
Intro
선택의 기로
저번주부터 교육과정과 더불어 스프링을 활용한 사이드 프로젝트를 시작하였다. 공부하는 것과 공부하는 것을 적용해보는 것은 그리 어렵지 않은데, 정말로 힘들고 어려웠던 것은 공부한 것 중 무엇을 적용할지 선택할 때이다.
학습 수준의 규모에서는 배운 것을 적용해도 괜찮지만, 실무 수준의 규모에서는 섣불리 적용하면 안되는 것들이 너무나 많았다. 모든 것을 실무 기준으로 바라보고 실무에서 쓰니까 적용하고 사용하지 않는다고 적용하지 않는 것은 아니지만 실무라는 기준 자체가 내가 공부했던 것을 적용하는데 큰 영향을 주었다.
그래서 닥치는대로 여러 문서들을 살펴보았다. 공식문서도 찾아보고 다른 개발자분들의 소스를 살펴보고, 해외 개발자분들의 자료도 참고해보았다. 결론은 "적재적소에 알맞는 기술을 선택해서 사용해야 한다." 였다. 돌고 돌아 원점인 것 같지만, 한편으론 존재하지 않는 정답을 찾아 헤멘 것 같은 느낌도 들었다.
하지만 개발자도 아닌 고작 비기너인 내가 상황에 맞는 선택을 잘할 수 없는게 당연하다는 생각도 들었다. 물론 좋은 선택을 하기 위해 내가 할 수 있는 최선을 다할 것이다. 그래도 그 선택이 좋지 못하다면 겸허히 받아들이고 다음엔 같은 선택을 하지 않도록 노력할 수 있지 않을까?
Day - 61
도커와 함께 자주 언급되는 쿠버네티스에 대해서 배우게 되었다. 쿠버네티스의 기본적인 개념구조를 짧은 시간에 이해하기엔 양이 너무나도 많았다. 여러 서비스를 다수의 컨테이너 위에서 운영하기 위해서 쿠버네티스가 어떻게 동작하는지, 왜 필요한지 등 궁금한 점에 대해서 조금씩 공부해 나가려 한다.
Kubernates(k8s, kube)가 등장하게 된 이유는?
Kubernates(이하 쿠버네티스) 공식 문서를 살펴보고 쿠버네티스가 무엇이고 어떻게 등장하게 되었는지 간단하게 정리해보려 한다.
쿠버네티스란?
쿠버네티스는 컨테이너화된 워크로드와 서비스를 관리하기 위한 이식성이 있고, 확장 가능한 오픈소스 플랫폼이라고한다. 즉 컨테이너 작업을 자동화하는 오픈소스 플랫폼이다.
컨테이너 관리를 위한 쿠버네티스의 등장
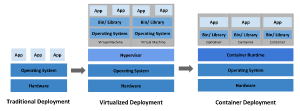
전통적인 배포 시대에서 가상회된 배포시대를 지나 컨테이너 개발 시대로 들어서면서 쿠버네티스는 도커와 함께 많은 인기를 누리게 되었다.
컨테이너(Container)란 소프트웨어 서비스를 실행하는 데 필요한 특정 버전의 프로그래밍 언어 런타임 및 라이브러리와 같은 종속 항목과 애플리케이션 코드를 함께 포함하는 경량 패키지이다. 컨테이너는 VM과 유사하지만 격리 속성을 완화하여 애플리케이션 간에 운영체제(OS)를 공유한다.
VM 가상화의 경우 무거운 OS를 설치해야 한다는 점이 큰 당점이었는데, 소규모의 서비스 하나를 실행시키기 위해 보다 무거운 OS를 설치해야할 경우가 있었다. 그런데 컨테이너 기술은 별도의 OS 설치할 필요가 없기 때문에 가상화 기술보다 빠르고 높은 효율성을 보여주었다. 그렇게 Docker가 등장하게 되었고 컨테이너를 다루는 작업이 많이 알려지게 되었다.
그러나 Docker는 하나의 서비스를 컨테이너를 통해 배포하는 1:1 작업에 특화되어 있어 보다 많은 서비스를 운영할 경우 컨테이너를 일일이 관리하는 기능은 제공되지 않았다.
그렇게 여러 서비스를 운영하기 위해 다수의 컨테이너를 편리하게 관리할 수 있는 기능을 제공하는 컨테이너 오케스트레이터인 쿠버네티스가 등장하게 되었다. 쿠버네티스는 컨테이너를 보다 탄력적으로 관리할 수 있고, 분산 시스템을 적용할 수 있는 프레임워크를 제공해준다.
쿠버네티스가 제공하는 이점들은?
공식문서의 내용을 살펴보면 쿠버네티스가 제공하는 이점들은 다음과 같다.
서비스 디스커버리와 로드 밸런싱
쿠버네티스는 DNS 이름을 사용하거나 자체 IP 주소를 사용하여 컨테이너를 노출할 수 있다. 컨테이너에 대한 트래픽이 많으면, 쿠버네티스는 네트워크 트래픽을 로드밸런싱하고 배포하여 배포가 안정적으로 이루어질 수 있다.
스토리지 오케스트레이션
쿠버네티스를 사용하면 로컬 저장소, 공용 클라우드 공급자 등과 같이 원하는 저장소 시스템을 자동으로 탑재 할 수 있다.
자동화된 롤아웃과 롤백
쿠버네티스를 사용하여 배포된 컨테이너의 원하는 상태를 서술할 수 있으며 현재 상태를 원하는 상태로 설정한 속도에 따라 변경할 수 있다. 예를 들어 쿠버네티스를 자동화해서 배포용 새 컨테이너를 만들고, 기존 컨테이너를 제거하고, 모든 리소스를 새 컨테이너에 적용할 수 있다.
자동화된 빈 패킹(bin packing)
컨테이너화된 작업을 실행하는데 사용할 수 있는 쿠버네티스 클러스터 노드를 제공한다. 각 컨테이너가 필요로 하는 CPU와 메모리(RAM)를 쿠버네티스에게 지시한다. 쿠버네티스는 컨테이너를 노드에 맞추어서 리소스를 가장 잘 사용할 수 있도록 해준다.
자동화된 복구(self-healing)
쿠버네티스는 실패한 컨테이너를 다시 시작하고, 컨테이너를 교체하며, '사용자 정의 상태 검사'에 응답하지 않는 컨테이너를 죽이고, 서비스 준비가 끝날 때까지 그러한 과정을 클라이언트에 보여주지 않는다.
시크릿과 구성 관리
쿠버네티스를 사용하면 암호, OAuth 토큰 및 SSH 키와 같은 중요한 정보를 저장하고 관리 할 수 있다. 컨테이너 이미지를 재구성하지 않고 스택 구성에 시크릿을 노출하지 않고도 시크릿 및 애플리케이션 구성을 배포 및 업데이트 할 수 있다.
쿠버네티스가 필요한 이유는?
쿠버네티스가 필요한 이유를 Container, MicroService, DevOps 3가지를 통해 설명할 수 있다.
컨테이너(Container)
컨테이너 개발 시대인 만큼 컨테이너의 다양한 장점을 기반으로 애플리케이션을 개발하려는 수요가 늘어나고 있다. 쿠버네티스는 가상화 기술이 아닌 컨테이너 기술을 기반으로 개발된 애플리케이션을 관리하고 제공해준다.
또한 앞에서 언급한대로 다수의 컨테이너를 보다 손쉽게 관리, 확장할 수 있어 매우 유용하다. 그러므로 컨테이너 기반의 애플리케이션 개발 수요가 증가하는 요즘 트렌드에서 쿠버네티스는 필요하다.
마이크로서비스(MicroService)
하나의 애플리케이션을 여러개의 모듈로 쪼개어 개발하는 마이크로서비스 구조가 등장하게 되었다. 마이크로서비스는 독립적인 기능들을 개별 프로세스들로 나누어 실행하고, 기능별로 독립적인 업데이트가 가능하다.
쿠버네티스는 각 기능들을 컨테이너를 통해 관리하게 되는데, 이 떄, 여러 개의 컨테이너를 그룹지어서 Service라는 객체로 관리하게 된다. 결국 Service 객체를 통해 마이크로서비스 기반의 애플리케이션을 관리할 수 있기 때문에 쿠버네티스는 필요하다.
데브옵스(DevOps)
CD(Continuous Delivery)는 어플리케이션의 배포 과정을 자동화하여, 개발자가 어플리케이션 배포 과정에 일일이 관여하지 않도록 도와준다. 이러한 CD의 등장으로 개발자는 애플리케이션의 비즈니스 로직을 개발하는데 더욱 집중할 수 있게 되었다.
쿠버네티스는 이러한 CD 기능을 제공할 뿐만 아니라 애플리케이션 상태를 지속적으로 점검하여, 문제가 발생했다면 자동으로 복구할 수 있는 셀프힐링(self-healing) 기능을 제공한다.
Day - 62
Spring에서의 설정 파일 분리
application.yml 파일에 DB 접속정보 등 민감한 정보를 그대로 둔 채로 Git에 업로드하고 있음을 알게되었다. 학습이나 실습 수준의 프로젝트에서는 크게 상관이 없겠으나 앞으로 실무 위주의 프로젝트를 진행하려면 이러한 설정 파일을 분리하는 습관부터 들여야겠다고 생각이 들어서 분리하는 과정을 기록하려 한다.
먼저 기존에 사용하던 application.yml 설정파일을 살펴보자.
application.yml
spring:
datasource:
driver-class-name: ...
url: ...
username: ...
password: ...
jpa:
hibernate:
ddl-auto: none
properties:
hibernate:
format_sql: true
show_sql: true
logging:
level:
org.hibernate.type.descriptor.sql: trace잘 보면 JPA로 연동할 DB의 접속정보가 그대로 드러남을 알 수 있다. 이를 어떻게 감출 수 있을까?
설정 파일 분리하기
application.yaml 파일에서 노출되면 안되는 민감한 정보만 담은 설정파일을 별도로 만들고 해당 설정파일은 노출되지 않도록 하기 위해 설정 파일을 분리해보기로 하였다.
spring.profiles.inclue라는 옵션을 통해서 설정 파일을 분리시킬 수 있었다. DB 접속정보를 application-db.yml 파일을 만들어서 작성하고 application.yml 파일에 spring.profiles.include 옵션을 적용하였다.
applicaion.yml
spring:
profiles:
include: dbapplicaion-db.yml
spring:
datasource:
driver-class-name: ...
url: ...
username: ...
password: ...
jpa:
hibernate:
ddl-auto: none
properties:
hibernate:
format_sql: true
show_sql: true이 상태로 서버를 실행하여 설정 파일의 적용여부를 살펴보니 정상적으로 DB 연동이 됨을 확인할 수 있었다.
그런데, 관련 내용을 찾아보던 중에 Spring Boot 2.4 버전 이상부터는 spring.profiles.include 옵션을 사용하지 않는다고 한다. 그래서 설정 파일을 분리하는 방식을 어떻게 사용할 수 있는지 Spring Boot 2.4 버전의 공식 릴리즈 문서를 찾아보았다.
이제 spring.profiles 속성은 Deprecated 되어 사용하지 않는다고 한다. 실제 yml 파일에서도 profiles 속성을 작성하면 경고문구를 확인할 수 있었다.

그래서 위와 같이 작성했었던 spring.profiles 속성은 사용하지 말아야 한다고 하니 아래와 같이 spring.config.activate.on-profile 속성을 사용해야 함을 기억하자.
spring:
config:
activate:
on-profile: [분리할 속성명]운영 화경을 기준으로 Spring Profiles 설정
그런데, DB 접속정보 뿐만 아니라 로컬에서 테스트하는 환경과, 실제 개발환경 및 운영환경 범위마다 설정들이 달라질 것 같아 DB 접속정보만을 분리하는 것이 아닌 운영 환경을 기준으로 설정 파일을 분리하기로 하였다.
- local
- dev
- prod
위 3가지 속성을 기준으로 구분하여 local은 로컬 및 테스트 환경, dev는 개발환경, prod는 운영환경이라고 가정하여 설정파일을 배치해보자.
application-local.yml
spring:
config:
activate:
on-profile: local
# DB 정보 등 이하 생략application-dev.yml
spring:
config:
activate:
on-profile: dev
# DB 정보 등 이하 생략application-prod.yml
spring:
config:
activate:
on-profile: prod
# DB 정보 등 이하 생략src/main/java 하위의 resources 디렉토리에 위 3가지의 yml 설정파일들을 생성하였다. 마지막으로 application.yml 파일을 수정하자.
application.yaml
spring:
profiles:
active: local
group:
local: local
dev: dev
prod: prod
# 이하 생략application.yml 설정 파일은 애플리케이션이 실행 될 때 작성된 Profile 정보를 기본적으로 참조한다. 해당 파일에서 설정한 내용을 살펴보자.
먼저 spring-profiles-active 옵션을 통해 기본으로 활성화할 profile을 local로 설정한다. 그리고 spring-profiles-group 옵션을 통해서 profile들의 집합인 group을 정의하였다. 여기서 운영환경이 local이냐, dev냐, prod냐에 따라서 알맞는 설정파일을 끼워서 사용할 수 있도록 하였다.
이제 서버를 실행해서 local profile로 설정되는지 확인해보자.
The following 1 profile is active: "local"정상적으로 local profile이 등록된 것을 확인할 수 있었다. 이처럼 프로젝트 구축 전 설정과 관련된 설계에 대해서 알아보면서 설계가 좋으면 나중에 추가적인 수정 작업을 덜어낼 수 있겠구나 생각이 들었고, 피치 못하게 수정작업이 일어나더라도 본인과 동료가 수정하기 쉽도록 구성해놓아야겠다고 느끼게 되었다.
Day - 63
Soft Delete에 대해서
데이터를 삭제하는 방법에는 Hard Delete 방식과 Soft Delete 방식이 있다. 이 두가지는 다음과 같다.
Hard Delete 방식은 delete 쿼리를 날려서 데이터베이스에서 해당되는 데이터를 실제로 삭제하는 방법이다.
Soft Delete 방식은 실제로 데이터베이스에서 데이터를 삭제하는 것이 아니라, 테이블에 deleted_at와 같은 컬럼을 추가한 후, update 쿼리를 날려서 deletedAt 컬럼에 삭제 시간을 설정해주는 방법이다. Soft Delete를 통해 deletedAt 컬럼에 값이 설정된 모델은 삭제가 되었다고 판단하여 기본적인 쿼리의 결과에는 포함되지 않는다.
@Where과 @SQLDelete 어노테이션
이번 스프링 사이드 프로젝트를 진행하면서 데이터 유실 방지 차원에서 Hard Delete 없이 Soft Delete 방식을 채용하기로 하였다.
사실 Soft Delete 작업을 개발자가 일일이 신경써야 한다는 것은 굉장히 번거로울 수 있는데, 이를 좀 더 편하게 사용할 수는 없을까? 라는 생각이 들었다.
그렇다면 스프링에서는 Soft Delete 방식을 어떻게 사용할 수 있도록 제공하는지 살펴보고 적용해보자.
이것저것 자료를 찾아보니 JPA의 구현체인 Hibernate에서는 @Where @SQLDelete 어노테이션으로 Soft Delete를 구현할 수 있게 해준다고 한다.
@SQLDelete어노테이션은 특정 엔티티를 조회하는 모든 쿼리에 where 조건을 사용할 수 있게 해준다.@Where어노테이션은 삭제할 때 delete 쿼리 대신에 다른 구문을 실행할 수 있도록 해준다.
@SQLDelete 어노테이션
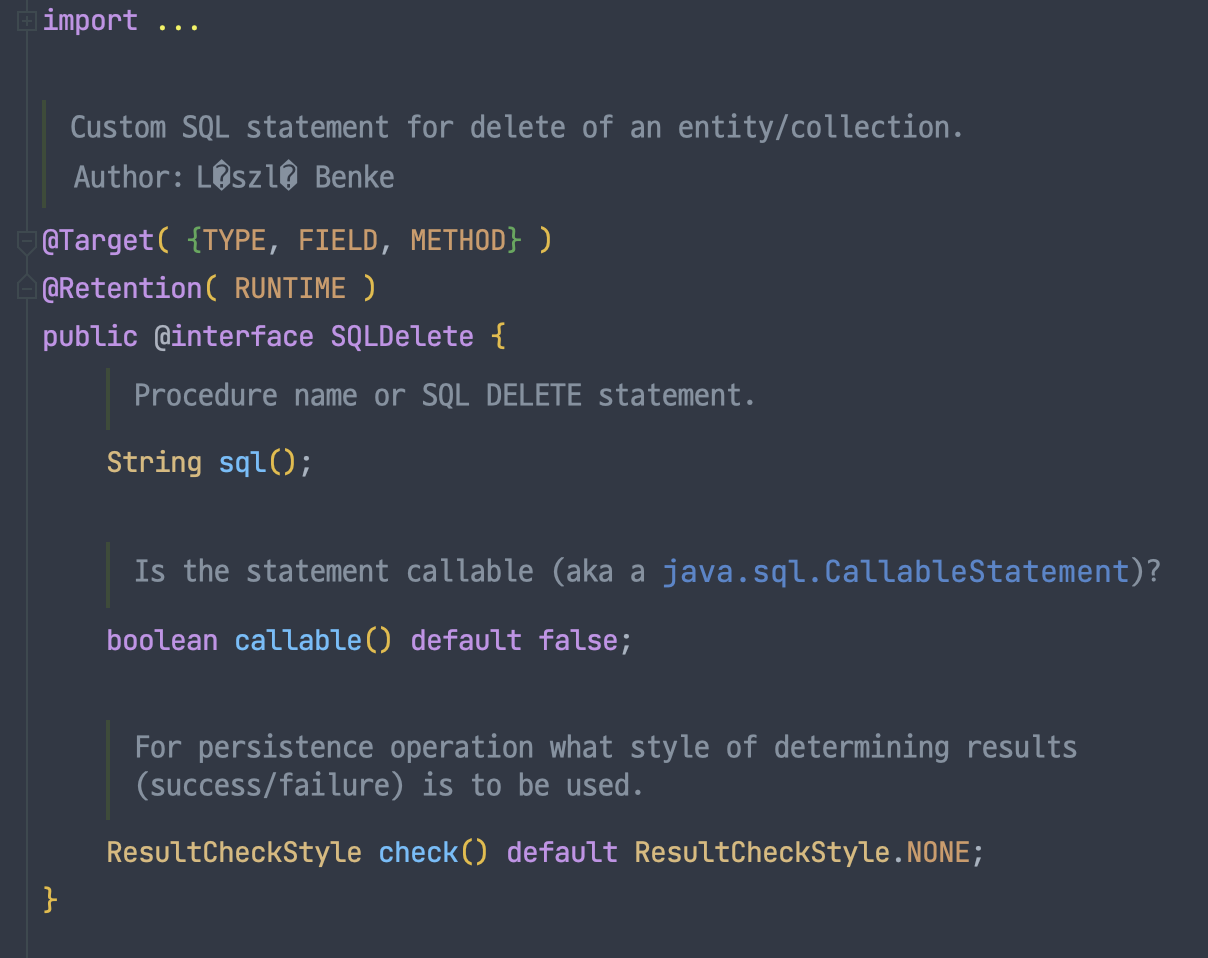
먼저 @SQLDelete 어노테이션이 정의된 내용을 살펴보았다. 해당 어노테이션을 통해서 Entity나 Collection을 삭제하기 위한 커스텀 SQL 구문을 명시할 수 있다고 한다.
나의 프로젝트에서는 삭제 작업을 할 때 deleted_at과 같은 컬럼에 삭제 시간 일정등을 남겨 해당 데이터가 삭제 된 데이터임을 마킹해야 한다.
그렇다면 @SQLDelete 어노테이션을 통해서 DELETE 구문 대신에 원하는 UPDATE 구문을 사용하여 deleted_at 컬럼에 삭제시간을 기록하도록 해야한다.
Member.java
@SQLDelete(sql = "UPDATE member SET deleted_at = CURRENT_TIMESTAMP where id = ?")
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long memerId;
// 이하 생략
}사용자와 관련된 Member라는 Entity가 있다고 가정하자.
해당 Entity에 @SQLDelete 어노테이션을 붙인다면 Member Entity를 삭제할 때는 해당 엔티티를 대상으로 명시한 UPDATE member SET deleted_at = CURRENT_TIMESTAMP where id = ? 이라는 SQL문을 사용할 수 있는 것이다.
@Where 어노테이션
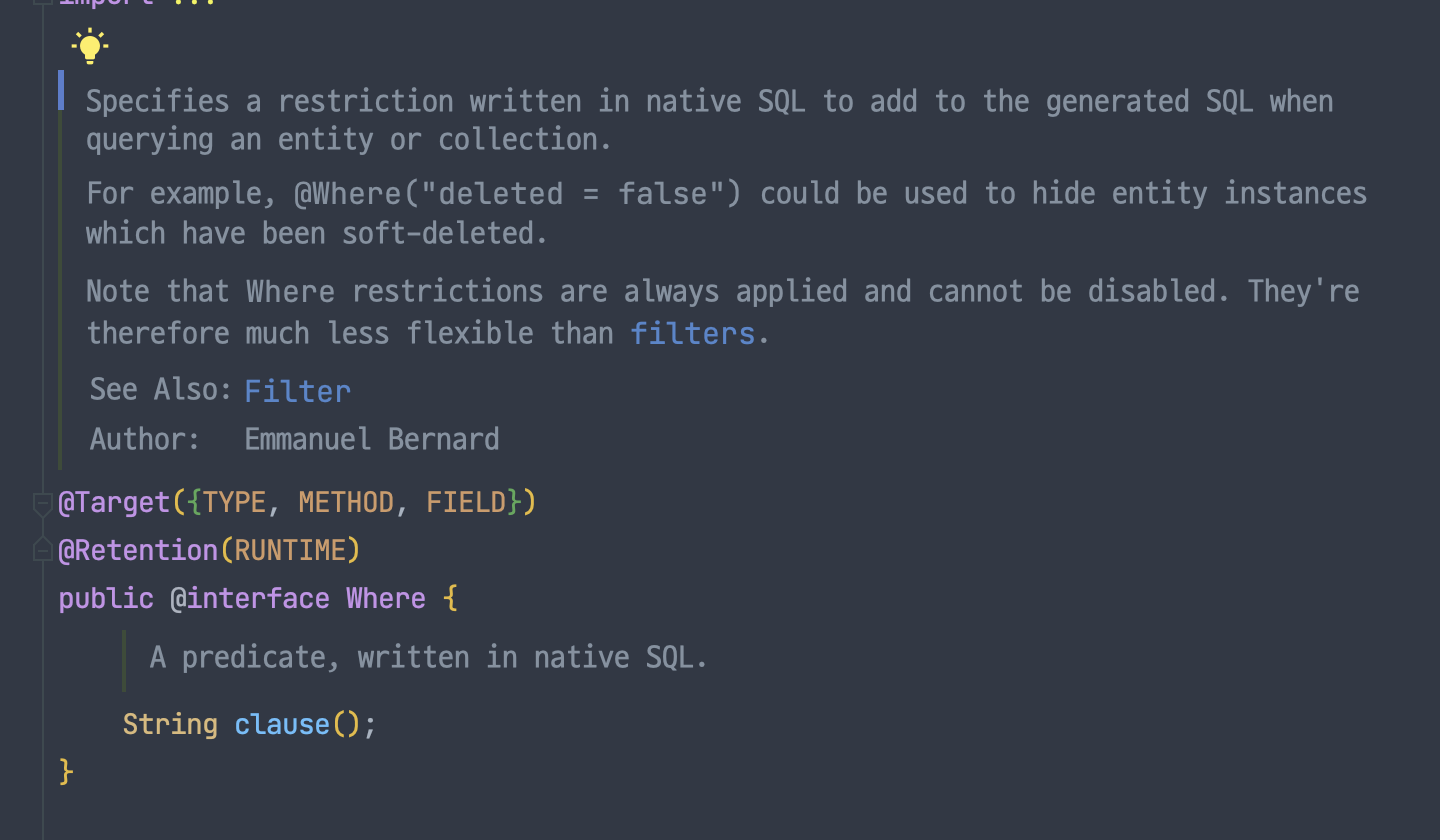
다음으로 @Where 어노테이션이 정의된 내용을 보니 일반적으로 soft delete를 위해 사용된다고 명시되어 있었다.
또한, 내용을 간략하게 번역해보니 @Where 어노테이션이 붙은 Entity를 조회할 때 사용할 where 절을 정의할 수 있다고 하며 해당 where 구문은 SQL로 작성되어야 한다고 한다.
Soft Delete 방식을 통해 deletedAt 컬럼에 값이 설정되었다면, 해당 데이터는 삭제된 것으로 간주하였기 때문에 다른 곳에서 조회할 수 있으면 안된다. 그런데 @Where 어노테이션을 통해서 해결할 수 있다는 것이다.
Member.java
@SQLDelete(sql = "UPDATE member SET deleted_at = CURRENT_TIMESTAMP where member_id = ?")
@Where(clause = "deleted_at is NULL")
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long memerId;
// 다른 속성 생략
private LocalDateTime deletedAt;
}위에서 정의한 Member Entity에 위와같이 @Where 어노테이션을 붙인다면 memberId로 데이터를 가져오는 쿼리에 deleted_at is NULL 이라는 where절을 자동으로 추가해준다.
이 때, Member Entity에는 deletedAt이라는 속성이 존재해야 하기 때문에 Entity에 해당 속성을 추가한다.
deletedAt 속성은 공통 컬럼으로 사용될 수 있기에 추후에는 JPA Auditing을 사용하는 BaseTimeEntity에 따로 명시하면 된다.
프로젝트에 적용하기
이제 @Where과 @SQLDelete 어노테이션을 사용하여 정말로 실제 데이터 삭제가 되지 않고 deletedAt 컬럼에 삭제시간을 기록하는지 확인해보자.
MemberRepositoryTest.java
@Test
public void 사용자_삭제() {
// soft delete 방식으로 삭제되어야 한다.
// given
Member member1 = memberRepository.save(Member.builder()
.type(Type.LOCAL)
.email("del1@kakao.com")
.nickname("del1")
.password("kakao")
.role(Role.BASIC)
.build());
Member member2 = memberRepository.save(Member.builder()
.type(Type.LOCAL)
.email("del2@kakao.com")
.nickname("del2")
.password("kakao")
.role(Role.BASIC)
.build());
Long member1Id = member1.getMemberId();
Long member2Id = member2.getMemberId();
// member1과 member2를 삭제할 때 soft delete가 적용되어 deltedAt 컬럼에 값이 설정된다.
memberRepository.deleteById(member1Id);
memberRepository.deleteById(member2Id);
// when
// 삭제 이후 member1과 member2는 조회되지 않는다.
int allMemberCnt = (int) memberRepository.count();
System.out.println("all member cnt: " + allMemberCnt);
// then**텍스트**
assertThat(allMemberCnt).isEqualTo(0);
}위와 같이 MemberRepositoryTest 테스트 클래스에서 사용자_삭제 라는 테스트 메소드를 통해 두명의 회원 정보를 추가하고 삭제한뒤 모든 회원의 수를 조회해보았다.
Test Output
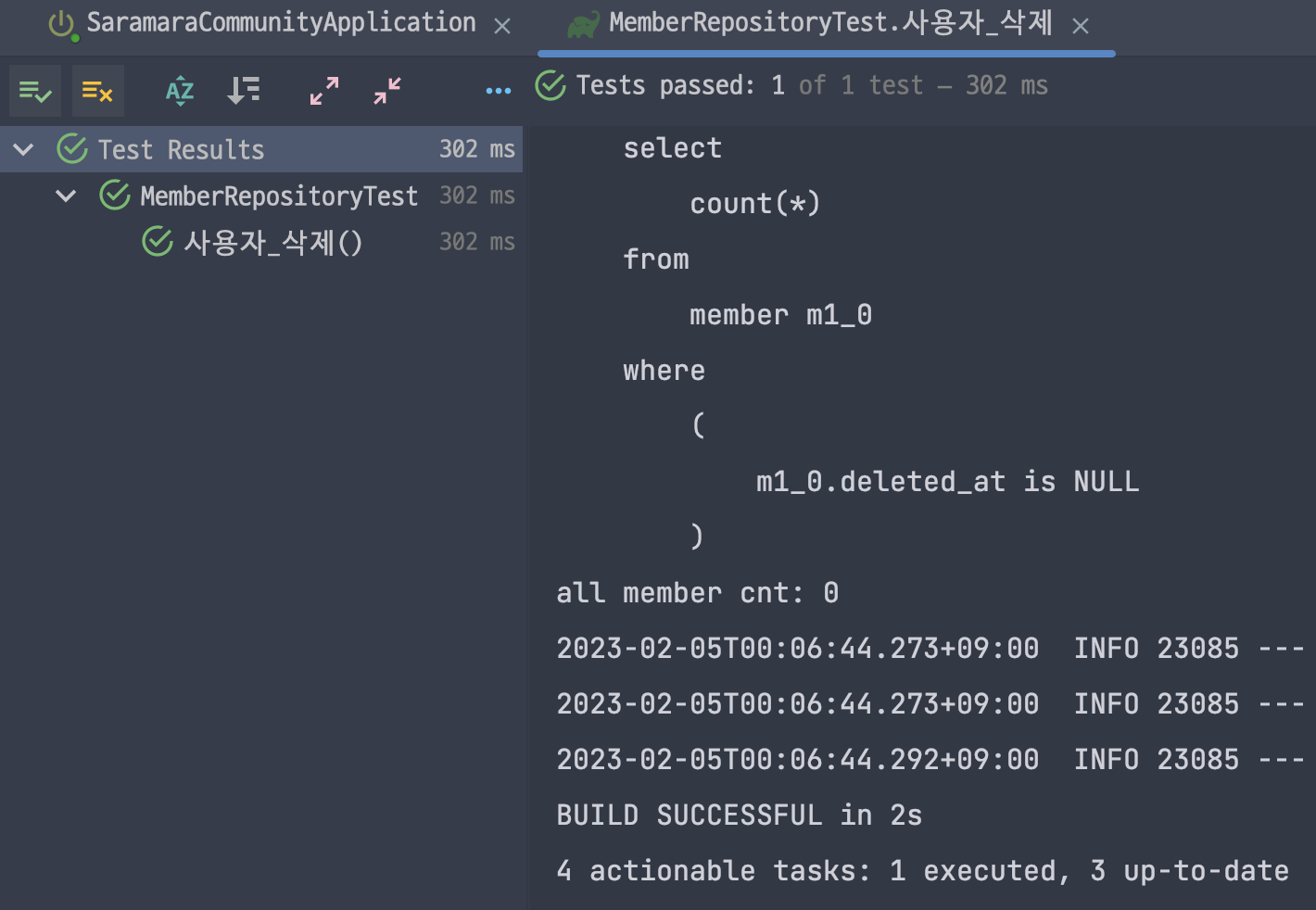

먼저 테스트는 정상적으로 통과하였다. DB 데이터를 확인하니 Soft Delete가 적용되어 실제로 Member 데이터를 삭제하지 않고 deletedAt 컬럼에 삭제시간을 설정한 것을 확인할 수 있었다. 또한, 모든 회원의 수를 count() 메소드로 가져올 때 삭제된 회원은 제외하여 0을 출력함을 알 수 있었다.
이처럼 Soft Delete 방식을 통해 실제로 데이터를 삭제시키지 않고 삭제된 것처럼 데이터의 상태를 관리할 수 있었다. 물론 이 방식이 절대적으로 옳은 것은 아니다. DB의 데이터가 기하급수적으로 쌓이게 되면 이 또한 치명적일 수 있음을 명심하자. 앞으로 데이터의 보관 여부가 굉장히 중요한 상황을 맞이한다면 Soft Delete 방식을 채용하는 것을 고려해볼 수 있을 것 같다.
Day - 64
매우 위험한 ddl-auto 옵션
ddl-auto 옵션에 대한 내용을 보기에 앞서 개발바닥 유튜브에 올라온 재난급 서버 장애내고 개발자 인생 끝날뻔 한 썰 이라는 동영상을 보게 되었다. ddl-auto라는 옵션 하나가 사내 서비스에 미치는 영향은 생각보다 심각할 수 있다는 생각이 들었다.
JPA에서는 spring.jpa.hibernate.ddl-auto 옵션을 사용하여 데이터베이스 초기화 전략을 결정할 수 있다. 해당 옵션을 설정 파일에 작성하고 애플리케이션을 실행하게 되면 토대로 JPA가 지정된 초기화 전략을 수행해준다.
DDL이란 데이터 정의어(Data Defination Language, DDL)로 데이터베이스의 테이블의 생성, 변경, 삭제를 담당하는 명령어이다. 대표적으로 CREATE, ALTER, DROP, RENAME, TRUNCATE가 있다.
ddl-auto 옵션의 종류는?
ddl-auto 옵션에 작성할 수 있는 종류로는 create, create-drop, update, validate, none이 있다.
create
SessionFactory가 시작하는 시점에 기존 테이블을 삭제한 후 테이블을 생성한다. DROP과 CREATE가 함께 실행된다고 보면 된다.
create-drop
create 옵션과 동일하지만 SessionFactory가 종료되는 시점에 테이블을 삭제한다.
update
테이블과 매핑된 엔티티, 즉 스키마에 변경점이 있다면 변경점을 적용한다.
validate
테이블과 매핑된 엔티티가 정상 매핑되었는지 확인한다. 변경된 스키마가 있다면 변경점을 출력하고 애플리케이션을 종료한다.
none
초기화 전략을 수행하지 않는다. 즉 아무것도 실행되지 않는다.
ddl-auto 옵션을 사용할 때 주의할 점
앞에서 본 영상을 보면 알 수 있듯이 실제 서비스가 배포된 운영 서버의 DB로는 crate나 create-drop, update 옵션은 금기시 해야 한다. 해당 옵션의 존재만으로 데이터의 유실 가능성이 매우 높아지기 때문이다. 그래서 실제 운영 환경에서는 none 옵션을 사용하는 것이 바람직하다.
프로젝트 개발 초기에는 create나 update를 통해 테이블 생성여부를 편하게 확인하는 것이 좋을 수 있다. 다만, 추후에는 validate 옵션으로 변경하여 운영하는 것이 좋다.
사실 가장 안전한 방법은 로컬 환경을 제외한 나머지 모든 환경에서는 개발자가 직접 DB에 접근하여 쿼리를 날려서 확인하는 방법이 아닐까?
ddl-auto 옵션 실습하기
그렇다면 ddl-auto 옵션을 통해 어떻게 테이블을 만들어주는지 직접 확인해보자. 여기선 create, create-drop, update 옵션만 실습해보려 한다. 먼저 create 옵션을 설정하고 애플리케이션을 실행해보았다.
ddl-auto: create
spring:
hibernate:
ddl-auto: createIDE Console log
Hibernate:
drop table if exists board
Hibernate:
drop table if exists board_cate_set
Hibernate:
drop table if exists member
Hibernate:
create table board (
...
)
Hibernate:
create table board_cate_set (
...
)
Hibernate:
create table member (
...
)다음과 같이 매핑된 테이블을 먼저 drop하고 create하여 생성하는 것을 알 수 있다. 다음으로 create-drop 옵션을 적용해보았다.
ddl-auto: create-drop
spring:
hibernate:
ddl-auto: create-dropIDE Console log - Application start
Hibernate:
drop table if exists board
Hibernate:
drop table if exists board_cate_set
Hibernate:
drop table if exists member
Hibernate:
create table board (
...
)
Hibernate:
create table board_cate_set (
...
)
Hibernate:
create table member (
...
)IDE Console log - Application end
Hibernate:
drop table if exists board
Hibernate:
drop table if exists board_cate_set
Hibernate:
drop table if exists member애플리케이션을 실행했을 때는 create 옵션과 동일하게 매핑된 테이블을 drop하고 create했지만, 애플리케이션을 종료하면 drop을 실행하여 테이블을 삭제하는 것을 알 수 있었다.
update 옵션의 경우는 엔티티에 변경점이 없으면 아무것도 실행하지 않는다. 그래서 Member 엔티티에서 nickname이라는 속성을 username으로 변경한 후 애플리케이션을 실행하였다.
ddl-auto: update
spring:
hibernate:
ddl-auto: updateIDE Console log
Hibernate:
alter table if exists member
add column username varchar(10) not nullnickname에서 username으로 변경된 필드를 DB에 바로 수정하게 된다.
이렇게 ddl-auto 옵션, JPA에서 제공하는 데이터베이스 초기화 전략에 대해서 알아보았다. 데이터베이스 초기화 전략은 쉽게 설정하여 쉽게 사용할 수 있지만 그만큼 리스크가 크기 때문에 ddl-auto 옵션의 설정 값을 항상 유의하면서 사용해야 함을 느꼈다.
Day - 65
AWS EC2와 RDS에 대해서
AWS(Amazon Web Service)는 클라우드 서비스로써 웹 서비스 상에서 보다 정교한 애플리케이션을 구축할 수 있도록 지원해주는 클라우드 컴퓨팅 플랫폼이다.
AWS에서 EC2와 RDS를 배우게 되었다. EC2에서 인스턴스를 만들고, RDS에서 데이터베이스를 생성하여 EC2와 RDS를 연결해보는 실습을 하면서 EC2와 RDS가 각각 어떤 역할을 수행하고 어떤 의도로 만들어졌는지 살펴보려 한다.
해당 내용에 대해서는 amazon의 EC2 문서와 RDS 문서에서 살펴본 내용 위주로 정리하였다.
EC2란?
EC2란 AWS에서 제공하는 클라우드 컴퓨팅 서비스이다. EC2를 이용한다면 아마존으로부터 한 대의 컴퓨터를 임대하여 사용한다고 볼 수 있다.
EC2를 사용한다면 하드웨어를 구축하는 비용과 시간을 절감하여 더욱 빠르게 애플리케이션을 개발하여 배포할 수 있다. 사용자가 직접 인스턴스를 제어할 수 있기 때문에 용량을 늘리거나 줄일 수 있고 사용한 만큼 비용이 청구되기 때문에 상대적으로 저렴하다고 볼 수 있다. 더군다나 보안적인 면에서 네트워크를 구성하거나 스토리지를 구성하는데 효과적이다.
RDS란?
RDS(Relational Database Service)는 AWS에서 관계형 데이터베이스를 더 쉽게 설치 및 운영 그리고 확장할 수 있는 웹 서비스이다. 데이터베이스를 업데이트하거나 백업하는 등 데이터베이스의 복잡한 관리 절차들을 AWS에서 자동으로 관리해준다.
RDS는 MySQL, Oracle, SQL Server, PostgreSQL, MariaDB, Microsoft SQL Server 그리고 MySQL, PostgreSQL과 호환이 되는 Aurora DB를 지원한다.
EC2와 RDS를 어떻게 사용할까?
AWS에서 EC2에서 데이터베이스를 사용하는 방법은 두가지 방법이 있다.
- EC2에 직접 DB를 설치하는 방법
- RDS를 이용해 서비스를 하는 방법
아무래도 EC2에 직접 데이터베이스를 설치한다면, 사용자가 직접 데이터베이스를 관리해야 한다. 직접 리눅스 위에 DB를 설치하고 설치된 DB를 관리해야 하기 때문이다.
RDS를 사용한다면, 데이터베이스 설정이나 운영, 백업 등의 관련된 부분을 AWS에서 관리해주기 때문에 개발자 입장에서는 관리하는데 신경을 쓰지 않고 애플리케이션 개발에 집중할 수 있다. 다만, RDS를 사용하면 별도로 부가요금을 지불해야 한다.
RDS를 꼭 사용해야 할까?
결국 EC2에 데이터베이스를 설치하여 이용하는 것과 RDS를 이용해 데이터베이스를 이용하는 방법 중에서 무엇이 좋을까?
그래서 RDS를 사용해야 할지 말지 선택의 기로에 서있을 때는 진행하는 프로젝트가 RDS를 사용할 정도의 규모인지, RDS를 사용하며 발생할 부가 요금을 부담할 수 있는지 정도를 고려하여 데이터베이스를 운영해야 한다.
내 입장에서는 RDS를 사용한다면 부담해야할 요금이 발생하기 때문에 상업적인 용도도 아닌 개인 프로젝트 규모에서는 섣불리 적용하기 어려운 입장이다. 그래서 교육과정 기간동안 AWS를 사용하는 요금을 지원받을 때만이라도 EC2와 RDS를 함께 사용하는 절차를 꼭 적용해보고 EC2에 직접 데이터베이스를 설치하여 사용하는 것과 무엇이 다른지 체험해봐야겠다.
Final..
이번 주는 Kubernates를 통해서 클러스터를 구성하여 클러스터의 구성요소들을 다뤄보았다. Kubeadam을 통해 마스터 노드와 워커 노드를 만들어 클러스터를 구축하였고, 파드(Pod), 레플리카셋(ReplicaSet), 디플로이먼트(Deployment), 서비스(Service), Ingress(인그레스), PV에 대해서 배우고 실습해보았다.
사실 짧은시간에 쿠버네티스의 개념적 구조부터 시작하여 내부 구성요소까지 이해하고 사용하는 것은 어렵다고 판단이 들었다. 오히려 개념적인 부분에서 이해가 안되는 상태로 각 구성요소를 들여다본들 잘 와닿지 않았던 것도 사실이다.
하지만 앞으로 Docker와 더불어 컨테이너를 다루는 기술에 관심을 두고 트래픽 분산화를 체험해보기 위해 쿠버네티스에 대해서는 꾸준히 공부하며 이해도를 높여가려고 한다.
그리고 AWS를 통해 EC2에 인스턴스와 RDS 데이터베이스를 만들어보고 EC2에 RDS 데이터베이스를 연결해보는 시간을 가졌다. EC2 인스턴스는 이전에 가끔 사용해보았기에 복습 차원에서 다시 배워보니 흥미롭고 재미있었다. 인스턴스를 구성하는데 있어 잘 몰랐던 설정이나 보안 규칙들에 대해서 짚고 넘어갈 수 있었다.
내가 만든 애플리케이션을 AWS 클라우드를 통해서 배포하거나, RDS를 통해 데이터베이스를 이용하는 과정은 잘 알아두고 써먹을 수 있도록 해야겠다고 다짐했다. 다음 주는 AWS에서 컨테이너를 개발하고 관리하는 교육과정을 쭉 진행할 예정인데, 모르는 부분은 꼭 복습하고 알게된 부분도 복습하는 시간을 가질 수 있도록 노력하자.
혹여 잘못된 내용이 있다면 지적해주시면 정정하도록 하겠습니다.게시물과 관련된 소스코드는 Github Repository에서 확인할 수 있습니다.
참고자료 출처
