
Intro
도태되지 말자.
나름대로 조금씩이라도 꾸준히 복습하거나 궁금한 것을 알아보는 등 공부하는 습관이 익숙해졌다. 개발자가 되기 위해서 공부할 것은 많기 때문에 조금만 게을러지면 어느 순간 감당하지 못할 정도의 압박감을 받고는 한다.
개발자가 되기 위해서 왜 공부를 게을리하면 안되는가? 라는 질문을 종종 스스로에게 던지는데, 나의 대답은 도태되지 않기 위해서라고 말할 수 있다. 사실 도태되지 않고 살아남으려면 경쟁력을 갖춰야 한다. 경쟁력을 갖추기 위해서는 공부를 통해서 스스로 학습하고 나만의 무기를 만드는 것이다.
물론 공부를 안한다고 채찍질을 하지는 않지만, 내가 부족함을 인지하고 더욱 성장하고 싶은 사람이라면 공부를 할 수 밖에 없다고 생각한다. 사실 이런 생각을 하면서도 꾸준히 공부하는 것이 쉽지는 않다. 하지만 이런 생각을 통해 한번, 두번이라도 책상에 앉을 수만 있다면 절반은 성공한 것이라고 생각한다.
아직 교육과정도 남아있고 프로젝트도 시작하지 않았지만 도태되지 않기 위해서 꾸준히 공부하고 있고 앞으로도 그럴 것이다. 앞으로 진행하게 될 수많은 협업 과정 속에서 누군가에게 더욱 경쟁력있는 동료가 되고 싶기 때문이다.
Day - 58
JPA를 사용할 때 따라오는 N+1 문제는 무엇일까?
최근 JPA를 사용하면서 분명 한 번의 Select 쿼리가 적용될 것이라 생각했지만 생각했던 것과 다르게 여러 번의 Select 쿼리가 적용되는 현상이 있었다. 먼저 이 문제를 간단하게 살펴보자. 먼저 연관관계가 맺어진 Board와 Member의 Entity는 다음과 같다.
Member.java
@Entity
public class Member extends BaseEntity {
@Id
private String email;
private String password;
private String name;
}Board.java
@ToString(exclude = "writer")
@Entity
public class Board extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
private String title;
private String content;
@ManyToOne(fetch = FetchType.LAZY)
private Member writer;
}엔티티의 속성을 보면 알 수 있듯이 Member와 Board는 1:N 관계가 맺어져 있다. 그래서 Board의 Writer는 Member의 PK 값인 email 속성이. FK로 설정되어있고, 지연로딩 옵션을 적용시켜 놓았다.
BoardRepositoryTest.java
@Test
@Transactional
public void getAllBoard() {
List<Board> list = boardRepository.findAll();
for (Board board : list) {
System.out.println(board.getWriter());
}
}이 상태에서 Board의 모든 데이터를 가져오는 단순한 findAll() 메소드를 통해 각 Board의 Writer 정보를 보기 위해 Member를 조회할 때마다 select 쿼리가 적용되버렸다.
Test Output
Hibernate:
select
b1_0.bno,
b1_0.content,
b1_0.created_at,
b1_0.title,
b1_0.updated_at,
b1_0.writer_email
from
board b1_0
Hibernate:
select
m1_0.email,
m1_0.created_at,
m1_0.name,
m1_0.password,
m1_0.updated_at
from
tbl_member m1_0
where
m1_0.email=?
Member(email=..., password=..., name=...)
Hibernate:
select
m1_0.email,
m1_0.created_at,
m1_0.name,
m1_0.password,
m1_0.updated_at
from
tbl_member m1_0
where
m1_0.email=?
Member(email=..., password=..., name=...)
...분명 List<Board> list = boardRepository.findAll(); 구문을 통해서 모든 Board의 정보를 List에 담아오기 때문에 FK로 등록된 writer 속성도 함께 조회하여 가져왔을 것이라 생각했다. 위 출력문을 보면 먼저 board 테이블에 조회 쿼리를 적용한 것을 볼 수 있다.
그런데, writer 속성은 @ManyToOne(fetch = FetchType.LAZY) 옵션을 통해 지연로딩이 적용되어 있기 때문에 writer 속성 정보를 함께 가져오지 않고, for문에서 board.getWriter() 할 때마다 Member에서 select 쿼리를 통해 Writer 정보를 가져오게 된다.
findAll() 메소드를 통해 Board 객체의 전부를 불러왔지만, 연관된 매핑 관계가 맺어진 Member 객체의 writer 속성 정보는 불러오지 않기 때문에, Member 객체의 writer 속성을 가져오는 쿼리를 별도로 생성하여 값을 가져와 결국 N개의 쿼리가 추가적으로 발생된다.
JPA의 N+1 문제란 무엇인가?
내가 닥친 상황을 해결하기 위해 여러 솔루션들을 찾아보니 JPA의 N+1 문제라고 한다. 사실 JPA를 공부하면서 N+1이라는 이야기에 대해서 종종 들었지만 어떤 문제인지에 대해서 잘 몰랐었다. 직접 N+1 문제를 겪어보니 확실하게 짚고 넘어가야 할 시점이 되었다.
N+1 문제는 조회 작업을 할 때 1개의 쿼리를 생각하고 설계를 했으나 N개의 조회쿼리가 추가적으로 발생하는 문제이다. 이는 연관 관계가 맺어진 객체 테이블의 데이터를 전부 조회하여 가져오는 것이 아니라, 해당하는 속성별로 N개의 조회 쿼리가 생성되기 때문에 때론 성능상 비효율적일 수 있다.
그래서 N개의 쿼리를 적용하는 것이 아니라 1번의 쿼리를 통해 딱 1번만 데이터를 가져오기 위해선 어떻게 해야할까?
N+1 문제의 해결책은?
N+1 문제를 해결할 수 있는 방법으로 패치 조인(Fetch join)과 엔티티 그래프(EntityGraph) 2가지 방법을 살펴보려 한다.
Fetch join(패치 조인)
fetch join이란, JPQL에서 성능 최적화를 위해 제공하는 기술이다. SQL의 join과 비슷하지만 JPQL에서 최적화를 위해 제공하는 join이다. fetch join은 JPQL을 통해 DB에서 데이터를 가져올 때 처음부터 연관된 객체(Entity)의 정보까지 함께 가져올 수 있다.
Fetch join 적용하기
그렇다면 위의 코드에서 fetch join을 적용해보자. @Query 어노테이션을 사용해야 하기 때문에 JPA에서 제공하는 기본 메소드가 아닌 별도의 메소드를 만들어야 한다. 먼저 findAllFetchJoin()이라는 메소드를 만들어보자.
BoardRepository.java
@Query("select b from Board b join fetch b.writer")
List<Board> findAllFetchJoin();Board 객체에서 Member 객체와 연관이 있는 작성자 속성인 writer 속성을 fetch join하여 가져오는 구문을 작성하였다.
BoardRepositoryTest.java
@Test
public void getAllBoard() {
List<Board> list = boardRepository.findAllFetchJoin();
for (Board board : list) {
System.out.println(board.getWriter());
}
}테스트 코드에도 findAllFetchJoin 메소드로 수정하여 테스트를 실행해보았다.
Test Output
Hibernate:
select
b1_0.bno,
b1_0.content,
b1_0.created_at,
b1_0.title,
b1_0.updated_at,
w1_0.email,
w1_0.created_at,
w1_0.name,
w1_0.password,
w1_0.updated_at
from
board b1_0
join
tbl_member w1_0
on w1_0.email=b1_0.writer_email
Member(email=..., password=..., name=...)
Member(email=..., password=..., name=...)
Member(email=..., password=..., name=...)
Member(email=..., password=..., name=...)
Member(email=..., password=..., name=...)인텔리제이의 콘솔을 확인해보니 select 쿼리에 join 구문이 추가되어 한번만 적용되었고 이후에는 N+1개의 조회쿼리가 적용되는 것이 아니라 함께 가져온 Member 객체의 정보를 출력하는 것을 알 수 있었다.
EntityGraph(엔티티 그래프)
그런데, fetch join을 사용하는 것은 일일이 메소드에 @Query 어노테이션과 함께 JPQL 구문을 작성해야 하기 때문에 번거로울 수 있다. 그리고 사실 Jpa에서 사용할 수 있는 기본 메소드를 활용하지 못한다는 것이 생각보다 크게 아쉽다고 느껴졌다.
Spring Data JPA에서는 fetch join 대신에 @EntityGraph 어노테이션을 통해 N+1 문제를 더 편리하게 해결할 수 있다.
@EntityGraph 어노테이션은 조회 쿼리를 수행할 때 연관 관계가 맺어진 객체의 속성을 지정하면 지연로딩이 아닌 즉시로딩을 통해 데이터를 가져온다.
@EntityGraph어노테이션을 통한 fetch join에 대한 자세한 내용은 전 회차 회고록인 12번째 회고록에서 먼저 다루었기에@EntityGraph어노테이션에 대한 개념 자체는 가볍게 보고 넘어간다.
EntityGraph 적용하기
이번엔 fetch join 대신에 @EntityGraph 어노테이션을 적용해보자.
앞에서 fetch join을 위해 별도로 만든 findAllFetchJoin() 메소드가 아닌 JPA에서 제공하는 기본 메소드인 findAll() 메소드를 사용해보자.
BoardReposiotry.java
@EntityGraph(attributePaths = {"writer"})
List<Board> findAll();@EntityGraph 어노테이션의 attributePaths 속성에 Member 객체의 writer 속성을 지정해준다.
BoardRepositoryTest.java
@Test
public void getAllBoard() {
List<Board> list = boardRepository.findAll();
for (Board board : list) {
System.out.println(board.getWriter());
}
}그리고 바로 테스트를 진행해보자.
Test Output
Hibernate:
select
b1_0.bno,
b1_0.content,
b1_0.created_at,
b1_0.title,
b1_0.updated_at,
w1_0.email,
w1_0.created_at,
w1_0.name,
w1_0.password,
w1_0.updated_at
from
board b1_0
left join
tbl_member w1_0
on w1_0.email=b1_0.writer_email
Member(email=..., password=..., name=...)
Member(email=..., password=..., name=...)
Member(email=..., password=..., name=...)
Member(email=..., password=..., name=...)
Member(email=..., password=..., name=...)fetch join을 적용한 테스트와 동일하게 단 한번의 조회쿼리만을 적용하는 것을 볼 수 있다.
fetch join과 @EntityGraph의 쿼리 내용
Fetch Join
Hibernate:
select
b1_0.bno,
b1_0.content,
b1_0.created_at,
b1_0.title,
b1_0.updated_at,
w1_0.email,
w1_0.created_at,
w1_0.name,
w1_0.password,
w1_0.updated_at
from
board b1_0
join
tbl_member w1_0
on w1_0.email=b1_0.writer_email@EntityGraph
Hibernate:
select
b1_0.bno,
b1_0.content,
b1_0.created_at,
b1_0.title,
b1_0.updated_at,
w1_0.email,
w1_0.created_at,
w1_0.name,
w1_0.password,
w1_0.updated_at
from
board b1_0
left join
tbl_member w1_0
on w1_0.email=b1_0.writer_email두 가지 방식을 통한 조회 쿼리를 살펴보니 Fetch Join은 Inner Join방식으로, @EntityGraph 어노테이션은 Outer Join 방식으로 적용된다는 차이점이 있음을 유의해야 할 것 같다.
이렇게 JPA에서의 N+1 문제에 대해서 알아보고 어떻게 해결할 수 있을지 적용해보는 시간을 가졌다. 다만 꼭 지연로딩을 지양하고 join을 무턱대고 남발하는 것도 좋지 않은 것으로 보인다. 조회쿼리 한번에 모든 정보를 가져올 것이냐, 그때그때 필요할 때 새로운 조회쿼리를 통해 가져올 것이냐라는 이슈에 대한 결론을 당장 정할 수 없다고 느꼈다. 결국 프로젝트를 진행하면서 그에 맞는 비즈니스 로직에 맞추어 결정해야 한다고 생각한다.
Day - 59
Service와 ServiceImpl은 1:1로 설계해야 하는가?
여태까지 프로젝트를 꾸려오면서 Service를 구성할 때 인터페이스와 인터페이스를 구현할 구현체 클래스를 만들어서 사용했었다.
예를 든다면 ReviewService 라는 서비스 인터페이스가 있다고 했을 때, 해당 인터페이스에서 여러 추상 메소드를 선언해두고 이를 구현할 ReviewServiceImpl 구현체 클래스를 만들어서 사용하게 된다.
본디 Java에서 이러한 인터페이스를 사용하는 이유는 객체지향의 특징 중 하나인 다형성과 객체지향 원칙 중 하나인 OCP 원칙을 지키기 위함이다.
다형성이란 하나의 자료형에 여러가지 객체를 대입하여 다양한 결과를 얻어내는 특징이다.
OCP 원칙(Open Closed Principle)이란 개방, 폐쇄 원칙이라고 하며 '소프트웨어 개체(클래스, 모듈, 함수 등)는 확장에 대해 열려 있어야 하고, 수정에 대해서는 닫혀 있어야 한다.'는 프로그래밍 원칙이다.
그런데 이러한 인터페이스와 구현체를 배우고 실습하면서 인터페이스와 구현체를 MemberService 인터페이스에는 MemberServiceImpl, PostsService 인터페이스에는 PostsServiceImpl 등과 같이 1:1 관계로 만들기만 했었지, 정작 1:N 관계로 만들어보지는 않았다.
이렇게 인터페이스와 구현체 클래스를 1:1 관계로만 만들어 사용하는 것이 과연 바람직한 것일까 라는 의문이 들었다.
인터페이스와 구현체 클래스와 같은 관습적인 추상화에 대해서
인터페이스와 구현체 클래스를 분리하여 구성했을 때 얻게되는 이점은 구현체 클래스를 변경하거나 확장하더라도 이를 호출하는 클라이언트 코드에는 영향을 주지 않는다는 점이다.
리뷰와 관련된 Service를 통해 예를 들어보자.
ReviewService.java
public interface ReviewService {
void addPoint();
}ReviewServiceImpl.java
@RequiredArgsConstructor
@Service
public class ReviewServiceImpl implements ReviewService{
@Override
public void addPoint() {
System.out.println("리뷰를 작성하여 포인트가 1점 추가됩니다.");
}
}ReviewService라는 인터페이스에서 addPoint라는 추상 메소드를 선언해두었고 이를 ReviewServiceImpl 구현체 클래스에서 구현하였다.
ReviewController.java
@RestController
@RequiredArgsConstructor
public class ReviewController {
private final ReviewService reviewService;
@GetMapping("point")
public void addPoint() {
System.out.println("리뷰 작성 요청을 전달받았습니다.");
}
}그런데 위 코드를 보면 알 수 있듯이 컨트롤러에서는 ReviewService 인터페이스 타입의 의존성을 주입받고 있다. 물론 구현체 클래스인 ReviewServiceImpl의 의존성을 주입받아도 무방하지만, 인터페이스의 의존성을 주입받아 사용한다면 의도했던대로 OCP 원칙을 지킬 수 있게 된다.
그렇다면 여기서 새로운 구현체 클래스를 만들어보자.
ReviewServiceImplSub.java
@RequiredArgsConstructor
@Service
public class ReviewServiceImplSub implements ReviewService{
@Override
public void addPoint() {
System.out.println("리뷰를 작성하여 포인트가 3점 추가됩니다.");
}
}ReviewServiceImplSub 구현체 클래스는 ReviewServiceImpl과 동일하게 ReviewService 인터페이스의 addPoint 메소드를 구현하고 있다. ReviewServiceImpl 구현체 클래스의 @Service 어노테이션을 제거한다면 ReviewServiceImplSub 구현체 클래스가 스프링 빈으로 등록되어 결과적으로는 ReviewService는 ReviewServiceImplSub가 등록되게 된다.
그래서 컨트롤러에서는 ReviewService 인터페이스를 어떤 구현체 클래스로 주입했는지 알 수가 없다. 즉, ReviewService의 구현체 클래스가 변경되거나 확장되더라도 컨트롤러(클라이언트) 코드는 손 댈 필요가 없다는 뜻이다.
현재 정의된 구현체 클래스를 사용하다가 언제 어디서 어떻게 정책이 변경되어 구현체 클래스를 변경해야 할 상황이 있을 수도 있기 때문에 구현체 클래스간 @Service 어노테이션만 바꿔서 사용해주면 변경된 정책을 손쉽게 적용시킬 수 있게 된다.
만약 여러개의 구현체 클래스가 있고
@Service어노테이션은 하나의 구현체 클래스에만 붙어있어야 한다. 여러 군데 붙어있다면 스프링 빈 충돌 문제가 발생한다.
인터페이스와 구현체 클래스 1:1 관계 이대로 괜찮은가?
다시 처음으로 돌아와서 인터페이스와 구현체 클래스가 1:1 관계로 구성하는 게 바람직한 것인지에 대한 생각을 정리해보려 한다.
사실 하나의 인터페이스에 대한 구현체 클래스가 2개 이상이 아니라고 한다면 굳이 인터페이스가 필요 없을 수도 있겠다라고 생각도 들었다. 그냥 인터페이스 없이 Service 로직만 두면 깔끔하지 않을까?
그럼에도 불구하고 나는 인터페이스와 구현체 클래스를 사용할 것 같다. 그 이유는 다음과 같다.
가장 큰 이유는 먼저 유동적인 정책 변경에 쉽게 대응하기 위함이다. 서비스가 커지고 확장되어감에 따라서 구현체 클래스는 변경되거나 확장될 가능성이 크다고 생각한다. 또한, 짧은 경험이지만 여태까지 개발하면서 도중에 정책이 변경되는 상황은 자주 있었다. 그래서 "정책 변경점에 대비해서 나쁠 건 없다." 라고 느끼게 되었고 주어진 비즈니스 정책에 맞게 인터페이스와 구현체 클래스를 구성하자라고 생각이 들었다.
두번째 이유는 동료 개발자와 협업의 편리성을 증진시키기 위함이다. 프로젝트를 구축할 때 인터페이스의 작성과 실제 구현의 역할을 나눈다면 설계한 인터페이스에 맞춰 개발자가 좀 더 편하고 쉽게 개발할 수 있다고 느꼈기 때문이다.
Day - 60
@Embedded, @Embeddable 어노테이션을 통한 Entity의 비슷한 속성들을 그룹화하기
JPA를 사용하면서 실제 테이블과 연관 관계를 지을 Entity들을 설계해보면서 다양한 속성들을 정의해보았다. 하나의 Entity에 비슷한 성격의 속성들이 여러 개 존재한다면 이들을 더 보기좋게 만들 수 없을까? 라는 생각이 들었다.
그래서 찾아보니 @Embedded, @Embeddable 어노테이션을 이용한다면 내가 의도한대로 비슷한 성격의 속성들을 그룹화할 수 있다고 한다.
간단한 회원가입을 예시로 들어보자.
User.java
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long userId;
private String phone;
private String firstName;
private String lastName;
private String address;
private String detailAddress;
}회원과 관련된 User라는 Entity를 작성해보았다. User에 선언된 속성들을 잘 보면 firstName과 lastName을 묶고, address와 detailAddress를 묶는 것이 더 나을 것으로 보인다.
이 때, 이렇게 연관된 속성들을 객체로 묶어서 관리할 수 있는 것이 @Embedded과 @Embeddable 어노테이션이다.
@Embedded 어노테이션은 객체 타입을 사용하는 곳에 명시하고 @Embeddable 어노테이션은 만든 객체 타입을 선언하는 곳에 명시하면 된다.
위의 User Entity에 firstName과 lastName을 userName으로 묶고, address와 detailAddress를 address로 묶어보자.
UserName.java
@Embeddable
public class UserName {
private String firstName;
private String lastName;
}Address.java
@Embeddable
public class Address {
private String address;
private String detailAddress;
}UserName과 Address 객체는 User Entity에서 사용하는 속성들을 묶는 클래스이기 때문에 @Embeddable 어노테이션을 붙여주면 된다.
User.java
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long userId;
private String phone;
@Embedded
private UserName userName;
@Embedded
private Address address;
}마지막으로 User Entity에서 firstName, lastName을 대신하여 UserName 객체를, address, detailAddress를 대신하여 Address 객체를 속성으로 선언해주고 @Embedded 어노테이션을 붙여주면 된다.
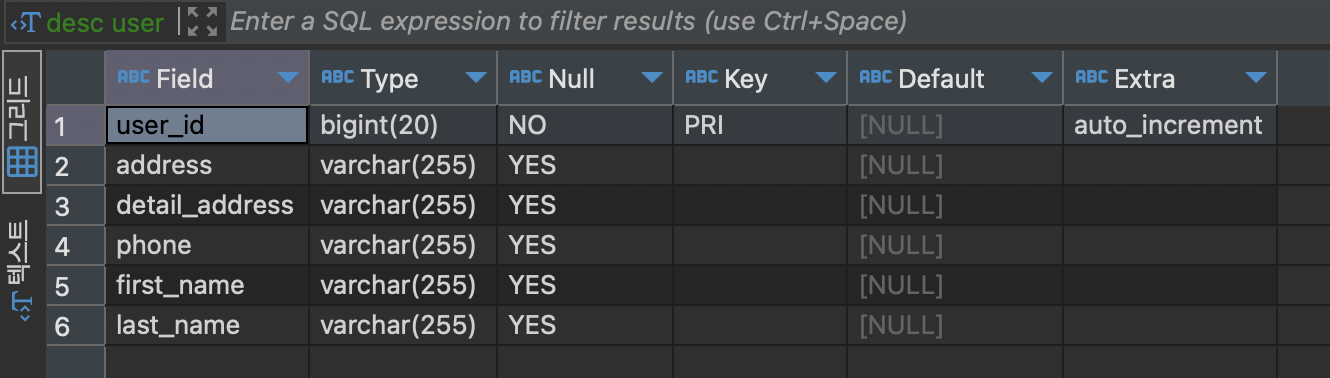
이대로 서버를 실행하여 JPA가 만들어준 user 테이블을 확인해보면 위와 같이 UserName을 통해서 firstName과 lastName 컬럼을, Address를 통해서 address와 detailAddress 컬럼이 생성된 것을 확인할 수 있었다.
이처럼 @Embedded과 @Embeddable 어노테이션은 실제 Entity를 설계할 때 유용하게 사용할 수 있다고 느꼈다. 임베디드 타입을 사용함으로 단순히 컬럼의 중복을 줄인다는 것보다는 상세한 데이터들을 관련있는 객체의 타입으로 묶어서 응집력을 높이고 좀 더 객체지향적으로 설계할 수 있다는 것이 엄청난 장점이라고 생각이 들었다.
Final..
설 명절을 잘 보내고 와서 수, 목, 금 3일간의 교육을 마쳤다. 푹 쉬다가 다시 공부를 시작하니 피로감이 조금 몰려왔다. 그래도 스프링 교육을 마치고 Linux와 Docker를 배우니 기분전환이 된 것 같다.
스프링 시큐리티를 마치고 JWT 실습도 진행했으면 좋았지만 교육 일정상 진행하지 못하게 되었다. 별도로 혼자서든 사이드 프로젝트든 꼭 진행해야겠다.
다음주 부터는 Docker와 Kubernates, AWS와 같은 클라우드 환경에 대해서 배우게 되는데 이러한 클라우드 환경에 대해서도 궁금한 것이 참 많다. 시간을 내서 어느정도 알아보고 어떤 용도로 사용되는지, 왜 클라우드를 사용해야 하는지, 클라우드 환경을 통해 챙길 수 있는 이점들에 대해서 고민해봐야겠다.
혹여 잘못된 내용이 있다면 지적해주시면 정정하도록 하겠습니다.게시물과 관련된 소스코드는 Github Repository에서 확인할 수 있습니다.
참고자료 출처
