
- 목표 :
- 과제 1 ~ 5 다 풀고 제출하기
- 퀴즈 다 풀고 제출하기- 결과 :
- 과제 1 ~ 5 다 풀고 제출하기 (O)
- 퀴즈 다 풀고 제출하기 (O)
1. 공부를 하며 고민한 내용, 고민 결과
- DataLoader에서 가져오는 batch data를 Model의 input으로 넣어주고 계산한
torch.nn.CrossEntropyLoss()의 결과값은 어떤 값으로 나올까?
for epoch in range(EPOCHS):
loss_val_sum = 0
for batch_in, batch_out in train_iter:
# Forward path
y_pred = M.forward(batch_in.view(-1, 28 * 28).to(device))
loss_out = loss(y_pred, batch_out.to(device))
# Update
optm.zero_grad()
loss_out.backward()
optm.step()
loss_val_sum += loss_out
loss_val_avg = loss_val_sum / len(train_iter)- 위에서
loss_val_avg을 "전체 데이터의 개수로 나누는 게 아닌" 총 batch의 개수(len(train_iter))로 나누는 것에서 의문이 생김
→ 그렇다면loss_out이 하나의 batch 안의 데이터 값들의 loss 평균인걸까?
→ documentation을 찾아보니 예상한 게 맞았음

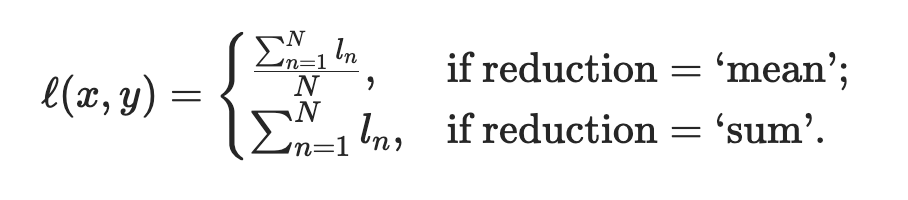
즉,
reduction='mean'이 default 값이고, 하나의 batch 안의 데이터 값들의 loss 평균을 반환하는 것
torch_tensor.detach().cpu().numpy()순서와torch_tensor.cpu().detach().numpy()순서의 차이는?
detach(): 기존 Tensor에서 gradient 전파가 안되는 새로운 텐서 생성
→ 단, storage를 공유하기에 detach로 생성한 Tensor가 변경되면 원본 Tensor도 똑같이 변함
- 변수에 gradient가 필요하면,
cpu().detach()로 쓰지만 결과가 저장되지 않기 때문에 cpu autograd edge(입력 Tensor로부터 출력 Tensor를 만들어내는 함수)는 금방 소멸됨detach().cpu()는 이 작업을 하지 않고, 속도가 더 빠름
→detach().cpu().numpy()순서로 사용하는 거로 기억해두자
2. 과제 수행 과정/과제 결과물에 대한 정리
np.set_printoptions(): Documentation
- 자주 쓰이는 3가지 정도 살펴보자 (참고 : https://seong6496.tistory.com/182)
precision(default=8): 소수점 반올림 (default: 소수점 8자리까지 반올림)threshold(default=1000): array를 길게 만들어 출력할 때 몇 개의 값을 볼 지 설정formatter: 출력 형식을 바꾸는 방법
- 동일한 Model, Data로 학습을 했을 때, optimizer만 바꾼다면 성능 차이가 많이 날까?
-
Data
-
optimizer 비교·결과 그래프
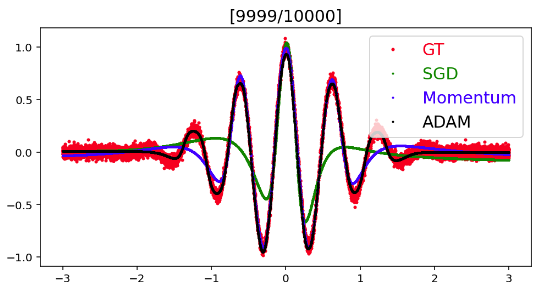
결론 : optimizer만 바꾸는 것만으로도 성능 차이가 많이 난다!
→Adam혹은RAdam을 먼저 써보는 게 좋은 결과를 보여줄 수 있을 것
-
결과 해석 (성능 :
Adam > Momentum > SGD)Adam(Adaptive Moment Estimation): momentum + adaptive learning rate을 합친 것- "adaptive learning rate"이란? : 어느 parameter에 대해서는 lr_rate를 올리고, 어느 parameter에 대해서는 lr_rate를 줄이는 것을 왔다갔다 하기 때문에 똑같은 base lr_rate를 갖고 있어도 훨씬 더 빠르게 학습이 되는 것!
Momentum: 이전의 gradient를 활용해서 다음 번에도 쓰겠다는 것이 SGD와의 차이점- 그럼 이게 왜 좋을까?
- 이전의 gradient를 활용하지 않으면, batch_size만큼의 데이터만 보고 말 것
- 근데 이전의 gradient 정보를 어느 정도 반영해서 update하기 때문에 데이터를 한 번에 더 많이 보는 효과가 생기는 것!
- 그럼 이게 왜 좋을까?
SGD: 너무 많은 iteration이 있어야 모든 데이터가 모두 다 converge할 때까지 갈 수 있음
-
loss가 제일 큰
peak 위주로 빠르게 학습이 되는 이유- squared loss를 쓰면, 제곱했을 때 큰 loss는 더 크게 증폭됨
- MSE를 쓰면, 많이 틀리는 곳을 금방 더 빨리 맞추게 되고, 상대적으로 적게 틀리는 곳에 덜 집중하게 됨
- 따라서 outlier가 있는 경우, MSE loss를 쓰는 게 마냥 좋지는 않다는 것을 알 수 있음
torch.nn.ReLU()에서inplace=True일 때와 False(default)일 때 뭐가 다른가?결론 :
- network 학습 시 error가 발생하지 않는 게 확실하면
inplace=True가능
(장점: memory 사용을 줄여줘서, Out of Memory 방지에 효과가 있음) - But 처음엔
False(default)로 하는 게 좋은 이유는, gradient를 계산할 때 inplace=True로 하면original value를 없앨 수 있어서 주의해서 사용해야 함
- network 학습 시 error가 발생하지 않는 게 확실하면
참고 :
3. 피어 세션
[ 데일리스크럼 ]
- 학습 목표 공유
- 모더레이터 선정
- 모각공
[ 피어 세션 ]
-
과제와 퀴즈에 관한 간략한 얘기를 공유
-
코테 스터디는? 지금은 여유가 없으니 추후에 해보자는 의견
-
Generative Model에서 배우는 autoencoder는 어디에 쓰는 건가?
→ CV : GAN
→ NLP : GPT -
Transformer의 encoder가 뱉어 주는 결과는 뭔가?
→ latent variable (ex. 만국 공용어 vector)
→ (cf) 촘스키, 변형 생성 문법 -
Transformer에도 padding이 쓰이는가?
→ 쓰인다! + attention-mask에 대한 개념
→ 참고 : https://huggingface.co/docs/transformers/v4.21.2/en/glossary#attention-mask
4. 회고
- 오늘의 모더레이터 : 정현님
- 오늘은 실습과 강의를 통해 공부했던 MLP, Optimization, CNN, LSTM, Transformer(Multi-head Attention)에 관한 과제를 모두 풀고 제출했음
- Transformer에 대해 집중적으로 공부하고 분석해보고 싶었는데, 양질의 강의와 과제, 퀴즈, 멘토링 등으로 공부해볼 수 있어 뿌듯한 시간이었음!

NLP ML Engineer, MLOps