
ax.set_ylabel('Principal Component 2', fontsize = 15)
ax.set_title('2 Component PCA', fontsize = 20)
colors=["#000000","#fb9a99","#33a02c","#a6cee3","#1f78b4","#b2df8a","#e31a1c","#fdbf6f","#ff7f00","#cab2d6","#6a3d9a","#b15928","#ffff99"]
for label, color in zip(labels, colors):
indicesToKeep = tsne_df['label'] == label
ax.scatter(tsne_df.loc[indicesToKeep, 'principal component 1']
, tsne_df.loc[indicesToKeep, 'principal component 2']
, c = color
, s = 30)
ax.legend(labels)
ax.grid()이것도 간단히만 설명하면 위에서 pca결과로 나온 data를 다시 dataframe으로 만들고 labeling을 해준뒤에 알맞은 값들을 집어 넣으면 된다.
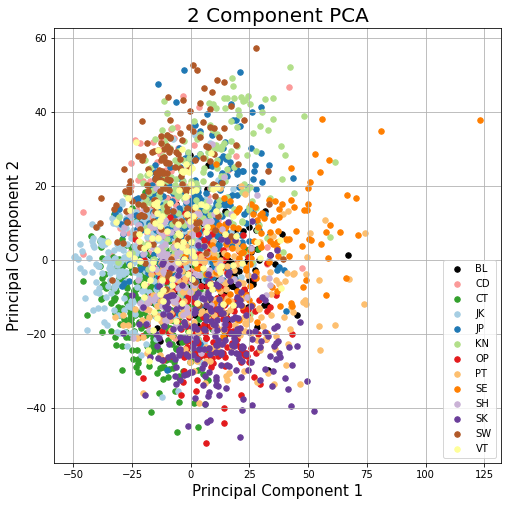
.png)
보면은 같은 아이템끼리 그래도 cluster를 이루고 있다. 하지만 다른 아이템들과 너무 중복되는 부분들이 많다. 이러면 아무리 잘 뭉쳐져 있어도 그게 어떤건지 모르게 된다. 따라서 아이템끼리 잘 나누어지도록 바꿔야했다.
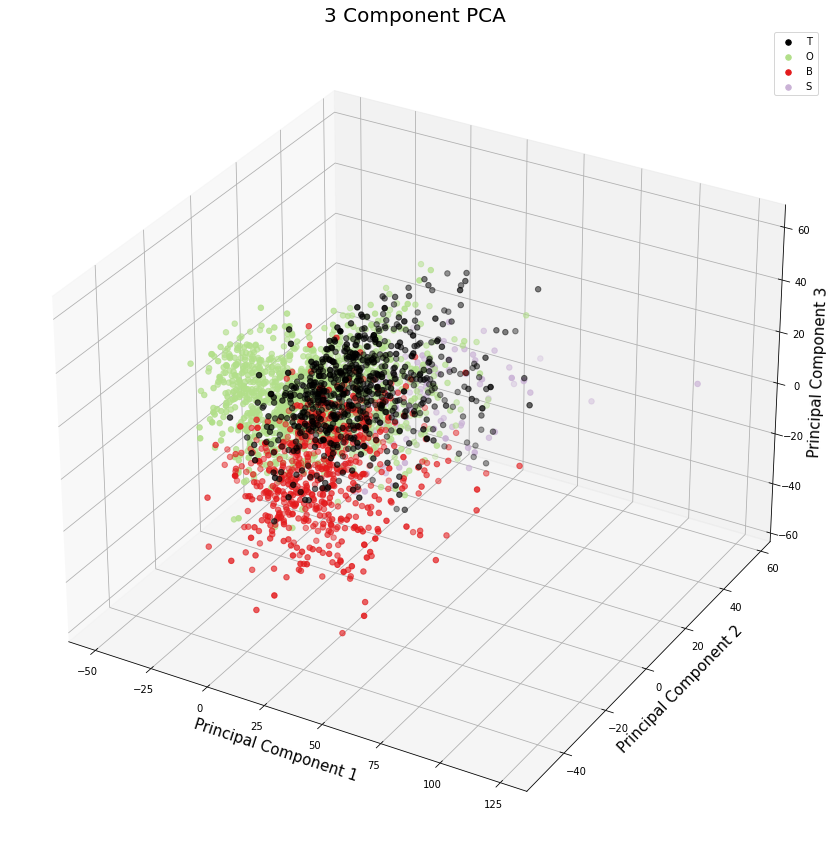
T,O,B,S는 겉옷, 외투, 하의, 신발로 13개가 4개로 줄어든 것이다. 이 사진을 보면 확실히 cluster가 잘 되었다.

구글링+논문 아카이브를 통해 cluster가 잘 이루어져 있는 경우에 tsne를 사용하면 차원축소가 잘된다고 보았다.
쓰다보니 너무 길어져서 tsne와 마지막 느낀점(?)을 다음 포스팅에 작성해야겠다.🤔
마지막으로 3차원에서 어떤 형태인지 확인해보자. (코드 생략)